一、Docker网络概述
Docker作为目前最火的轻量级容器技术,牛逼的功能,如Docker的镜像管理,不足的地方网络方面。Docker本身的技术依赖于Linux内核虚拟化技术的发展。所以Docker对Linux内核的特性有很强的依赖。
二、Docker网络原理
不同的网络名称空间内,是一个相对独立的、封闭的网络名称空间。如果想实现不同的网络名称空间之间相互访问,需要借助第三方设备来实现:Veth设备对、网桥
1.veth设备对
# veth设备对:相当于用一个网线连接两个不同的网络名称空间中,从而实现网络互通。
veth设备对的缺陷:一对veth设备对只能够连接两个命名空间,假设有100个命名空间需要网络互通,需要5050对veth设备对。所以,veth设备对在面对对个网络命名空间之间的访问,就显得非常冗余。
2.网桥
# 网桥:在不同的网络名称空间之外建立一个公用的交换机,用来转发不同命名空间内的网络请求。
网桥与veth设备对相比:veth设备对性能更好。
3.linux网络名称空间
linux中存在不同的命名空间,不同的命名空间之间互相不影响,每一个命名空间中都有自己的独立网络名称空间,每一个独立的网络名称空间之间也是相互隔离(网络是不互通)
#1.要实现容器与容器、容器与宿主主机之间网络互通,需要借助第三方网络传输介质
1)veth设备对:容器与宿主主机之间的网络互通
缺陷:只能够一对一,如果大量容器之间需要互联互通,需要维护大量的veth设备对
1、大量的veth设备对会占用大量的系统资源
2、大量veth设备对不易维护
3、只能一对一
优点:
1、veth设备对性能很好
2)网桥:
网桥是基于二层网络转发实现容器间互联互通的网络互联解决方案。
网络互通的基本条件:必须在同一个网络空间内,才能够实现网络互通
优点:
1、可以为多个容器提供统一的网络
缺点:
1、二层网络转发性能没有veth设备对好
三、Docker网络基础
其中Docker使用到的与Linux网络有关的技术分别有:网络名称空间、Veth、Iptables、网桥、路由。
1.网络名称空间
为了支持网络协议栈的多个实例,Linux在网络协议栈中引入了网络名称空间(Network Namespace),这些独立的协议栈被隔离到不同的命名空间中。处于不同的命名空间的网络协议栈是完全隔离的,彼此之间无法进行网络通信,就好像两个“平行宇宙”。通过这种对网络资源的隔离,就能在一个宿主机上虚拟多个不同的网络环境,而Docker正是利用这种网络名称空间的特性,实现了不同容器之间的网络隔离。在Linux的网络命名空间内可以有自己独立的Iptables来转发、NAT及IP包过滤等功能。
Linux的网络协议栈是十分复杂的,为了支持独立的协议栈,相关的这些全局变量都必须修改为协议栈私有。最好的办法就是让这些全局变量成为一个Net Namespace变量的成员,然后为了协议栈的函数调用加入一个Namespace参数。这就是Linux网络名称空间的核心。所以的网络设备都只能属于一个网络名称空间。当然,通常的物理网络设备只能关联到root这个命名空间中。虚拟网络设备则可以被创建并关联到一个给定的命名空间中,而且可以在这些名称空间之间移动。
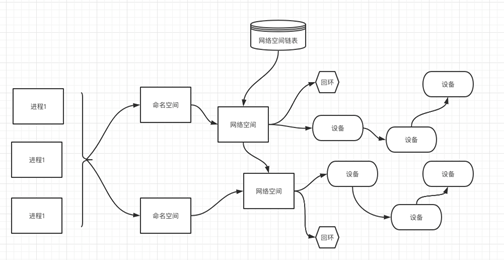
2.创建网络名称空间
[root@m01 ~]# ip netns add test01
[root@m01 ~]# ip netns add test02
[root@m01 ~]# ip netns list
test02
test01
3.Veth设备
引入Veth设备对是为了在不同的网络名称空间之间进行通信,利用它可以直接将两个网络名称空间链接起来。由于要连接的两个网络命名空间,所以Veth设备是成对出现的,很像一对以太网卡,并且中间有一根直连的网线。既然是一对网卡,那么我们将其中一端称为另一端的peer。在Veth设备的一端发送数据时,它会将数据直接发送到另一端,并触发另一端的接收操作。
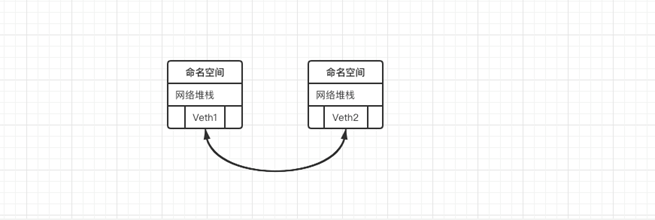
4.Veth设备操作
#1.创建Veth设备对
[root@m01 ~]# ip link add veth type veth peer name veth001
[root@m01 ~]# ip link show
23: veth001@veth: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 4e:74:6b:02:33:20 brd ff:ff:ff:ff:ff:ff
24: veth@veth001: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether e2:30:7e:82:12:60 brd ff:ff:ff:ff:ff:ff
ps:生成了两个veth设备, 互为对方的peer。
#2.绑定命名空间
[root@m01 ~]# ip link set veth001 netns test01
[root@m01 ~]# ip link show | grep veth
22: vethe989641@if21: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
24: veth@if23: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
#3.已经查看不到veth001,当我们进入test01命名空间之后,就可以查看到
[root@m01 ~]# ip netns exec test01 bash
[root@m01 ~]# ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
23: veth001@if24: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 4e:74:6b:02:33:20 brd ff:ff:ff:ff:ff:ff link-netnsid
#4.将Veth分配IP
[root@m01 ~]# ip netns exec test01 ip addr add 172.16.0.111/20 dev veth001 #设置IP
[root@m01 ~]# ip netns exec test01 ip link set dev veth001 up #绑定
