一、简介
Apache Solr是基于Lucene的全文搜索引擎。如何让Solr具有容错性和高可用性,SolrCloud可以帮助我们搭建集群,提供分布式索引,以及自动备份。SolrCloud是Solr的一种分布式部署方式。它使用Zookeeper作为集群的配置信息中心,进行节点的管理。在创建索引时,Solr将索引分散存储在集群中,以及备份服务器中。当需要检索信息时,Solr将查询的最终结果返回给客户端。
SolrCloud具有以下特性:
- Solr的整个集群具有一个配置中心
- 能够自动进行负载平衡和故障查询
- 集成Zookeeper进行集群的协调和配置
二、SolrCloud的基本概念
SolrCloud包括的核心概念有:Cluster、Node、Collection、Shard、Replica、Core等。
1、Cluster集群
从逻辑上讲,一个Cluster包括一个或者多个Solr Collection;从物理上讲,一个Cluster由一个或者多个Solr Nodes。整个集群必须使用同一套schema和SolrCongfig。
2、Node节点
运行Solr的JVM实例,其中包括了一个或者多个Core。
3、Collection
从逻辑上讲,Collection是一个完整的索引,它被划分成一个或者多个Shard。如果Shard数量是一个以上的话,那么使用的索引方案则是分布式索引。这些Shard使用同一个configset。使用SolrCloud方式部署时,客户端发送请求时,使用Collection名称进行操作。这样客户端在分布式检索时,不用关心相关的Shard参数。
4、Shard分片
Shard是Collection的逻辑分片。一个Shard包含了一个或者以上的Replica。
5、Replica
在Solr文档中描述:Each Core in a Cluster is a physical Replica for a logical Shard。可以理解为,一个Replica就是一个core。一个Shard中有一个或者以上的Replica,当有多个Replica时,zookeeper会选举一个Replica成为Leader。当进行检索时,SolrCloud会将请求发送到Shard对应的Leader,Leader再将请求分到达Shard中的其他Replica,用以备份。Leader的选举通常是在Solr的某一个实例发生故障时才会触发。
6、Core
在Solr中,一个Core就是一个完整的索引,可以独立的提供索引和检索功能,其配置文件在相应的Core文件夹配置目录中。在SolrCloud中,一个Core就是一个Replica,其使用的配置都在zookeeper中。
7、Zookeeper
Zookeeper是分布式服务框架,主要解决分布式集群中应用系统的一致性问题,它具有集群管理、分布式应用配置配置项的管理、统一命名服务、状态同步等功能。在SolrCloud中,可以使用内嵌的Zookeeper,也可以用独立的Zookeeper运行。在搭建Zookeeper集群时,最好搭建三个以上的奇数个实例。这是因为Zookeeper大多数的操作都是以投票进行。当且仅当一半以上的节点在线时,这个集群才能保持运行。例如,Zookeeper总共有4个节点,如果保持运行,最多只能一个节点出现故障。如果总共有3个节点,保持运行,最多也是一个节点出现故障。
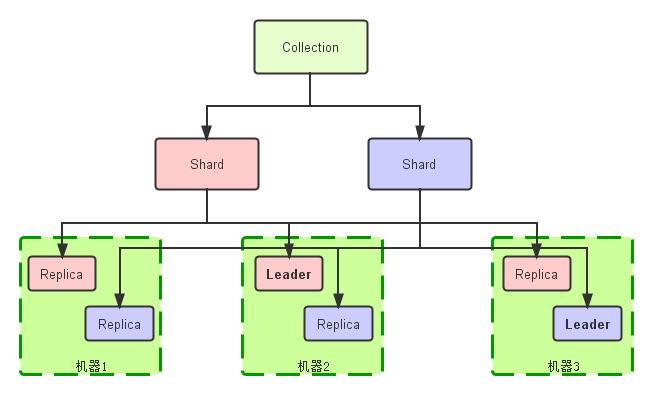
【SolrCloud中的Collection图】
三、SolrCloud配置(zookeeper-3.4.6,solr-5.4.0)
(一)Zookeeper集群搭建
