一、 Apache和Apache集群间数据拷贝
#1.scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/user/delopy/hello.txt // 推 push
scp -r root@hadoop103:/user/delopy/hello.txt hello.txt // 拉 pull
scp -r root@hadoop103:/user/delopy/hello.txt root@hadoop104:/user/delopy //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
#2.采用distcp命令实现两个Hadoop集群之间的递归数据复制
[delopy@hadoop102 hadoop]$ bin/hadoop distcp hdfs://hadoop102:8020/user/delopy/hello.txt hdfs://hadoop105:8020/user/delopy/hello.txt
二、Apache和CDH集群间数据拷贝
#1.准备两套集群,我这使用apache集群和CDH集群。

#2.启动集群
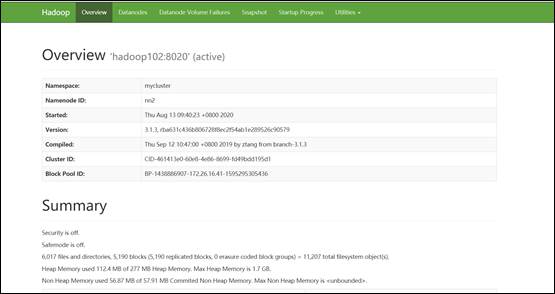
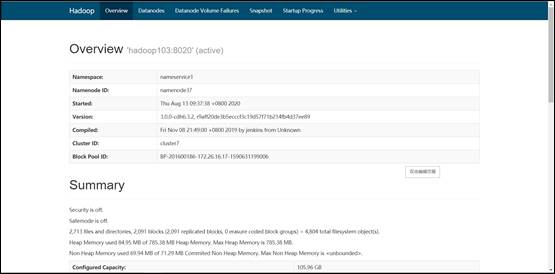
#3.启动完毕后,将apache集群中,hive库里dwd,dws,ads三个库的数据迁移到CDH集群
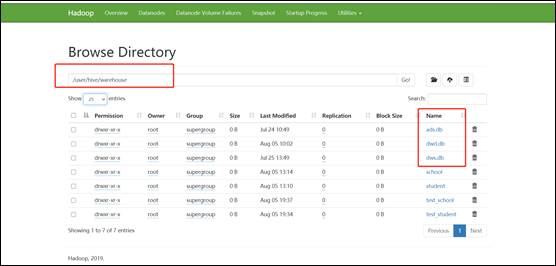
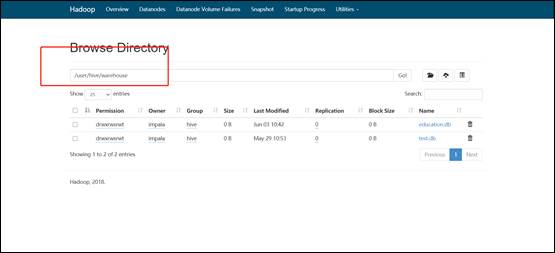
#4.在apache集群里hosts加上CDH Namenode对应域名并分发给各机器
[root@hadoop101 ~]# vim /etc/hosts
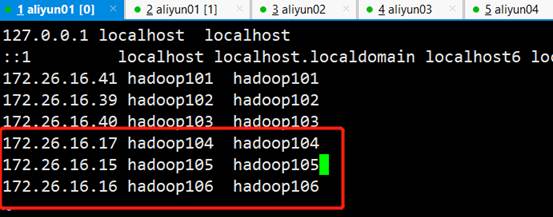
[root@hadoop101 ~]# scp /etc/hosts hadoop102:/etc/
[root@hadoop101 ~]# scp /etc/hosts hadoop103:/etc/
#5.因为集群都是HA模式,所以需要在apache集群上配置CDH集群,让distcp能识别出CDH的nameservice
[root@hadoop101 hadoop]# vim /opt/module/hadoop/etc/hadoop/hdfs-site.xml
<!--配置nameservice-->
<property>
<name>dfs.nameservices</name>
<value>mycluster,nameservice1</value>
</property>
<!--指定本地服务-->
<property>
<name>dfs.internal.nameservices</name>
<value>mycluster,nameservice1</value>
</property>
<!--配置多NamenNode-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop101:8020</value>
</property>
<property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop102:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop103:8020</value>
</property>
<!--配置nameservice1的namenode服务-->
<property>
<name>dfs.ha.namenodes.nameservice1</name>
<value>namenode30,namenode37</value>
</property>
