前端时间我们生产环境SQL Server数据库有张表由于当初建表的时候把自增列的数据类型定义成int,估计当初也没有想到这张表的数据有一天会增长到超过4个子节大小的int32,由于是主键又是自增列,所以改数据库类型是肯定不现实,也不可能停数据库。所以唯一的办法就是迁移表数据到另外一张表,然后用新的表替换旧表。这是整个迁移的背景。
做这个事情其实并不复杂,通俗的讲就是把A表的数据导到B表,然后把A表表名改掉,把B表表名改成原来A表的表名。事情的达成目标就这么简单,也可以有N种方法去实现。取决于不同的因素、环境要求,选择不同的方法。这里想聊聊什么情况下:1、选择什么样的方式来做这个事情、2、有哪些实现步骤和检查步骤是必须要做的。
选择什么样的方式来做这个事情?
首先我觉得要做这个事情先要了解下面5个方面的情况,按照优先级P1P2P3... 去考虑,再决定用什么方法比较合适。
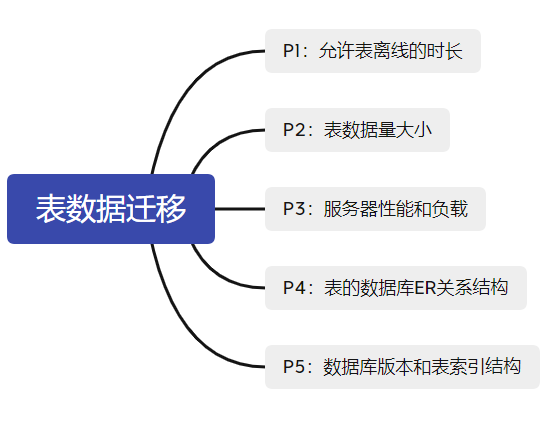
表数据迁移的5个考虑点:
P1:允许表离线的时长
每个数据库中的表都承担着应用程序端或者系统的数据存储任务,不同系统允许不同表离线的时长是不一样的,我喜欢把这个时间叫时间窗口(time window)。所以第一步是要先搞清楚表的作用?数据更新频率?。举个例子,存配置数据或者基础信息的一般数据不会受事务交易的影响,一般都是手动更新或者定时更新之类。日志类型的表一般是属于事务性质的表,但是一般只插入不更新。订单交易类型表则是会不间断更新、插入和删除。第二步是要清楚应用程序是做什么,比如ERP系统,有些ERP是生产系统,只要生产车间是7x24不停歇那就意味着表也是不间断更新。有些系统是电商平台,也是7x24。了解系统的用途,跟用户沟通争取最大的时间窗口。迁移数据虽然技术上可以做到尽可能秒级的无感切换,但是时间窗口是为自己争取部署后的验证数据以及可能发生的不确定性问题留有时间余地。所以迁移除了技术方案选择,我觉得了解系统和用户沟通同样非常重要。所以我把这个列为首要考虑因素。
P2:表数据量大小
表的数据量大小(包括索引的大小)直接决定了:1、表数据迁移的方案选择;2、表迁移的执行步骤。 基本上可以分为不同量级,十万级及以下百万计千万级亿级及以上。索引数量也是很大的影响因素,索引越多数据写入越慢,因为数据更新的时候同时也要维护索引,所带来的影响也是IO的影响,而IO通常来说是数据库面临的最大挑战。基本上通过P1和P2基本就能确定技术方案了(先不考虑后面几点的影响)。通常我觉得十万级及以下百万级千万级,只要不是核心的事务交易型的表,对在线要求不高,有一定时间窗口的(例如1小时以上这种),我觉得都可以优先选择简单一点的迁移方案。举个例子,比如某个字段类型从INT改成BIGINT,如果条件允许(不是主键,不是自增列,不是外键),表在十万级及以下百万级,可以选择直接DROP INDEX(假设字段上面有索引) + ALTER TABLE ALTER COLUMN + CREATE INDEX(假设字段上面有索引)改掉,通常来说一张千万级的表,只要服务器性能不要太差,且表也不是事务交易型的表,从我自身经历过的例子,都是30分钟内可以完成类型修改。千万级我不建议直接改数据类型,主要是如果遇到问题,回滚的时间成本太大,再者千万级对内存和IO压力也有影响。千万级亿级及以上基本是建议用新表替换旧表的形式来做。新表替换旧表也分两种,
第一种简单的就是直接 SET IDENTITY_INSERT <新表> ON; INSERT INTO ... SELECT FROM <旧表>; SET IDENTITY_INSERT <新表> OFF; CREATE INDEX ON <新表>。这种建立在千万级的表,数据量大概也就是5000万以下,表宽度小(10个字段以内,不要太多文本字段)且表索引少的情况下。这种方式最简单,先插入数据再建索引的效率也是最高。但是风险大大,回滚成本高。更多情况下建议还是 先把表和索引都建好,然后按聚集索引一个批次一个批次插入数据。后面主要讲这种方式。重点讲大表迁移。
P3:服务器性能和负载