1、修改zookeeper的配置文件(<ZOOKEEPER_HOME>/conf/zoo.cfg),添加以下信息:
tickTime=2000
dataDir=D:\solrcloud\zookeeper3\data
clientPort=2181
initLimit=5
syncLimit=2
server.1=localhost:2888:3888
server.2=localhost:2889:3889
server.3=localhost:2890:3890
- tickTime:这个时间是作为 Zookeeper 服务器之间维持心跳的时间间隔(以毫秒为单位),也就是每个 tickTime 时间就会发送一个心跳。
- dataDir:Zookeeper存放数据的目录。在默认情况下,这个目录也是Zookeeper保存写数据的日志文件。在搭建Zookeeper集群时,这个目录也是存放节点ID文件(myid)的地方。
- clientPort:客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求。
- initLimit:初始化连接时最长能忍受的的心跳时间间隔数。例如:在本例中,当超过5个心跳时间(总时间:5*2000=10s),若Zookeeper集群中的Leader服务器还没有收到Follower服务器的返回信息,则表明连接失败。
- syncLimit:Leader和Follower之间通信的时间长度不能超过2个心跳时间(总时间:2*2000=4s)
- server.A=B:C:D:
A:表示Zookeeper服务器编号(Id)。注意,此Id与myid文件中的编号要一致,Id的范围是1-255的整数。myid文件放在【dataDir】下。
B:服务器ip地址
C:这个服务器与集群中的Leader服务器交换信息的端口
D:选举Leader服务器时的通信端口。如果Leader服务器发生故障挂了,新Leader的选举在这个端口进行。
(本文中,搭建的是伪集群,因此B是相同的,通信端口不能一样。)
分别在zookeeper的其他两个实例中,按照上述配置修改zoo.cfg文件。
2、分别运行服务。
cd <ZOOKEEPER1_HOME> binzkServer.cmd cd <ZOOKEEPER2_HOME> binzkServer.cmd cd <ZOOKEEPER3_HOME> binzkServer.cmd
当这些配置项配置好后,你现在就可以启动 Zookeeper 了,启动后要检查 Zookeeper 是否已经在服务,可以通过 netstat – ano 命令查看是否有你配置的 clientPort 端口号在监听服务。
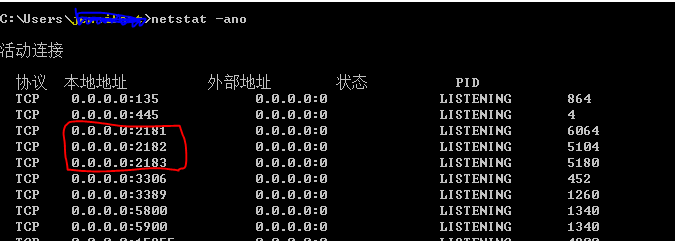
还可以通过“bin/zkServer.sh status”命令查看状态,不过在windows上,zkServer.cmd跟参数时会报错,只能在Linux的环境上操作了。
(二)SolrCloud配置
1、创建节点
创建节点目录。例如<SOLR_HOME>/example/cloud/node1/solr。一种方式是:在该目录下,添加solr.xml文件。
另一种是将solr.xml上传至zookeeper服务器方式:使用solr-core里的ZkCLI工具。
java -classpath <SOLR_HOME>/server/solr-webapp/webapp/WEB-INF/lib/* org.apache.solr.cloud.ZkCLI -zkhost localhost:2181,localhost:2182,localhost:2183 -cmd putfile /solr.xml <SOLR_HOME>/server/solr/solr.xml
putfile后,第一个参数是:zookeeper集群上的存储路径,第二个参数是:要上传文件的本地路径;如果zookeeper集群中该文件已存在,则会报错,不能覆盖。(查询zkcli相关参数设置:https://cwiki.apache.org/confluence/display/solr/Command+Line+Utilities)
个人更喜欢第二种方式。第一种方式,每创建一个节点,需要添加一个solr.xml文件,这样的方式不利于集群的管理。第二种方式是将这个文件上传到Zookeeper中统一管理,无需多上传。
测试搭建的是伪集群,在【cloud】文件夹下,创建了node2, node3两个节点
2、将创建的节点注册到zookeeper的/live_nodes目录下
binsolr.cmd start -cloud -s examplecloud
ode1solr -p 8981 -z "localhost:2181,localhost:2182,localhost:2183"
binsolr.cmd start -cloud -s examplecloud
ode2solr -p 8982 -z "localhost:2181,localhost:2182,localhost:2183"
binsolr.cmd start -cloud -s examplecloud
ode3solr -p 8983 -z "localhost:2181,localhost:2182,localhost:2183"
当以上命令不能获取正确的IP时(例如solr节点部署在虚拟机上等情况),可以在命令中加入[-h host]参数,指定ip。(查询启动solr的相关参数设置:binsolr.cmd start -help)
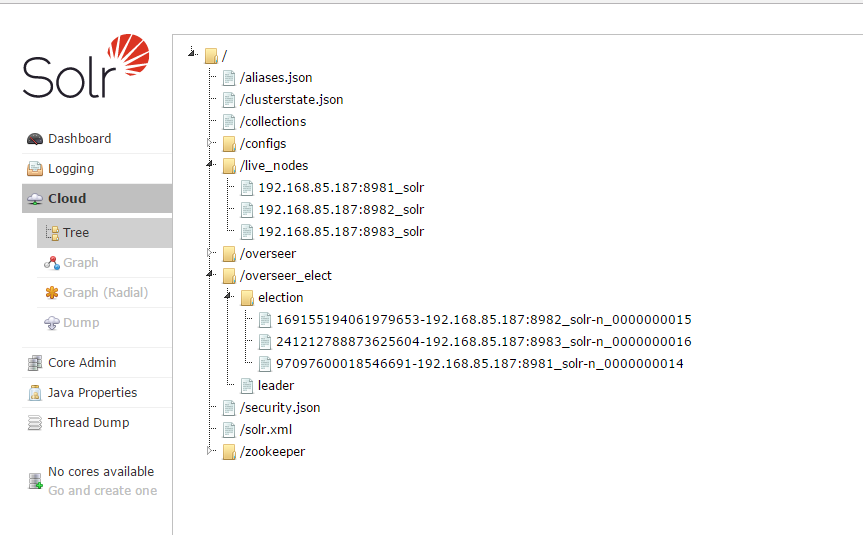
在将创建的节点注册到zookeeper之后,本机会从zookeeper中更新集群状态信息,保持信息一致。zookeeper中会在overseer_elect/election中新建一个节点,为Leader选举做准备。如果第一个在集群中创建的solr服务,该节点注册之后,在zookeeper会创建/overseer_elect/leader。
在启动Solr之后,solr cloud中的树形目录如下:
3、上传configs到zookeeper
有两种方式可以将configs文件上传到zookeeper,即ZkCLI工具或者SolrJ。
(1)使用solr-core里的ZkCLI工具。
java -classpath <SOLR_HOME>/server/solr-webapp/webapp/WEB-INF/lib/* org.apache.solr.cloud.ZkCLI -zkhost localhost:2181,localhost:2182,localhost:2183 -cmd upconfig -confname my_dih_conf -confdir <SOLR_HOME>serversolrconfigsetsmy_dih_configsconf
upconfig后,第一个参数是:zookeeper集群上的configs名称,第二个参数是:要上传conf的本地路径;
(2)使用SolrJ
调用CloudSolrClient.uploadConfig方法
(ConfigSets API可以对zookeeper服务器中的configset进行管理,API接口详细说明:https://cwiki.apache.org/confluence/display/solr/ConfigSets+API)
solr配置文件上传后,如图:

(4)创建Collection
对Collection的操作可以直接使用Solr Collections API,详细说明:https://cwiki.apache.org/confluence/display/solr/Collections+API (也可以使用SolrJ的方式)
http://localhost:8981/solr/admin/collections?action=CREATE&name=mycollection&router.name=implicit&shards=shard1,shard2&replicationFactor=3&maxShardsPerNode=3&createNodeSet=192.168.85.187:8981_solr,192.168.85.187:8982_solr,192.168.85.187:8983_solr&collection.configName=my_dih_conf
到此,solrcloud的搭建完成。通过http://localhost:8981/solr/admin/collections?action=clusterstatus&wt=json可以查询solr集群的状态。或者通过solrcloud查询,如图:
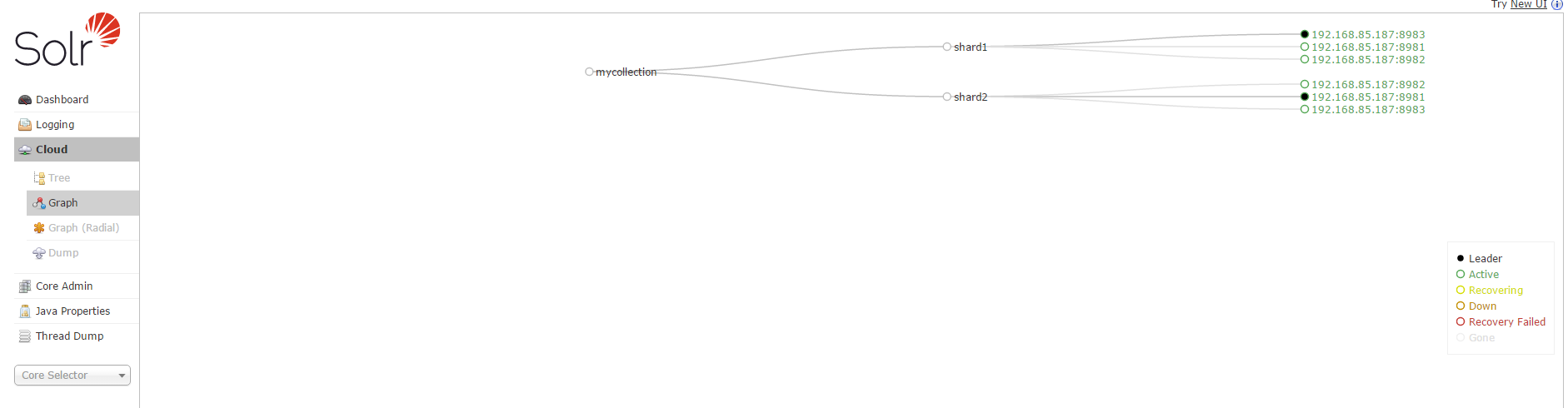
从图中可以看出,在shard1中,8983端口的solr服务为主节点;在shard2中8981端口的solr服务为主节点。
(5)测试
本文使用的config为DIH的配置方式。在任意一个solr服务器上创建索引之后,都会自动同步到另外两个solr服务器。
使用url进行数据访问:http://localhost:8981/solr/mycollection/select?q=*%3A*&wt=json&indent=true

通过SolrJ检索:
maven配置:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.test</groupId> <artifactId>test</artifactId> <packaging>pom</packaging> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.5</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.5</version> </dependency> <dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-solrj</artifactId> <version>6.2.0</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.3</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> </plugins> </build> </project>
SolrJ查询:
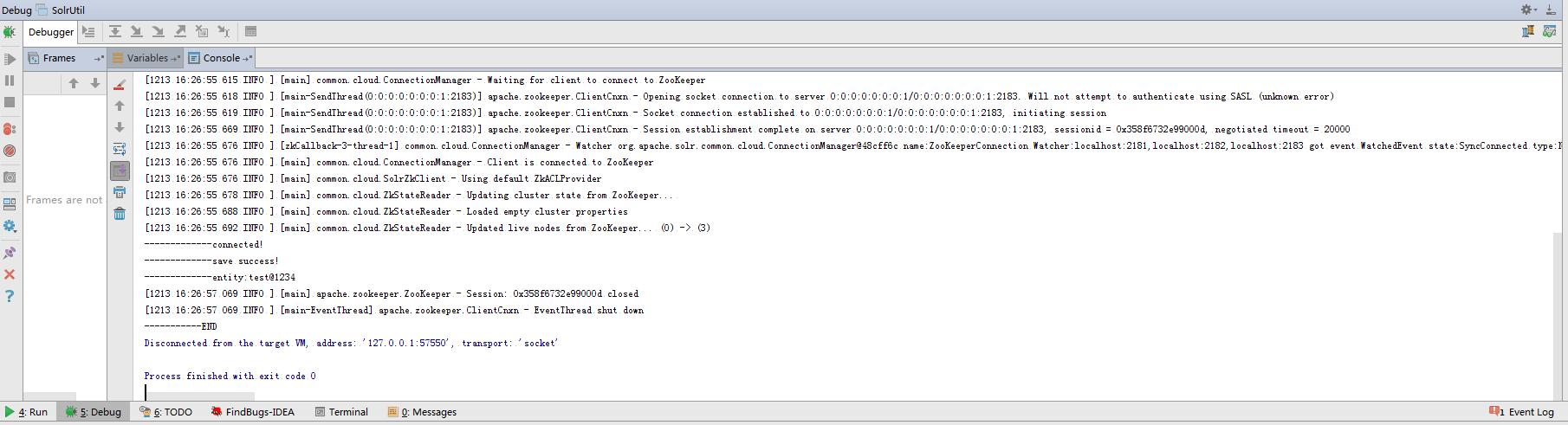
public static void main(String[] args) { CloudSolrClient client = null; try { CloudSolrClient.Builder builder = new CloudSolrClient.Builder(); builder.withZkHost("localhost:2181,localhost:2182,localhost:2183"); client = builder.build(); client.setDefaultCollection("mycollection"); client.setZkClientTimeout(20000); client.setZkConnectTimeout(1000); client.setParser(new XMLResponseParser()); client.connect(); System.out.println("-------------connected!"); //Indexing(创建索引,可以用SolrInputDocument对象或者实体类创建对象。实例中的SocialContactEntity类与业务相关,继承BaseSolrEntity) String queryString = "test@1234"; SocialContactEntity entity = new SocialContactEntity(); entity.setUuid(UUID.randomUUID().toString()); entity.setName("test"); entity.setName_standard("test-standard"); entity.setAccount(queryString); client.addBean(entity); client.commit();//提交修改 System.out.println("-------------save success!"); //query SolrQuery query = new SolrQuery(); query.set("q", "account:" + queryString); QueryResponse response = client.query(query); SolrDocumentList list = response.getResults(); Iterator iterator = list.iterator(); while (iterator.hasNext()) { Map contactEntity = (Map) iterator.next(); System.out.println("-------------entity:" + contactEntity.get("account")); } client.close(); System.out.println("-----------END"); } catch (IOException e) { e.printStackTrace(); } catch (SolrServerException e) { e.printStackTrace(); } finally { if (client != null) { try { client.close(); } catch (IOException e) { e.printStackTrace(); } } } }
输出结果:
参考文献:
http://josh-persistence.iteye.com/blog/2234411
http://www.cnblogs.com/shanyou/p/3221990.html
https://cwiki.apache.org/confluence/display/solr/SolrCloud