<property>
<name>dfs.namenode.rpc-address.nameservice1.namenode30</name>
<value>hadoop104:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.nameservice1.namenode37</name>
<value>hadoop106:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.nameservice1.namenode30</name>
<value>hadoop104:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.nameservice1.namenode37</name>
<value>hadoop106:9870</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.nameservice1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--为NamneNode设置HTTP服务监听-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop101:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop102:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop103:9870</value>
</property>
<!--配置HDFS客户端联系Active NameNode节点的Java类-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
#6.修改CDH hosts
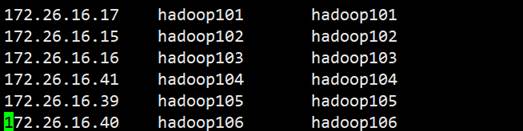
#7.进行分发,这里的hadoop104,hadoop105,hadoop106分别对应apache的hadoop101,hadoop102,hadoop103
[root@hadoop101 ~]# scp /etc/hosts hadoop102:/etc/
[root@hadoop101 ~]# scp /etc/hosts hadoop103:/etc/
#8.同样修改CDH集群配置,在所有hdfs-site.xml文件里修改配置
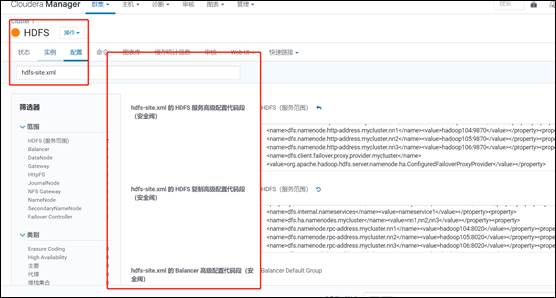
<property>
<name>dfs.nameservices</name>
<value>mycluster,nameservice1</value>
</property>
<property>
<name>dfs.internal.nameservices</name>
<value>nameservice1</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop104:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop105:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop106:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop104:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop105:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop106:9870</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
