零
seq2seq是从序列到序列的学习过程,最重要的是输入序列和输出序列是可变长的,这种方式就非常灵活了,典型的机器翻译就是这样一个过程。
一
最基本的seq2seq网络架构如下所示:
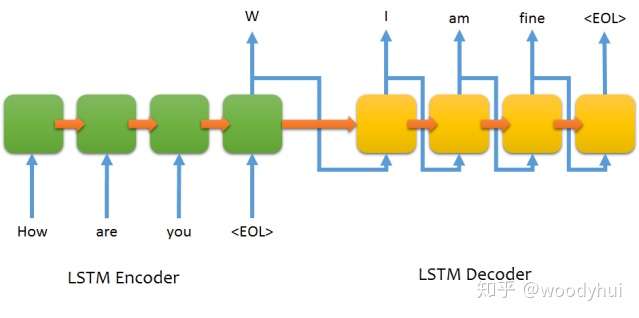
可以看到,encoder构成一个RNN的网络,decoder也是一个RNN的网络。训练过程和推断过程有一些不太一样的地方,介绍如下。
训练过程:
- encoder构成一个RNN网络,输入为源语言的文本,输出最后一个timestep的hidden state,同时不需要output,将最后一个hidden state作为decoder的初始化state;
- decoder也构成一个RNN网络,输入为目标语言的文本,这个地方要注意的是输入需要往后lag一个位置,输出就是正常的目标语言文本即可,选用categorical cross entropy进行多分类训练。
# input sentence
How are you
# output sentence
I am fine
# encoder input
["How", "are", "you"]
# decoder input
["<start tag>", "I", "am", "fine"]
# decoder target
["I", "am", "fine", "<end tag>"]推断过程:
推断过程只有encoder input了,所以有个greedy/sampling/beam-search等decoding的方法,下面讨论最简单的greedy方法。
- 将源语言的输入经过encoder编码成最后timestep的hidden state;
- 目标语言的输入设定成一个单词<start tag>,喂给decoder,产出一个目标单词;
- 将上一步的目标的单词作为目标语言新的输入,继续2的步骤,直到遇到<end tag>,或者产生的预测sequence长度超过阈值。
二
以上就是最基本的seq2seq架构,优点就是简单,缺点也很明显,我们人类一般翻译文本的时候,目标语言单词往往只和源语言文本其中有限一两个单词有关,而上面的做法,将源语言文本编码成一个固定长度的hidden state,导致decoder过程中每个单词都是受固定state的影响,而没有差异化和重点,由此下一篇会介绍seq2seq优化的比较重要的一个机制 - Attention Mechanism。