评注:提到HAProxy业务层proxy, twemproxy存储的proxy.
其中还提到了ketama算法的实现源码
转自:http://www.cnblogs.com/basecn/p/4288456.html
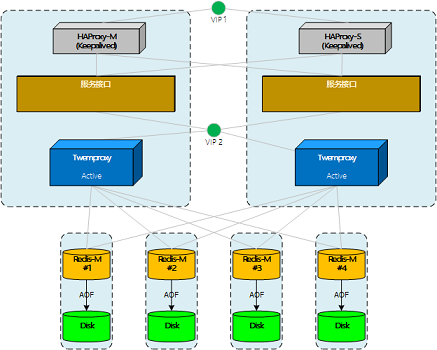
测试Twemproxy集群,双主双活
向twemproxy集群做写操作时,发现key的分布不太理想。在测试节点故障时,也发现一些和预想不太一样的地方。
1、Key的一致性Hash
当尝试以a001,a002这样有规律且的key值写入的时候,在4节点的集群环境中,key主要分布在其中的2台节点,另外两台分配极少。对于一些应用来说,key值可能根据一定规则生成,所以有被定向分配的可能。
解决办法在key中使用hash_key:{},hask_key使用8位随机数,测试结果分布的比较满意。
测试4节点中key的分布:
2: 10761
3: 8596
4: 14382
由于ketama的算法仍是使用了md5签名(具体后面说),又特意观察了比如有序数字生成的md5序列,结果并没有出现明显的有序或连序值。所以只能建议不使用连续的数据结尾key做一致性hash key。
2、ketama算法
twemproxy源码下载:https://github.com/twitter/twemproxy,命令:git clone https://github.com/twitter/twemproxy
关于ketama算法的代码在nc_ketama.c文件中,主要是四个方法:
- ketama_hash 计算某个主机,某个point的hash值
- ketama_item_cmp 比较两个连续区的值,用于在ketama_update 方法中排序
- ketama_update 更新server-pool的分配策略
- ketama_dispatch 找出给定hash值所在的连续区
2.1 连续区
说一下连续区(continuum),参考下图。想象所有md5的值构成下面完整的“环”(没有起点),那么所有md5结果值在环上都有一个固定的位置。
按ketama的算法,在这个环上创建服务器数*160个点,这些点把环分成了同等数量的段。
那么,被插入数据的md5值也一定会落到环的某个区间,以此来判断数据应被写入哪台服务器。
 参考:理想化的Redis集群
参考:理想化的Redis集群
2.2 如何生成ketama_hash
再来看服务器+点的hash值是如何生成的:
alignment的值固定是4,ketama_hash是对由server名+索引组成的md5签名,从第16位开始取值,再重组一个32位值。

static uint32_t
ketama_hash(const char *key, size_t key_length, uint32_t alignment)
{
unsigned char results[16];
md5_signature((unsigned char*)key, key_length, results);
return ((uint32_t) (results[3 + alignment * 4] & 0xFF) << 24)
| ((uint32_t) (results[2 + alignment * 4] & 0xFF) << 16)
| ((uint32_t) (results[1 + alignment * 4] & 0xFF) << 8)
| (results[0 + alignment * 4] & 0xFF);
}
下面是调用ketama_hash的代码:
for (x = 0; x < pointer_per_hash; x++) {
value = ketama_hash(host, hostlen, x);
pool->continuum[continuum_index].index = server_index;
pool->continuum[continuum_index++].value = value;
}
每个服务器被分成160个point点,由服务器名+索引组成host值,x值等于160/索引。
这样计算出的服务器各点的值并不是有序的,所以进行排序。
qsort(pool->continuum, pool->ncontinuum, sizeof(*pool->continuum), ketama_item_cmp);
排序后的点值是连续的,但同一服务器的点并不一定连续。这时,所有的值构成了用于一致性hash的环。
2.3、分配Key
由ketama_dispatch实现key值的分配。
可见方法中使用二分法找到一个值在环中的对应区域。
uint32_t
ketama_dispatch(struct continuum *continuum, uint32_t ncontinuum, uint32_t hash)
{
struct continuum *begin, *end, *left, *right, *middle;
ASSERT(continuum != NULL);
ASSERT(ncontinuum != 0);
begin = left = continuum;
end = right = continuum + ncontinuum;
while (left < right) {
middle = left + (right - left) / 2;
if (middle->value < hash) {
left = middle + 1;
} else {
right = middle;
}
}
if (right == end) {
right = begin;
}
return right->index;
}
3、服务器的故障处理
从集群中摘除节点时,ketama的算法不会重新计算"环"。当需要写入故障节点时,会抛出异常。
仔细想一下是合理的,因为摘除的节点持有一部分数据,一般来说是需要恢复的,这是一个前提。
我们假设twemproxy可以感知节点故障,并重新计算分配策略。那么,故障后又有新的数据写入。这时,一部分原本要写入故障节点的数据会被分配到其它节点上。
随后,故障节点恢复,twemproxy又重新调整了分配策略。那么,后写入的那部分数据就不会再被找到(这个有点像内存泄露)。