转自:C# 写个小爬虫,实现爬取js加载后的网页_zjl1353911的博客-CSDN博客_c#实现爬虫
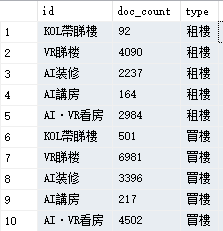
有个业务是爬取网页中的某一组数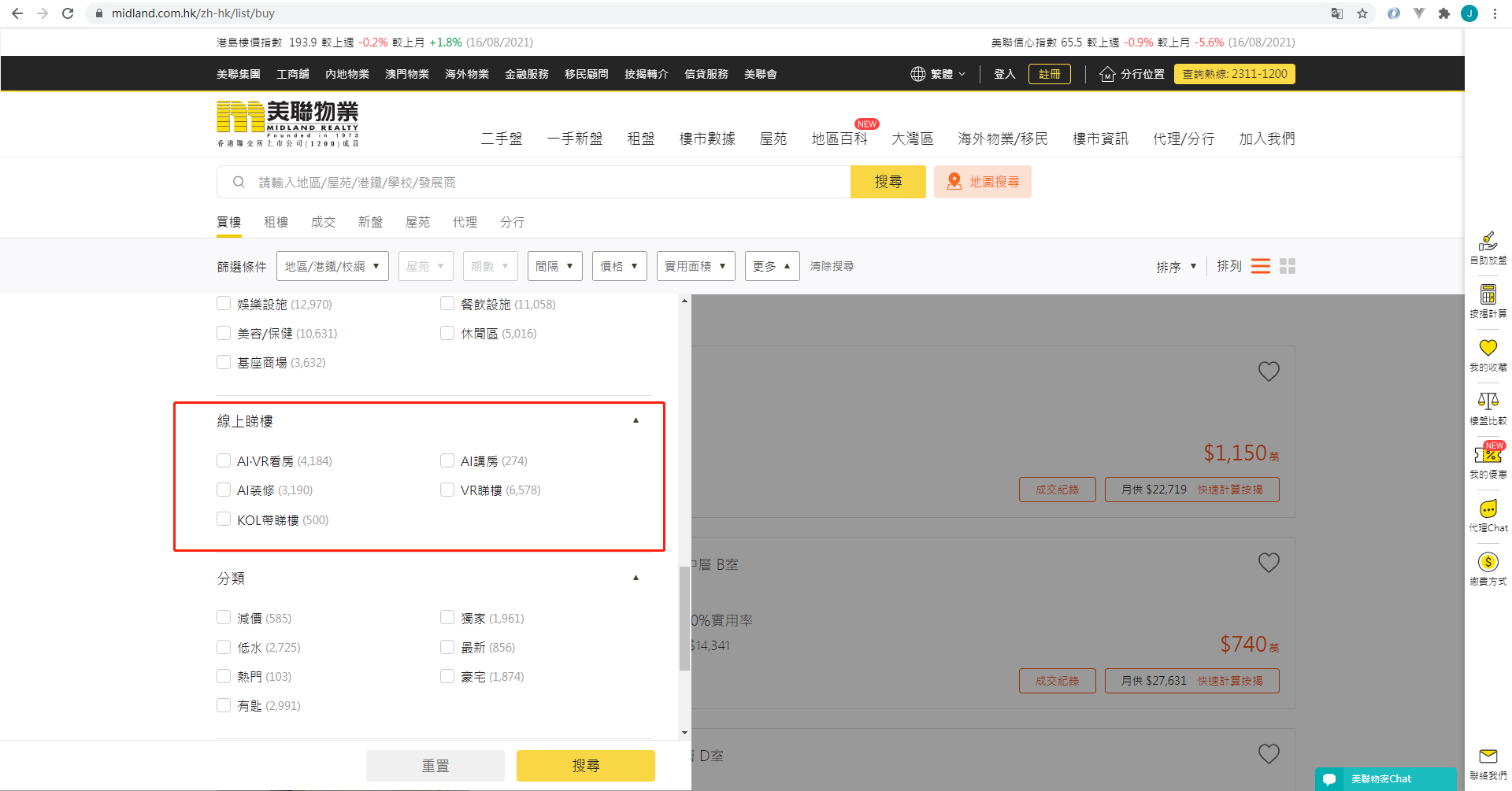
查看页面源代码时发现是一堆未加载的html,有两种办法可以获取,一个是在茫茫代码中拼接获取数据的接口,另一个是用第三方的库加载获得数据;这里用的是后者:
第一:安装第三方组件:
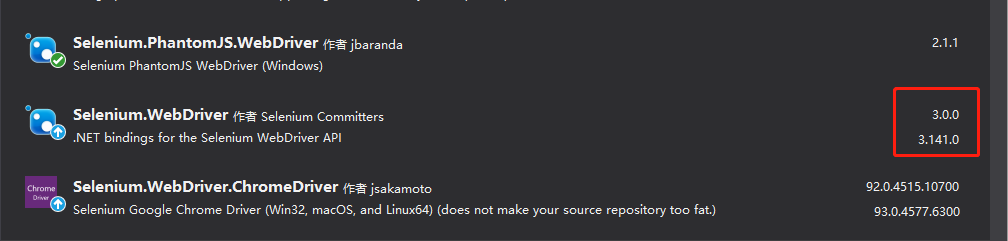
注意中间这个库的版本要求;
用法:


public static string GetWebHtmlManage(string url) { PhantomJSDriverService driverService = PhantomJSDriverService.CreateDefaultService(); driverService.IgnoreSslErrors = true; ChromeOptions options = new ChromeOptions(); options.AddArgument("--headless"); options.AddArgument("--nogpu"); List<String> tagNmaeList = new List<string>(); using (driver = new ChromeDriver(options)) { try { driver.Manage().Window.Maximize(); driver.Navigate().GoToUrl(url); Thread.Sleep(5000); var docStr = driver.PageSource; return docStr; } catch (NoSuchElementException ex) { throw ex; } } }
获取的是字符串类型的Html,可用解析Html的组件转为Html文档再解析;
结果: