Canal是什么?
canal是模拟mysql的slave节点,向master节点发送dump请求,获取binlog数据。解析binlog数据实现自己的业务操作
canal能干什么?
canal最开始设计出来是用来解决跨机房数据同步问题。我们可以用它来做缓存刷新,数据同步等等。
canal工作原理
-
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
-
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
-
canal 解析 binary log 对象(原始为 byte 流)
canal中比较重要的几个模块
parse
该模块主要是向master节点发送dump请求,然后获取binlog数据,将数据交给sink模块处理
sink
该模块主要是接收parse模块下传的数据,将数据进行一些过滤,然后将数据交给store模块处理
store
该模块将sink模块下传的数据进行存储,并记录get以及ack位置,供client端使用。
meta
该模块记录一些client端的消费信息,第一当client提交ack或者rollback时,可以根据这些信息做相应的处理。第二当服务端重启或者切换实例时,可以根据这些信息确定哪些数据client端还没消费,以便重新从master拉取数据。
client
提供一个客户端连接工具,比如单机(SimpleCanalConnector)或集群模式(ClusterCanalConnector)。也提供集成了一些mq组件的CanalConnector,如:KafkaCanalConnector,RabbitMQCanalConnector,RocketMQCanalConnector
admin
canal运维平台,可以查看/修改canal的一些运行时信息
server