为什么我把服务器性能和负载排第3,因为服务器性能直接决定了数据更新的性能以及对生产环境系统的影响。而数据更新的性能决定了迁移所需的时长。也会影响到执行步骤。一般来说,磁盘IO性能是最主要的考虑因素。先测试数据库连续写入10万20万30万.. 不同量级的时间,找到服务器所能承受的数据写入量级,把这个指标作为批次插入数据的大小。IO影响是很大的,SSD和HDD的插入和查询数据是两个截然不同的量级。单块SSD的连续读可以做到100MB级的连续读,20MB级的连续写。而HDD肯定是达不到这个级别的。
服务器的负载是这台机器的繁忙程度,如果服务器本身硬件资源条件就不是很好,可能是太老机器,然后还要迁移一张亿级别的表,很容易影响到生产系统的使用。例如CPU资源,如果表本身是开启了数据压缩或者列存储索引,插入数据的时候就不会触发并发,一并发就会占用数据库的线程资源,造成其他的数据库请求要等待。例如内存资源本身不多,系统又是属于混合型的系统,会有其他并发的查询任务,长时间插入数据会申请内存空间,其他的线程会等待内存资源,你会看到很多像PAGE_IO_LATCH类型的等待资源。再例如IO,这才是最可能影响的,因为对于一台数据库服务器来说,磁盘80%以上的时间使用率都是超过80%的。如果新表的索引和旧表是一个文件组或者一个磁盘下,等于插入动作要付出2倍的IO,查一遍写入一遍。你会很自然的看到Windows的性能监视器上面磁盘的使用率或者等待队列是满的。所以要适当避开服务器最繁忙的时间点,例如选在凌晨到清晨这段时间批次插入数据,白天就暂停。其次,假如是张非常大数据量的表,尽可能把新表和旧表的数据文件分开不同的磁盘存放,尽可能给新表单独一个文件组存放数据,主要是两方面的考虑,一是大表是非常占用磁盘空间,新旧表放一个磁盘很可能把磁盘撑爆,即便不撑满也够呛,不利于后面的磁盘空间利用(对于生产环境来说,磁盘可用空间高于30%才是健康)。二来,分开磁盘有利于迁移的效率,读写分开。
P4:表的数据库ER关系结构
这里有几个方面在迁移前要考虑:
1、表有没有建CDC
CDC本身不会阻止表字段改数据类型和表重命名,但是如果用新表替换掉旧表,意味着要把表的CDC关闭再重新建。CDC的作用是捕捉数据变化,一般用于ETL,关闭CDC重建会导致中间不可避免的丢失一些数据变化捕捉,这是必须要跟数据使用的一方沟通好。虽然可以把CDC重建放到切换表的事务里面,但是这样会导致事务过大,不是非不得已不建议这样做。参数可以查询[cdc].[change_tables],[cdc].[captured_columns]
关闭CDC用存储过程sys.sp_cdc_disable_table
EXECUTE sys.sp_cdc_disable_table
@source_schema = N'',
@source_name = N'',
@capture_instance = N'';
重建CDC用存储过程
EXEC sys.sp_cdc_enable_table
@source_schema = N''
, @source_name = N''
, @capture_instance = N''
, @role_name = NULL
, @supports_net_changes = 1
, @index_name = N''
, @captured_column_list = N''
, @filegroup_name = N'';
2、表有没有被数据库复制
如果表参与了数据库复制,是没办法重命名表的。数据类型虽然支持修改
3、表有没有被外键引用
如果表本身被其他表外键引用,需要先把其他表的外键约束删除,新表上线后再建外键约束。
4、表有没有触发器或者在其他表触发器被使用
如果表本身有触发器,新表上线后需要建触发器。和CDC一样,这个过程除非作为事务的一部分,否则会有遗漏数据改动的风险。
5、表有没有被架构绑定(视图、函数、存储过程)
如果表本身被作为视图视图存储过程的一部分架构绑定(WITH SCHEMA_BINDING),重命名表会报出15336的错误,需要通过下面的脚本(查找数据库表字段被哪些编程对象架构绑定了(SHEMA_BINDING))把涉及架构绑定的对象找出来,然后解除架构绑定后重命名表,再修改回架构绑定。

6、数据库有没有创建数据库镜像
(数据库快照是不影响表重命名的,例如A表重命名成B表,但是数据库快照里表还是叫A)。只不过用这个快照的脚本要注意表名,否则会报错。
P5:数据库版本和表索引结构
大表数据迁移的技术实现方法:
这里只讲千万级以上的大表的数据迁移,也就是替换表。讲到技术实现方法其实有非常多,当时我接到这个任务的时候其实已经脑海里想到不下3种实现方法,每种方法优缺点都不一样,而且最重要的是,你的客户老板看重的是表数据的可用性还是数据一致性。
可用性:秒级甚至毫秒级无感切换到新的表,数据的一致性可以稍微放宽,可以切换完表再去补全尾部的更新数据。
数据一致性:等同于事务交易,要求不能出现任何的差错,允许有一定的时间窗口。但是一旦切换表,要求切换的瞬间数据必须跟旧表保持绝对一致。
第1种: 数据库快照(Database Snapshot)+ Timestamp更新时间戳 + MERGE INTO + SP_RENAME
利用数据快照初始化数据的优势是代码量少,由于数据库快照的文件是稀疏文件,对磁盘空间的实际占用少,对初始化数据的时候比较友好,不会堵塞源表。缺点是要用到数据级别的DDL,对于已经启用了AlwaysOn高可用的环境不建议。因为在我经历过程中出现了后面删除某个数据库快照导致了高可用副本failover的情况。
首先比较建议是在初始化数据的时候是采用批量插入数据到新表,通过对聚集索引(通常都是ID),例如ID>=0 AND ID<=500000这样子去循环去插入数据,把数据写入的事务尽量不要过大,这个数量根据自己服务器的承载(主要是磁盘性能)来调整,可以慢慢一点点调整,比如先10w20w30w40w50w... 这样找到比较合适的批次数量大小。不要一次性就500w 1000w这样,数据量大如果出现问题,整个回滚的时间是不可预估的。而且过程非常消耗内存资源,会影响其他数据库的操作,尽量保持事务内数据量的大小可控。
这里还讲到了一个 Timestamp更新时间戳,Timestamp主要用在ETL同步,是以前比较老的数据同步方案,对表新增一个数据类型为timestamp的字段,并添加索引。timestamp本身不是一个基础数据类型,它以binary(8)数据类型存储从全局变量@@DB_TS获取到的值,这个全局变量每次数据增删改都会触发数值变化,所以它是并非能被转成时间或者日期,但是它可以被转成BIGINT。转成BIGINT你会观察到它是数值增长的。以前我一篇博文就讲过这个东西(基于表TIMESTAMP类型字段+NOLOCK脏读的ETL增量同步方案发现的数据遗漏问题)。这里不细说。就说Timestamp,如果表本身提供了这个数据类型且有索引的情况,那就非常利于最后尾部更新数据的同步再完成整个新旧表的切换。如果没有timestamp或者没有索引的情况下,这个方案就坐不了,因为后面初始化完要做增量,必须要求得能有字段提供增量查询。那就直接选择下面的其他方案就行了。
最后SP_RENAME就简单了,开启事务,然后补尾部数据,然后直接两次重命名表,然后提交事务。对离线时间有要求的,尽可能让事务时间短,保持简单的逻辑。做之前要对事务每个语句的执行时间有心理预期。这个原则适用于任何一种方案。
下面是步骤:
步骤1:创建文件组
步骤2:创建分区函数和方案
步骤3:创建新表
步骤4:创建数据库快照并初始化新表的数据
步骤5:创建新表的索引和触发器
步骤6:增量同步初始化以后发生改变以及新增的数据(新的快照)
步骤7:增量同步尾部的数据并用重命名新表
第2种:CDC(Change Data Capture) + MERGE INTO + SP_RENAME
CDC就不用多说了,我记得是SQL SERVER 2008版本以后才有的CDC,而且应该它是所有SQL SERVER的数据库版本都支持的(2008以后的版本),包括Linux 2017和2019也支持了CDC。技术上我觉得比较成熟,非常契合数据更新。之前有篇博文也写了关于数据迁移的事情(谈表数据迁移时,先建索引再插入数据,还是先插入数据再建索引的问题)。
步骤1:Day1 创建新表
步骤2:Day1 创建新表的索引和触发器
步骤3:Day1 创建旧表CDC并50w一个批次初始化新表的数据
步骤4.1:Day2 从CDC表数据增量MERGE数据到新表
步骤4.2:Day2 从CDC表数据增量再从上次增量往后增量MERGE数据到新表
步骤5:Day2 增量同步尾部的数据MERGE并用重命名新表
第3种:TIMESTAMP + MERGE INTO + SP_RENAME
这种就比较纯粹,就是TIMESTAMP增量MERGE,但是要求TIMESTAMP字段是加了索引,否则后面做增量的时候没办法快速查出数据。