#9.最后注意:重点由于我的Apahce集群和CDH集群3台集群都是hadoop101,hadoop102,hadoop103所以要关闭域名访问,使用IP访问CDH把钩去了
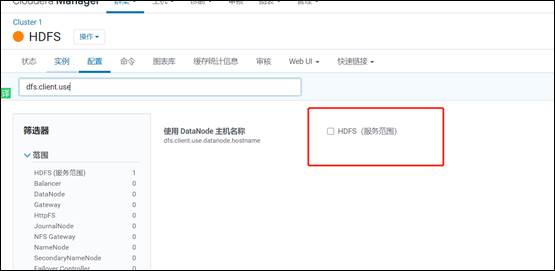
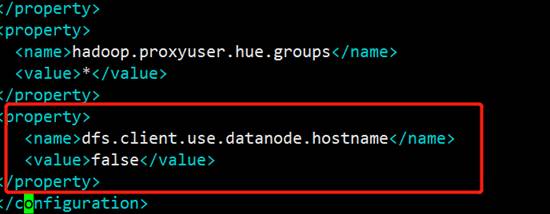
#10.apache设置为false
#11.再使用hadoop distcp命令进行迁移,-Dmapred.job.queue.name指定队列,默认是default队列。上面配置集群都配了的话,那么在CDH和apache集群下都可以执行这个命令
[root@hadoop101 hadoop]# hadoop distcp -Dmapred.job.queue.name=hive webhdfs://mycluster:9070/user/hive/warehouse/dwd.db/ hdfs://nameservice1/user/hive/warehouse
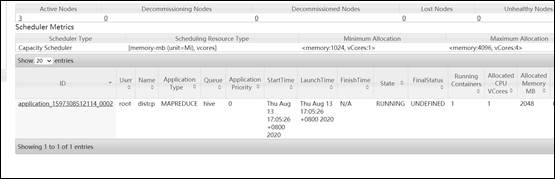
#12.会启动一个MR任务,正在迁移

#13.查看cdh 9870 http地址
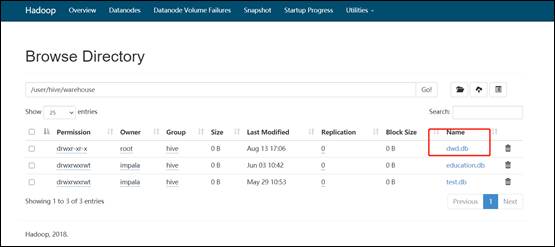

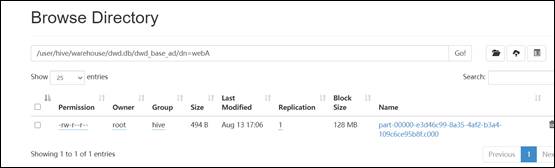
#14.数据已经成功迁移。数据迁移成功之后,接下来迁移hive表结构,编写shell脚本
[root@hadoop101 module]# vim exportHive.sh
#!/bin/bash
hive -e "use dwd;show tables">tables.txt
cat tables.txt |while read eachline
do
hive -e "use dwd;show create table $eachline">>tablesDDL.txt
echo ";" >> tablesDDL.txt
done
#15.执行脚本后将tablesDDL.txt文件分发到CDH集群下
[root@hadoop101 module]# scp tablesDDL.txt hadoop104:/opt/module/
#16.然后CDH下导入此表结构,先进到CDH的hive里创建dwd库
[root@hadoop101 module]# hive
hive> create database dwd;
#17.创建数据库后,边界tablesDDL.txt在最上方加上use dwd;
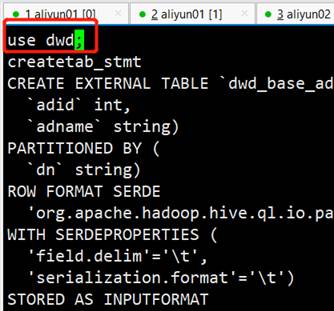
#18.并且将createtab_stmt都替换成空格
[root@hadoop101 module]# sed -i s"#createtab_stmt# #g" tablesDDL.txt
#19.最后执行hive -f命令将表结构导入
[root@hadoop101 module]# hive -f tablesDDL.txt
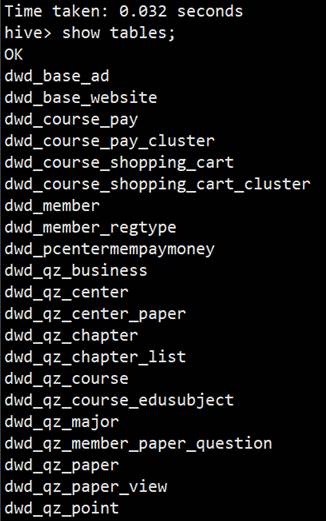
#20.最后将表的分区重新刷新下,只有刷新分区才能把数据读出来,编写脚本
[root@hadoop101 module]# vim msckPartition.sh
#!/bin/bash
hive -e "use dwd;show tables">tables.txt
cat tables.txt |while read eachline
do
hive -e "use dwd;MSCK REPAIR TABLE $eachline"
done
[root@hadoop101 module]# chmod +777 msckPartition.sh
[root@hadoop101 module]# ./msckPartition.sh
#21.刷完分区后,查询表数据