canal的server端,主要是注册一些server信息以及接收client的请求然后处理
protocol
定义了一些数据传输对象
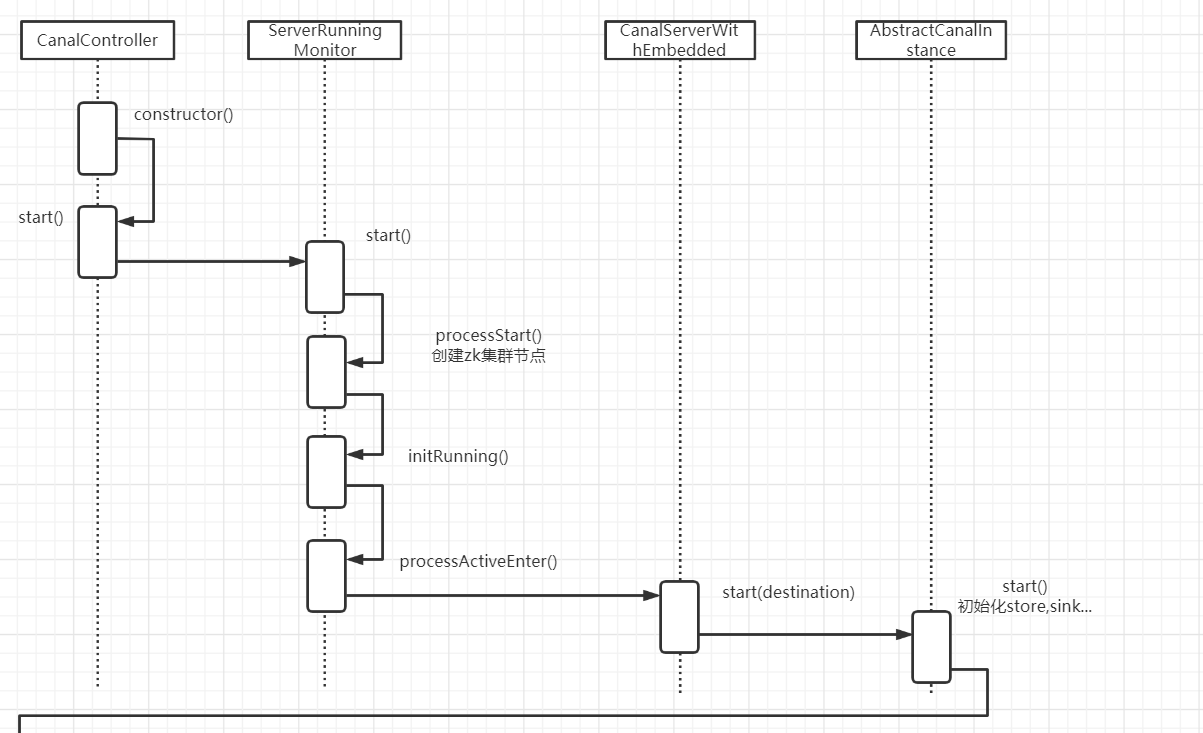
canal server获取binlog重要流程

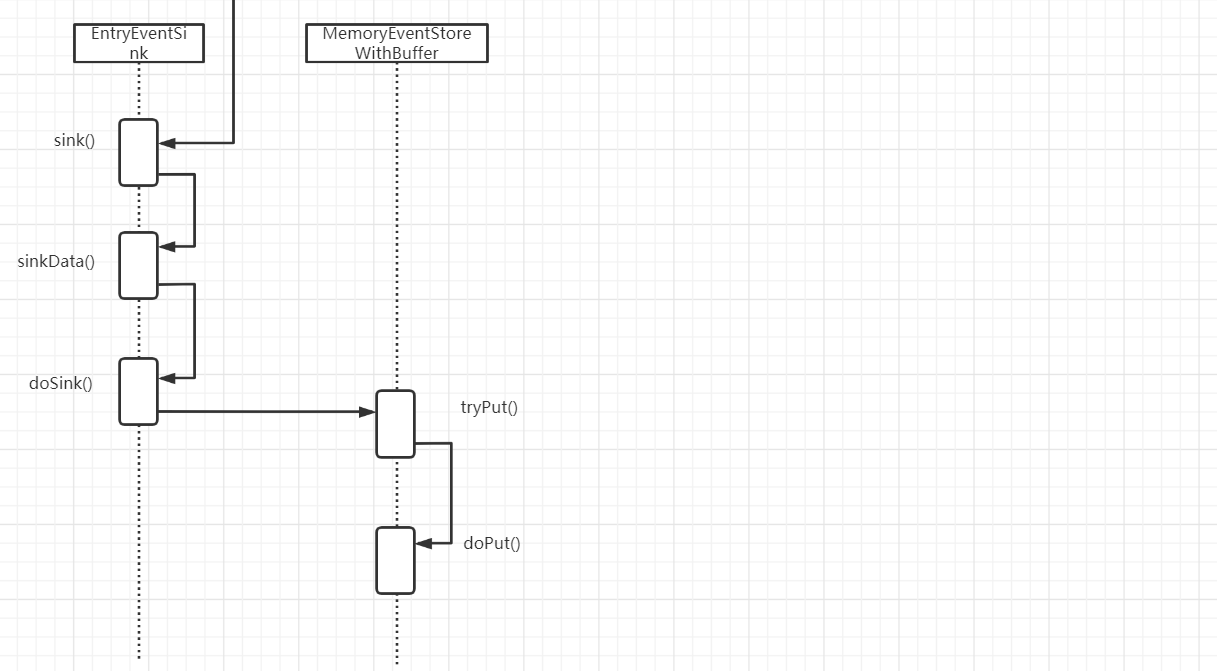
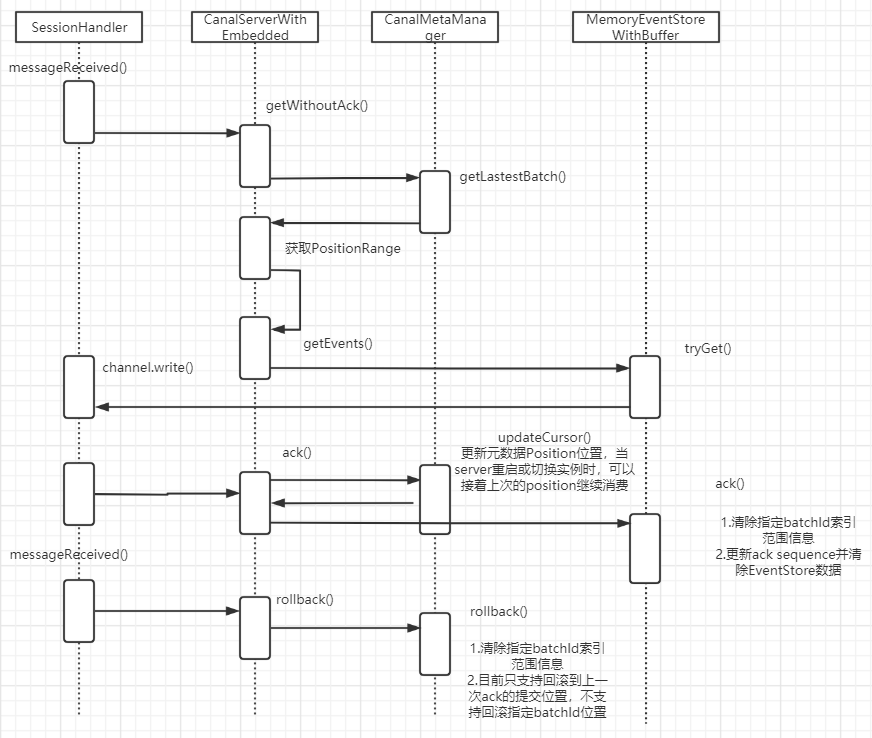
server监听client消息处理流程
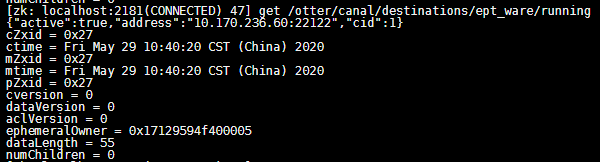
节点含义
-
/otter/canal/destinations/{destination}/cluster
子节点表示canal server的集群(临时节点)

-
/otter/canal/destinations/{destination}/running
节点数据表示表示当前激活的 canal server实例(临时节点)
-
/otter/canal/destinations/{destination}/1001/running
节点数据表示表示当前激活的 canal client实例(临时节点)
client激活原理(ClientRunningMonitor)
当客户端连接时,创建/otter/canal/destinations/{destination}/1001/running节点,如果节点已存在,不做任何操作。如果不存在,则创建该节点,并且监听该节点。如果监听到删除事件,则抢占该节点。server与client类似。
server运行实例切换,client响应
client会监听
/otter/canal/destinations/{destination}/running和/otter/canal/destinations/{destination}/cluster节点,当节点的数据发生变更的时候,client会更新本地的runningAddress,当runningAddress`不存在时,则会取集群中的第一个地址。当client向server发送请求失败时,client会重新connect。
client订阅server
当client向server发起subscribe时,server会做以下几件事
判断server的元数据管理器是否启动,如果未启动,则启动
元数据管理器存储client的一些基本信息
获取该client最后一次的消费position,如果position为空,判断该canalInstance的store是否有数据,如果有数据,则取出第一条数据的position,将该position更新为该client最后一次的消费position。
Server监听Binlog事件
com.alibaba.otter.canal.parse.inbound.mysql.dbsync.DirectLogFetcher#fetch()
-
QueryLogEvent
一些查询日志
-
TableMapLogEvent
表信息
-
UpdateRowsLogEvent
具体变更的数据
-
XidLogEvent
事务id
client端ack以及rollback
当客户端发起ack或rollback时,必须按照batchId的从小到大的顺序依次提交。
server端的ack逻辑是当接收到ack请求时,首先获取到该batchId的positionRange,positionRange中有endSeq信息,然后将全局的ackSequence更新到endSeq,如果batchId是乱序的,则会导致更新了一些没有提交数据的ack位置。
server端的rollback逻辑是当接收到rollback请求时,直接将getSequence重置为ackSequence,相当于是全部rollback,不支持回滚到指定batchId位置。