[root@m01 ~]# ip netns exec test01 ip a #查看
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
23: veth001@if24: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN group default qlen 1000
link/ether 4e:74:6b:02:33:20 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.16.0.111/20 scope global veth001
valid_lft forever preferred_lft forever
#5.查看对端Veth设备
[root@m01 ~]# ip netns exec test01 ethtool -S veth001
NIC statistics:
peer_ifindex: 24
[root@m01 ~]# ip a | grep 24
23: veth001@if24: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN group default qlen 1000
#6.为对端Veth设备设置IP
[root@m01 ~]# exit
exit
[root@m01 ~]# ip link set veth netns test02
[root@m01 ~]# ip netns exec test02 bash
[root@m01 ~]# ip netns exec test02 ip addr add 172.16.0.112/20 dev veth
[root@m01 ~]# ip netns exec test02 ip link set dev veth up
#7.查看是否能ping通
[root@m01 ~]# ping 172.16.0.111
PING 172.16.0.111 (172.16.0.111) 56(84) bytes of data.
64 bytes from 172.16.0.111: icmp_seq=1 ttl=64 time=0.067 ms
64 bytes from 172.16.0.111: icmp_seq=2 ttl=64 time=0.045 ms
64 bytes from 172.16.0.111: icmp_seq=3 ttl=64 time=0.059 ms
64 bytes from 172.16.0.111: icmp_seq=4 ttl=64 time=0.062 ms
--- 172.16.0.111 ping statistics ---
8 packets transmitted, 8 received, 0% packet loss, time 7001ms
rtt min/avg/max/mdev = 0.041/0.060/0.110/0.021 ms
5.网桥
Linux 可以支持多个不同的网络,它们之间能够相互通信,就需要一个网桥。 网桥是二层的虚拟网络设备,它是把若干个网络接口“连接”起来,从而报文能够互相转发。网桥能够解析收发的报文,读取目标 MAC 地址的信息,和自己记录的 MAC 表结合,来决定报文的转发目标网口。
网桥设备 brO 绑定了 eth0、 eth1 。对于网络协议械的上层来说,只看得到 brO 。因为桥接是在数据链路层实现的 ,上层不需要关心桥接的细节,于是协议枝上层需要发送的报文被送到 brO ,网桥设备的处理代码判断报文该被转发到 ethO 还是 ethl ,或者两者皆转发。反过来,从 ethO 或从 ethl 接收到的报文被提交给网桥的处理代码,在这里会判断报文应该被转发、丢弃还是提交到协议枝上层。 而有时 ethl 也可能会作为报文的源地址或目的地址 直接参与报文的发送与接收,从而绕过网桥。
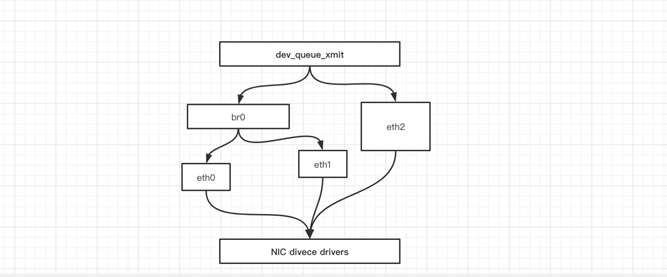
6.Iptables
我们知道, Linux 络协议樵非常高效,同时比较复杂 如果我们希望在数据的处理过程中对关心的数据进行一些操作该怎么做呢? Linux 提供了一套机制来为用户实现自定义的数据包处理过程。
在Linux网络协议棋中有一组回调函数挂接点,通过这些挂接点挂接的钩子函数可以在Linux 网络棋处理数据包的过程中对数据包进行 些操作,例如过滤、修改、丢弃等 整个挂接点技术叫作 Netfilter lptables
Netfilter 负责在内核中执行各种挂接的规则,运行在内核模式中:而 lptables 是在用户模式下运行的进程,负责协助维护内核中 Netfilter 的各种规则表 通过 者的配合来实现整个 Linux网络协议战中灵活的数据包处理机制。
7. 总结
| 设备 |
作用总结 |
| network namespace |
主要提供了关于网络资源的隔离,包括网络设备、IPv4和IPv6协议栈、IP路由表、防火墙、/proc/net目录、/sys/class/net目录、端口(socket)等。 |
| linux Bridge |
功能相当于物理交换机,为连在其上的设备(容器)转发数据帧。如docker0网桥。 |
| iptables |
主要为容器提供NAT以及容器网络安全。 |
| veth pair |
两个虚拟网卡组成的数据通道。在Docker中,用于连接Docker容器和Linux Bridge。一端在容器中作为eth0网卡,另一端在Linux Bridge中作为网桥的一个端口。 |
四、Docker默认网络
1.Docker网络模式概述
Docker使用Linux桥接的方式,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信。
Docker网桥是宿主机虚拟出来的,并不是真实存在的网络设备,外部网络是无法寻址到的,这也意味着外部网络无法通过直接Container-IP访问到容器。如果容器希望外部访问能够访问到,可以通过映射容器端口到宿主主机(端口映射),即docker run创建容器时候通过 -p 或 -P 参数来启用,访问容器的时候就通过[宿主机IP]:[容器端口]访问容器。
2.Docker网络模式工作方式
Docker自身的4种网络工作方式,和一些自定义网络模式.
Docker容器与容器之间网络相互隔离。
安装Docker时,它会自动创建三个网络,bridge(创建容器默认连接到此网络)、 none 、host.
你可以使用以下docker network ls命令列出这些网络:
[root@m01 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
daa11493364f bridge bridge local
fc5d4a69c90d host host local
16b8d6c8be22 none null local
Docker内置这三个网络,运行容器时,你可以使用该--network标志来指定容器应连接到哪些网络。
该bridge网络代表docker0所有Docker安装中存在的网络。除非你使用该docker run --network=<NETWORK>选项指定,否则Docker守护程序默认将容器连接到此网络。
我们在使用docker run创建Docker容器时,可以用 --net 选项指定容器的网络模式,Docker可以有以下4种网络模式:
host模式:使用 --net=host 指定。
none模式:使用 --net=none 指定。
bridge模式:使用 --net=bridge 指定,默认设置。
container模式:使用 --net=container:NAME_or_ID 指定。
| Docker网络模型 |
配置 |
说明 |
| host模式 |
–-network=host |
容器和宿主机共享Network namespace。 |
| containe模式 |
--network=container:ID |
容器和另外一个容器共享Network namespace。 kubernetes中的pod就是多个容器共享一个Network namespace。 |
| none模式 |
--network=none |
容器有独立的Network namespace,但并没有对其进行任何网络设置,如分配veth pair 和网桥连接,配置IP等。 |
| bridge模式 |
--network=bridge |
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。(默认为该模式) |
五、Docker默认网络详述
1.Host 网络方式
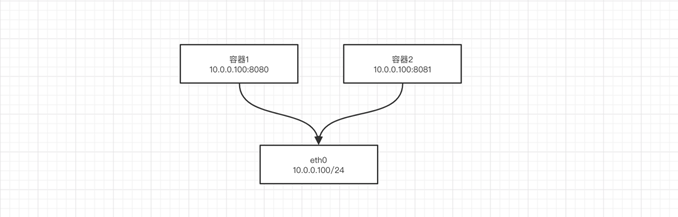
相当于Vmware中的桥接模式,与宿主机在同一个网络中,但没有独立IP地址。众所周知,Docker使用了Linux的Namespaces技术来进行资源隔离,如PID Namespace隔离进程,Mount Namespace隔离文件系统,Network Namespace隔离网络等。一个Network Namespace提供了一份独立的网络环境,包括网卡、路由、Iptable规则等都与其他的Network Namespace隔离。一个Docker容器一般会分配一个独立的Network Namespace。但如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。
#解释:
host模式主要用于跟宿主主机相连,此时docker容器不会虚拟出自己的网卡。
#优点:
- 1、共享宿主主机网络,无需再做网络转发
- 2、性能比较好
#缺点:
- 1、隔离性不强
- 2、容易跟宿主主机服务之间起冲突
例如,我们在10.0.0.61/24的机器上用host模式启动一个含有nginx应用的Docker容器,监听tcp80端口。
# 运行容器;
[root@m01 ~]# docker run --name=nginx_host --net=host -p 80:80 -d nginx
WARNING: Published ports are discarded when using host network mode
c47d062687104ac58325a255185c216df9390ab0ad32dc18af61659ff0d88e48
# 查看容器;
[root@m01 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c47d06268710 nginx "/docker-entrypoint.…" 11 seconds ago Up 10 seconds nginx_host
当我们在容器中执行任何类似ifconfig命令查看网络环境时,看到的都是宿主机上的信息。而外界访问容器中的应用,则直接使用10.0.0.61/24即可,不用任何NAT转换,就如直接跑在宿主机中一样。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
[root@m01 ~]# netstat -nplt | grep nginx
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 63118/nginx: master
tcp6 0 0 :::80 :::* LISTEN 63118/nginx: master
2. Container网络方式
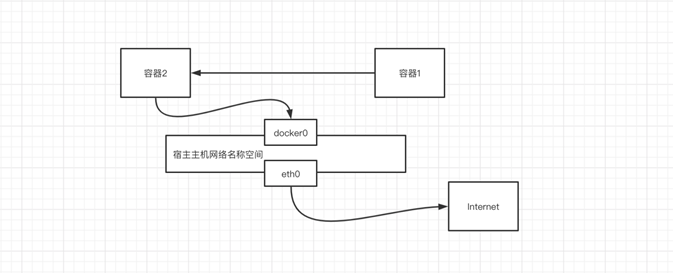
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
#解释:一个容器将网络共享给另外一个容器使用(两个容器之间网络其实是一个网络)
[root@m01 ~]# docker run -itd --name test01 busybox
Unable to find image 'busybox:latest' locally
latest: Pulling from library/busybox
d60bca25ef07: Pull complete
Digest: sha256:caf2e0529ee842cfa1950a1d8b15b120e884288d507774dc6751bc3861aa4b35
Status: Downloaded newer image for busybox:latest
a0ccfa2177d0b4118ef1b42a58b71326f0a13a6f501e9a7a9c80579cc42c7499
[root@m01 ~]# docker run -itd --name test02 --network "container:test01" busybox
b20a68e25b4d3b0946f0d037ed5df8308ee0c6ed911d402db61b4eb680c01ae9
[root@m01 ~]# docker exec -it test02 sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:06
inet addr:172.17.0.6 Bcast:172.17.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:656 (656.0 B) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # exit
[root@m01 ~]# docker exec -it test01 sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:06
inet addr:172.17.0.6 Bcast:172.17.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:8 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:656 (656.0 B) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ #
3.None 网络方式
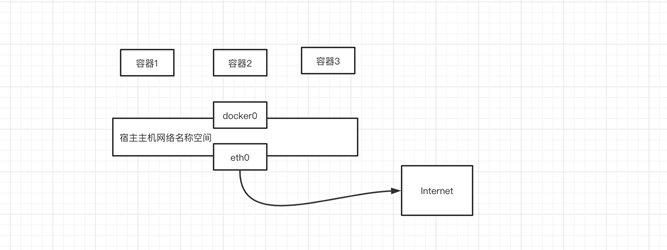
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。
这种网络模式下容器只有lo回环网络,没有其他网卡。none模式可以在容器创建时通过--network=none来指定。这种类型的网络没有办法联网,封闭的网络能很好的保证容器的安全性。
#解释:
none模式只为容器提供一个lo回环网络,外界是无法与容器进行互联互通。
#优点:
安全
#缺点:
无法与外界进行网络互通
[root@m01 ~]# docker run -itd --name test03 --network=none busybox
aa1334718dd0d0ecda5ae5b08afde6dab34883d8933ce5ef7504f9591f49caa5
[root@m01 ~]# docker exec -it test03 sh
/ # ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ #
4.Bridge 网络方式
相当于Vmware中的Nat模式,容器使用独立network Namespace,并连接到docker0虚拟网卡(默认模式)。通过docker0网桥以及Iptables nat表配置与宿主机通信;bridge模式是Docker默认的网络设置,此模式会为每一个容器分配Network Namespace、设置IP等,并将一个主机上的Docker容器连接到一个虚拟网桥上。
#实现原理:
通过一个虚拟网桥,建立一个统一的网络名称空间,依赖于docker0网桥
#使用及使用场景
一般使用在多个容器之间互联互通
#使用特点
多个容器之间互联互通
为容器提供一个统一的网络环境
六、Docker默认网络-Bridge模式
1.Bridge模式的拓扑
当Docker server启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。接下来就要为容器分配IP了,Docker会从RFC1918所定义的私有IP网段中,选择一个和宿主机不同的IP地址和子网分配给docker0,连接到docker0的容器就从这个子网中选择一个未占用的IP使用。如一般Docker会使用172.17.0.0/16这个网段,并将172.17.0.1/16分配给docker0网桥(在主机上使用ifconfig命令是可以看到docker0的,可以认为它是网桥的管理接口,在宿主机上作为一块虚拟网卡使用)。单机环境下的网络拓扑如下,主机地址为10.10.0.186/24。
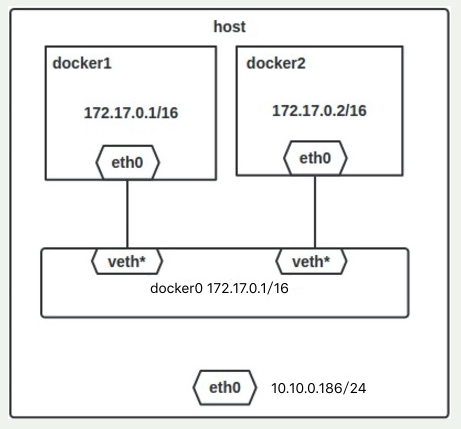
2.Docker:网络模式详解
Docker完成以上网络配置的过程大致是这样的:
1. 在主机上创建一对虚拟网卡veth pair设备。veth设备总是成对出现的,它们组成了一个数据的通道,数据从一个设备进入,就会从另一个设备出来。因此,veth设备常用来连接两个网络设备。
2. Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0。另一端放在主机中,以veth65f9这样类似的名字命名,并将这个网络设备加入到docker0网桥中,可以通过brctl show命令查看。
[root@m01 ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02425f21c208 no
3.从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。
bridge模式是docker的默认网络模式,不写--net参数,就是bridge模式。使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。
# 运行容器;
[root@m01 ~]# docker run --name=nginx_bridge --net=bridge -p 80:80 -d nginx
41d2854d3942e231103ca398b7b2a3dace6f90f8da6b3da16b81451e0c6593f2
# 查看容器;
[root@m01 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
41d2854d3942 nginx "/docker-entrypoint.…" 2 minutes ago Up 2 minutes 0.0.0.0:80->80/tcp nginx_bridge
# 查看容器网络;
[root@m01 ~]# docker inspect 41d2854d3942
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "daa11493364ff5445c7a324f00247902ad38fb067e45ebd2f0b595cbd4ed7034",
"EndpointID": "f2f216ed8e717637151e8b614d601cbec099783bfe56afa7aa5c23797b72ed53",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:02",
"DriverOpts": null
}
}
[root@m01 ~]# docker network inspect bridge
[
{
"Name": "bridge",
"Id": "daa11493364ff5445c7a324f00247902ad38fb067e45ebd2f0b595cbd4ed7034",
"Created": "2021-01-11T19:35:01.153832492+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"41d2854d3942e231103ca398b7b2a3dace6f90f8da6b3da16b81451e0c6593f2": {
"Name": "nginx_bridge",
"EndpointID": "f2f216ed8e717637151e8b614d601cbec099783bfe56afa7aa5c23797b72ed53",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
]
3.bridge模式下容器的通信
在bridge模式下,连在同一网桥上的容器可以相互通信。
(若出于安全考虑,也可以禁止它们之间通信,方法是在DOCKER_OPTS变量中设置–icc=false,这样只有使用–link才能使两个容器通信)。
Docker可以开启容器间通信(意味着默认配置--icc=true),也就是说,宿主机上的所有容器可以不受任何限制地相互通信,这可能导致拒绝服务攻击。进一步地,Docker可以通过--ip_forward和--iptables两个选项控制容器间、容器和外部世界的通信。
容器也可以与外部通信,我们看一下主机上的Iptable规则,可以看到这么一条
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
这条规则会将源地址为172.17.0.0/16的包(也就是从Docker容器产生的包),并且不是从docker0网卡发出的,进行源地址转换,转换成主机网卡的地址。这么说可能不太好理解,举一个例子说明一下。假设主机有一块网卡为eth0,IP地址为10.10.101.105/24,网关为10.10.101.254。从主机上一个IP为172.17.0.1/16的容器中ping百度(180.76.3.151)。IP包首先从容器发往自己的默认网关docker0,包到达docker0后,也就到达了主机上。然后会查询主机的路由表,发现包应该从主机的eth0发往主机的网关10.10.105.254/24。接着包会转发给eth0,并从eth0发出去(主机的ip_forward转发应该已经打开)。这时候,上面的Iptable规则就会起作用,对包做SNAT转换,将源地址换为eth0的地址。这样,在外界看来,这个包就是从10.10.101.105上发出来的,Docker容器对外是不可见的。
那么,外面的机器是如何访问Docker容器的服务呢?我们首先用下面命令创建一个含有web应用的容器,将容器的80端口映射到主机的80端口。
$ docker run --name=nginx_bridge --net=bridge -p 80:80 -d nginx
然后查看Iptable规则的变化,发现多了这样一条规则:
-A DOCKER ! -i docker0 -p tcp -m tcp --dport 80 -j DNAT --to-destination 172.17.0.2:80
此条规则就是对主机eth0收到的目的端口为80的tcp流量进行DNAT转换,将流量发往172.17.0.2:80,也就是我们上面创建的Docker容器。所以,外界只需访问10.10.101.105:80就可以访问到容器中的服务。
除此之外,我们还可以自定义Docker使用的IP地址、DNS等信息,甚至使用自己定义的网桥,但是其工作方式还是一样的。
以上都是不用动手的,真正需要配置的是自定义网络。
4.Docker Network
#1.格式:
docker network [cmd]
#2.ls:查看网桥列表
[root@docker100 ~/conf.d]# docker network ls
NETWORK ID NAME DRIVER SCOPE
a985cfca04ae bridge bridge local
c3d4dd997242 jinhui bridge local
a425f4733836 host host local
5902bdedd1b1 lnmd bridge local
ce7e9b514c2a none null local
#3.create:创建网桥
[root@docker100 ~]# docker network create test
202df8fb4cad122df28f286e17ecf9e596a0a47e5303f1bcbf757c7cf68c0121
[root@docker100 ~]# docker network ls |grep test
202df8fb4cad test bridge local
#4.rm: 删除网桥
[root@docker100 ~]# docker network rm test
test
[root@docker100 ~]# docker network ls |grep test
[root@docker100 ~]#
#5.inspect : 查看网桥详细信息
