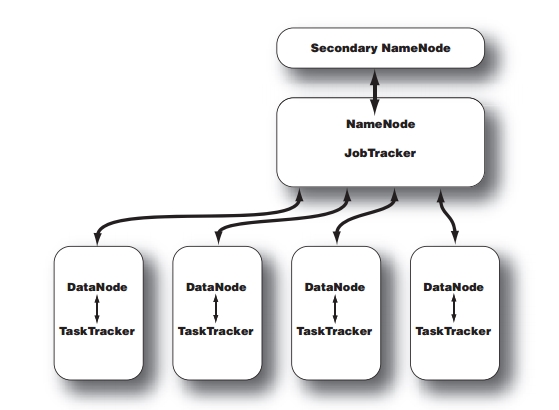
刚好看到关于Name node/Data node和Job tracker/Task tracker的解释,一开始有点混淆,以为说Job tracker必须运行在Name node上,他们俩有依赖或者从属关系。其实不是这样的。他们间的区别在于
1)Name node/Data node是HTFS层面上的东西,是服务器角色;Job tracker/Task tracker是Hadoop任务调度的一部分,是一组任务;
2)Name node负责的是如何将文件分割成多个HTFS文件块,交给MapReduce处理后存储到哪些Data node上,要复制到哪些Data node,所以这一切都是存储层面上的东西;而Job tracker是服务端应用程序和Hadoop之间通信的桥梁,客户端提交数据请求,由Job tracker决定执行计划,分配给不同的Task tracker任务的执行计划,每个Task tracker在它的Data node上要执行Map和Reduce函数。Job tracker还需要处理如果Task tracker没有响应这种failure的情况,如何通过指派Task给另一个Task tracker来重启Task。Job tracker和Task tracker又是通过心跳线来报告健康情况的。所以这样看,Job tracker就是一个调度器(scheduler),调度Task tracker的执行,而Task tracker又是另一个调度器,调度自己本机上的MapReduce任务运行。这就是一种典型的主从编程结构(MasterSlave)。虽然Task tracker每个节点只有一个,但是可以通过生成多少Java虚拟机(JVM)来执行多个Map和Reduce任务。