Json (JavaScript Object Notation),即JavaScript对象标记法,当前十分流行和常见的互联网数据传输格式,尤其是在前端领域。Json是一种用于数据交换的文本格式,目的是取代繁琐笨重的XML格式。Json是一种轻量级(Light-Weight)、基于文本的(Text-Based)、可读的(Human-Readable)格式,相比于XML格式更小。每个Json对象就是一个值,要么是简单类型的值,要么是复合类型的值,但是只能是一个值,不能是两个或多个的值,即每个Json文档只能包含一个值。
Json对值类型的严格规定:
- 复合类型的值只能是数组或对象,不能是函数、正则表达式对象、日期对象;
- 简单类型的值只有四种:字符型、数值(必须是十进制)、布尔型和null(不能使用NaN, Infinity, - Infinity和undefined);
- 字符串必须使用双引号表示,不能使用单引号;
- 对象的键名必须放在双引号里面;
- 数组或对象最后一个成员的后面,不能加逗号;
- 数组(Array)用方括号(“[]”)表示;
- 对象(Object)用大括号(”{}”)表示;
- 名称/值对(name/value)组合成数组和对象;
- 名称(name)置于双引号中,值(value)有字符串、数值、布尔值、null、对象和数组;
- 并列的数据之间用逗号(“,”)分隔。
例如:
//json对象
{
"name": "Geoff Lui",
"age": 26,
"isChinese": true
}
//“名称/值对”里,值可以是数组和对象
{
"name": "Geoff Lui",
"age": 26,
"isChinese": true,
"friends":["Lucy", "Lily", "Gwen"],
"Mother": {
"name": "Mary Lui",
"age": 54
}
}
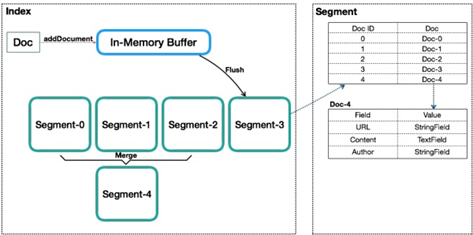
Apache Lucene是一个开源的高性能、可扩展的信息检索(IR)引擎,提供了强大的数据检索能力,不仅能支持全文索引,也能提供多种其他类型的索引方式,来满足不同类型的查询需求。基于Lucene的开源项目有很多,最知名的有Elasticsearch和Solr,如果说Elasticsearch和Solr是一辆设计精美、性能卓越的跑车,那Lucene就是为其提供强大动力的引擎。
Index(索引)
类似数据库表的概念,但与传统表的概念有很大的不同。传统关系型数据库或者NoSQL数据库的表,在创建时至少要定义表的Scheme,定义表的主键或列等,会有一些明确定义的约束。Lucene的Index,则完全没有约束,Lucene的Index可以理解为一个文档收纳箱,可以往内部塞入新的文档,或者从里面拿出文档,但如果要修改里面的某个文档,则必须先拿出来修改后再塞回去。这个收纳箱可以塞入各种类型的文档,文档里的内容可以任意定义,Lucene都能对其进行索引。
Document(文档)
类似数据库内的行或者文档数据库内的文档的概念,一个Index内会包含多个Document。写入Index的Document会被分配一个唯一的ID,即Sequence Number(DocId)。
Field(字段)
一个Document会由一个或多个Field组成,Field是Lucene中数据索引的最小定义单位。Lucene提供多种不同类型的Field,例如StringField、TextField、LongFiled或NumericDocValuesField等,Lucene根据Field的类型(FieldType)来判断该数据要采用哪种类型的索引方式(Invert Index、Store Field、DocValues或N-dimensional等)。
Term和Term Dictionary
Lucene中索引和搜索的最小单位,一个Field会由一个或多个Term组成,Term是由Field经过Analyzer(分词)产生。Term Dictionary即Term词典,是根据条件查找Term的基本索引。
Segment
一个Index会由一个或多个sub-index构成,sub-index被称为Segment。Lucene在查询上只能提供近实时而非实时查询。
Lucene中的数据写入会先写内存的一个Buffer(不可读),当Buffer内数据到一定量后会被flush成一个Segment,每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。这种模式避免了随机写,数据写入都是Batch和Append,能达到很高的吞吐量。Segment中写入的文档不可被修改,但可被删除,删除的方式也不是在文件内部原地更改,而是会由另外一个文件保存需要被删除的文档的DocID,保证数据文件不可被修改。Index的查询需要对多个Segment进行查询并对结果进行合并,还需要处理被删除的文档,为了对查询进行优化,Lucene会有策略对多个Segment进行合并。
Segment在被flush或commit之前,数据保存在内存中,是不可被搜索的,这就是为什么Lucene被称为提供近实时而非实时查询的原因。Lucene中数据搜索依赖构建的索引(例如倒排依赖Term Dictionary),Lucene中对数据索引的构建会在Segment flush时,而非数据实时写入时即构建,目的是为了构建最高效索引。
Sequence Number 也称 DocId
数据库内通过主键来唯一标识一行,而Lucene的Index通过DocId来唯一标识一个Doc。
- DocId实际上并不在Index内唯一,而是Segment内唯一,Lucene这么做主要是为了写入和压缩优化。既然在Segment内才唯一,又是怎么做到在Index级别来唯一标识一个Doc?方案很简单,Segment之间是有顺序的,举个简单的例子,一个Index内有两个Segment,每个Segment内分别有100个Doc,在Segment内DocId都是0-100,转换到Index级的DocId,需要将第二个Segment的DocId范围转换为100-200。
- DocId在Segment内唯一,取值从0开始递增。但不代表DocId取值一定是连续的,如果有Doc被删除,那可能会存在空洞。
- 一个文档对应的DocId可能会发生变化,主要是发生在Segment合并时。
Lucene内最核心的倒排索引,本质上就是Term到所有包含该Term的文档的DocId列表的映射。所以Lucene内部在搜索的时候会是一个两阶段的查询,第一阶段是通过给定的Term的条件找到所有Doc的DocId列表,第二阶段是根据DocId查找Doc。Lucene提供基于Term的搜索功能,也提供基于DocId的查询功能。
Lucene索引类型
Lucene中支持丰富的字段类型,每种字段类型确定了支持的数据类型以及索引方式,目前支持的字段类型包括LongPoint、TextField、StringField、NumericDocValuesField等。
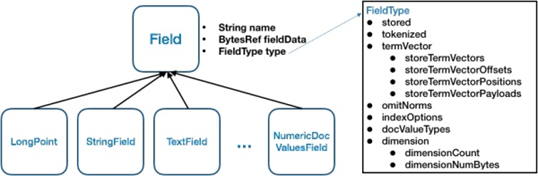
如图,Lucene中对于不同类型Field定义的一个基本关系,所有字段类都会继承自Field这个类,Field包含3个重要属性:name(String)、fieldsData(BytesRef)和type(FieldType)。name即字段的名称,fieldsData即字段值,所有类型的字段的值最终都会转换为二进制字节流来表示。type是字段类型,确定了该字段被索引的方式。