[root@docker100 ~]# docker network inspect -f '{{ .Containers }}' host
map[6a11bca3d507c42081065e6adf8e75f94fc570384e19d7a4eaa38772a1071a2d:{nginx_host 475311a9c2c60e89f67041f8aae5f01a3981fa8fb28eec1598a4faf71acc492c }]
#6.prune: 清理网桥
[root@docker100 ~]# docker network prune
#7.connect: 连接一个网桥
docker network connect [参数] [网桥名称] [容器名称]
disconnetc: 断开一个网桥连接
示例:
[root@docker ~/conf.d]# docker network disconnect lnmd sleepy_shaw
[root@docker ~/conf.d]# docker exec -it sleepy_shaw bash
[root@c548b0b76e31 /]# ping 767f43bc01d7
ping: 767f43bc01d7: Name or service not known
七、案例:
1.要求
起一个django服务,使用nginx代理,只向外暴露80端口,提供django服务。
2..配置
#1.创建bridge网络
[root@docker100 ~]# docker network create lnmd
5b8eaeba89602659eb4c3637db25798b03376777f2f89cd230167d9346e4119d
#2.运行Django容器
[root@docker100 ~]# docker run -d --network=lnmd alvinos/django:v3
49b11e72cbf13f9184153d33f7bf76a6a74a9b3c45348d4679a7863acc48533c
[root@docker100 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
49b11e72cbf1 alvinos/django:v3 "python3 manage.py r…" 17 seconds ago Up 15 seconds 80/tcp, 443/tcp frosty_maxwell
#3.创建nginx代理配置文件
[root@docker100 ~]# mkdir conf.d/
[root@docker100 ~]# pwd
/root
[root@docker100 ~]# touch ./conf.d/django.conf
#4.运行nginx代理
[root@docker100 ~]# docker run -d -p 38080:80 --network=lnmd -v /root/conf.d/:/etc/nginx/conf.d nginx
8192fa09c6a2e4d3ba12327f16a87052753e82aaa3e6e7ab727daaf7ad0bcee4
[root@docker100 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8192fa09c6a2 nginx "/docker-entrypoint.…" 7 minutes ago Up 7 minutes 0.0.0.0:38080->80/tcp unruffled_bohr
49b11e72cbf1 alvinos/django:v3 "python3 manage.py r…" 27 minutes ago Up 27 minutes 80/tcp, 443/tcp frosty_maxwell
#5.写入nginx代理文件
[root@docker100 ~]# vim ./conf.d/django.conf
server {
listen 80;
server_name _;
location / {
proxy_pass http://49b11e72cbf1;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_redirect off;
}
}
#6.测试nginx
[root@docker100 ~]# docker exec -i -t unruffled_bohr bash
root@8192fa09c6a2:/# cd /etc/nginx/conf.d/
root@8192fa09c6a2:/etc/nginx/conf.d# ls
django.conf
root@8192fa09c6a2:/etc/nginx/conf.d# cat django.conf
server {
listen 80;
server_name _;
location / {
proxy_pass http://49b11e72cbf1;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_redirect off;
}
}
root@8192fa09c6a2:/etc/nginx/conf.d# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
root@8192fa09c6a2:/etc/nginx/conf.d# nginx -s reload
2021/01/13 09:33:36 [notice] 42#42: signal process started
root@8192fa09c6a2:/etc/nginx/conf.d# exit
exit
#7.访问测试
10.0.0.61:38080 #正常
10.0.0.61:38080/index #正常
#8.80端口访问
[root@docker100 ~]# docker run -d -p 80:80 --network=lnmd -v /root/conf.d/:/etc/nginx/conf.d nginx
c4db530a98337fe4c70f82e879fb1f921b506046888d6059efec316cea023368
#9.再次访问
10.0.0.61 #正常
10.0.0.61/index #正常
八、Docker自定义网络
1.自定义网络介绍
建议使用自定义的网桥来控制哪些容器可以相互通信,还可以自动DNS解析容器名称到IP地址。Docker提供了创建这些网络的默认网络驱动程序,你可以创建一个新的Bridge网络,Overlay或Macvlan网络。你还可以创建一个网络插件或远程网络进行完整的自定义和控制。
你可以根据需要创建任意数量的网络,并且可以在任何给定时间将容器连接到这些网络中的零个或多个网络。此外,您可以连接并断开网络中的运行容器,而无需重新启动容器。当容器连接到多个网络时,其外部连接通过第一个非内部网络以词法顺序提供。
2.Docker的内置网络驱动
1) bridge
一个bridge网络是Docker中最常用的网络类型。桥接网络类似于默认bridge网络,但添加一些新功能并删除一些旧的能力。
#示例:
1.创建桥接网络
[root@docker100 ~]# docker network create --driver bridge new_bridge
286591e7f6a68e654c1970aaa0e92a4a131fafd8eb99beb12a4546f35b3765b4
2.显示网络类型
[root@docker100 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
daa11493364f bridge bridge local
fc5d4a69c90d host host local
5b8eaeba8960 lnmd bridge local
286591e7f6a6 new_bridge bridge local
16b8d6c8be22 none null local
3.查看网络
[root@docker100 ~]# ifconfig
br-286591e7f6a6: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.19.0.1 netmask 255.255.0.0 broadcast 172.19.255.255
ether 02:42:74:70:5a:56 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
2) Macvlan
Macvlan是一个新的尝试,是真正的网络虚拟化技术的转折点。Linux实现非常轻量级,因为与传统的Linux Bridge隔离相比,它们只是简单地与一个Linux以太网接口或子接口相关联,以实现网络之间的分离和与物理网络的连接。
Macvlan提供了许多独特的功能,并有充足的空间进一步创新与各种模式。这些方法的两个高级优点是绕过Linux网桥的正面性能以及移动部件少的简单性。删除传统上驻留在Docker主机NIC和容器接口之间的网桥留下了一个非常简单的设置,包括容器接口,直接连接到Docker主机接口。由于在这些情况下没有端口映射,因此可以轻松访问外部服务。
3) Macvlan Bridge模式示例用法
Macvlan Bridge模式每个容器都有唯一的MAC地址,用于跟踪Docker主机的MAC到端口映射。 Macvlan驱动程序网络连接到父Docker主机接口。示例是物理接口,例如eth0,用于802.1q VLAN标记的子接口eth0.10(.10代表VLAN 10)或甚至绑定的主机适配器,将两个以太网接口捆绑为单个逻辑接口。 指定的网关由网络基础设施提供的主机外部。 每个Macvlan Bridge模式的Docker网络彼此隔离,一次只能有一个网络连接到父节点。每个主机适配器有一个理论限制,每个主机适配器可以连接一个Docker网络。 同一子网内的任何容器都可以与没有网关的同一网络中的任何其他容器进行通信macvlan bridge。 相同的docker network命令适用于vlan驱动程序。 在Macvlan模式下,在两个网络/子网之间没有外部进程路由的情况下,单独网络上的容器无法互相访问。这也适用于同一码头网络内的多个子网。
在以下示例中,eth0在docker主机网络上具有IP地址172.16.86.0/24,默认网关为172.16.86.1,网关地址为外部路由器172.16.86.1。
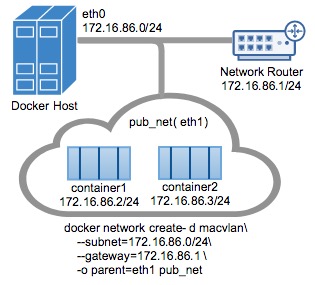
注意对于Macvlan桥接模式,子网值需要与Docker主机的NIC的接口相匹配。例如,使用由该-o parent=选项指定的Docker主机以太网接口的相同子网和网关。
此示例中使用的父接口位于eth0子网上172.16.86.0/24,这些容器中的容器docker network也需要和父级同一个子网-o parent=。网关是网络上的外部路由器,不是任何ip伪装或任何其他本地代理。
驱动程序用-d driver_name选项指定,在这种情况下-d macvlan。
父节点-o parent=eth0配置如下:
$ ip addr show eth0
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 172.16.86.250/24 brd 172.16.86.255 scope global eth0
创建macvlan网络并运行附加的几个容器:
# Macvlan (-o macvlan_mode= Defaults to Bridge mode if not specified)
docker network create -d macvlan
--subnet=172.16.86.0/24
--gateway=172.16.86.1
-o parent=eth0 pub_net
# Run a container on the new network specifying the --ip address.
docker run --net=pub_net --ip=172.16.86.10 -itd alpine /bin/sh
# Start a second container and ping the first
docker run --net=pub_net -it --rm alpine /bin/sh
ping -c 4 172.16.86.10
看看容器ip和路由表:
ip a show eth0
eth0@if3: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UNKNOWN
link/ether 46:b2:6b:26:2f:69 brd ff:ff:ff:ff:ff:ff
inet 172.16.86.2/24 scope global eth0
ip route
default via 172.16.86.1 dev eth0
172.16.86.0/24 dev eth0 src 172.16.86.2
# NOTE: the containers can NOT ping the underlying host interfaces as
# they are intentionally filtered by Linux for additional isolation.
# In this case the containers cannot ping the -o parent=172.16.86.250
4) Macvlan 802.1q Trunk Bridge模式示例用法
VLAN(虚拟局域网)长期以来一直是虚拟化数据中心网络的主要手段,目前仍在几乎所有现有的网络中隔离广播的主要手段。
常用的VLAN划分方式是通过端口进行划分,尽管这种划分VLAN的方式设置比较很简单,但仅适用于终端设备物理位置比较固定的组网环境。随着移动办公的普及,终端设备可能不再通过固定端口接入交换机,这就会增加网络管理的工作量。比如,一个用户可能本次接入交换机的端口1,而下一次接入交换机的端口2,由于端口1和端口2属于不同的VLAN,若用户想要接入原来的VLAN中,网管就必须重新对交换机进行配置。显然,这种划分方式不适合那些需要频繁改变拓扑结构的网络。而MAC VLAN可以有效解决这个问题,它根据终端设备的MAC地址来划分VLAN。这样,即使用户改变了接入端口,也仍然处在原VLAN中。
Mac vlan不是以交换机端口来划分vlan。因此,一个交换机端口可以接受来自多个mac地址的数据。一个交换机端口要处理多个vlan的数据,则要设置trunk模式。
在主机上同时运行多个虚拟网络的要求是非常常见的。Linux网络长期以来一直支持VLAN标记,也称为标准802.1q,用于维护网络之间的数据路由隔离。连接到Docker主机的以太网链路可以配置为支持802.1q VLAN ID,方法是创建Linux子接口,每个子接口专用于唯一的VLAN ID。
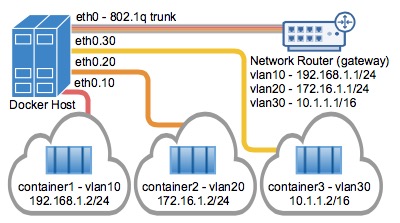
#1.创建Macvlan网络
VLAN ID 10
$ docker network create
--driver macvlan
--subnet=10.10.0.0/24
--gateway=10.10.0.253
-o parent=eth0.10 macvlan10
#2.开启一个桥接Macvlan的容器
$ docker run --net=macvlan10 -it --name macvlan_test1 --rm alpine /bin/sh
/ # ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
21: eth0@if13: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UNKNOWN
link/ether 02:42:0a:0a:00:01 brd ff:ff:ff:ff:ff:ff
inet 10.10.0.1/24 scope global eth0
valid_lft forever preferred_lft forever
#3.查看一下路由地址,可以看到分配了一个10.10.0.1的地址
/ # ip route
default via 10.10.0.253 dev eth0
10.10.0.0/24 dev eth0 src 10.10.0.1
#4.然后再开启一个桥接Macvlan的容器
$ docker run --net=macvlan10 -it --name macvlan_test2 --rm alpine /bin/sh
/ # ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
22: eth0@if13: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UNKNOWN
link/ether 02:42:0a:0a:00:02 brd ff:ff:ff:ff:ff:ff
inet 10.10.0.2/24 scope global eth0
valid_lft forever preferred_lft forever
#5.ping通两个容器
可以看到分配了一个10.10.0.2的地址,然后可以在两个容器之间相互ping,是可以ping通的。
/ # ping 10.10.0.1
PING 10.10.0.1 (10.10.0.1): 56 data bytes
64 bytes from 10.10.0.1: seq=0 ttl=64 time=0.094 ms
64 bytes from 10.10.0.1: seq=1 ttl=64 time=0.057 ms
经过上面两个容器的创建可以看出,容器IP是根据创建网络时的网段从小往大分配的。
当然,在创建容器时,我们也可以使用--ip手动执行一个IP地址分配给容器,如下操作。
$ docker run --net=macvlan10 -it --name macvlan_test3 --ip=10.10.0.189 --rm alpine /bin/sh
/ # ip addr show eth0
24: eth0@if13: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UNKNOWN
link/ether 02:42:0a:0a:00:bd brd ff:ff:ff:ff:ff:ff
inet 10.10.0.189/24 scope global eth0
valid_lft forever preferred_lft forever
#1.创建Macvlan网络
VLAN ID 20
接着可以创建由Docker主机标记和隔离的第二个VLAN网络,该macvlan_mode默认是macvlan_mode=bridge,如下:
$ docker network create
--driver macvlan
--subnet=192.10.0.0/24
--gateway=192.10.0.253
-o parent=eth0.20
-o macvlan_mode=bridge macvlan20
当我们创建完Macvlan网络之后,在docker主机可以看到相关的子接口,如下:
$ ifconfig
eth0.10: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
ether 00:0c:29:16:01:8b txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 18 bytes 804 (804.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0.20: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
ether 00:0c:29:16:01:8b txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
在/proc/net/vlan/config文件中,还可以看见相关的Vlan信息,如下:
$ cat /proc/net/vlan/config
VLAN Dev name | VLAN ID
Name-Type: VLAN_NAME_TYPE_RAW_PLUS_VID_NO_PAD
eth0.10 | 10 | eth0
eth0.20 | 20 | eth0