前言
Elasticsearch 存储的基本单元是shard, ES中一个Index 可能分为多个shard, 事实上每个shard 都是一个Lucence 的Index,并且每个Lucence Index 由多个Segment组成, 每个Segment事实上是一些倒排索引的集合, 每次创建一个新的Document, 都会归属于一个新的Segment, 而不会去修改原来的Segment; 且每次的文档删除操作,会仅仅标记Segment中该文档为删除状态,而不会真正的立马物理删除, 所以说ES的index 可以理解为一个抽象的概念。
- index:类似数据库,是存储、索引数据的地方
- shard:index 由 shard 组成,一个 primary shard,其他是 replica shard
- segment:shard 包含 segment,segment 内的文档数量的上限是 2^31
- 倒排索引:是 Lucene 中用于使数据可搜索的数据结构,存储在segment中
- translog:也称“事务日志”,提供所有还没有被刷到磁盘的操作的一个持久化纪录
- commit point:列出所有已知 segment 的文件及一个.del文件
一个 Elasticsearch Index 由一个或者多个 shard (分片) 组成。

而 Lucene 中的 Lucene index 相当于 ES 的一个 shard。

数据持久化过程

整体流程:
- 数据首先写入内存缓存区和Translog日志文件中。当你写一条数据doc的时候,一方面写入到内存缓冲区中,一方面同时写入到Translog日志文件中。
- 内存缓存区满了或者每隔1秒(默认1秒),refresh将内存缓存区的数据生成index segment文件并写入文件系统缓存区,此时index segment可被打开以供search查询读取,这样文档就可以被搜索到了(注意,此时文档还没有写到磁盘上);然后清空内存缓存区供后续使用。可见,refresh实现的是文档从内存缓存区移到文件系统缓存区的过程。
- 重复上两个步骤,新的segment不断添加到文件系统缓存区,内存缓存区不断被清空,而translog的数据不断增加,随着时间的推移,Translog文件会越来越大。
- 当Translog长度达到一定程度的时候,会触发flush操作,否则默认每隔30分钟也会定时flush,其主要过程:
- 执行refresh操作将内存缓存区中的数据写入到新的segment并写入文件系统缓存区,然后打开本segment以供search使用,最后再次清空内存缓存区。
- 一个commit point被写入磁盘,这个commit point中标明所有的index segment。
- 文件系统中缓存的所有的index segment文件被fsync强制刷到磁盘,当index segment被fsync强制刷到磁盘上以后,就会被打开,供查询使用。
- translog被清空和删除,创建一个新的translog。
- Refresh
- 先写入内存 buffer(这时数据是搜索不到的),同时将数据写入 translog 日志文件。每个shard都对应一个translog文件。
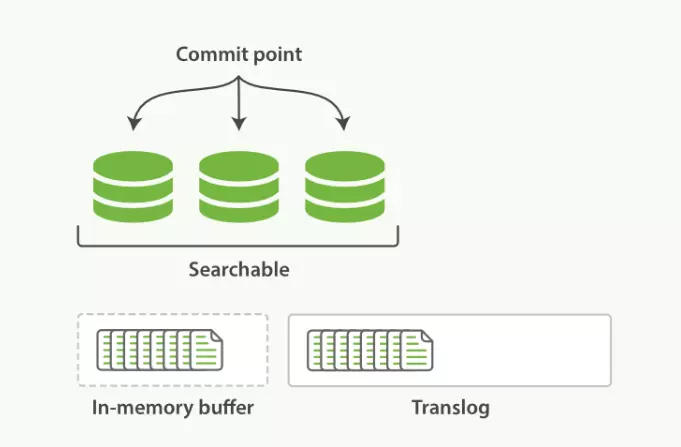
如果内存 buffer 快满了或者到一定时间(1秒),将内存buffer 数据 refresh 到文件 cache 即文件缓存区。这时数据就可以被搜索到了:
- 内存缓存区的文档被写入到一个新的 segment 中;
- 新的segment 被打开以供搜索;
- 内存缓存区清空;
总结:Refresh操作默认每秒执行一次, 将内存缓存区的数据写入到文件缓存区的一个新的Segment中,同时清空内存缓存区。这个时候索引变成了可被检索的。
Elasticsearch 中,默认情况下 _refresh 操作设置为每秒执行一次,可以通过参数index.refresh_interval来修改这个刷新间隔,refresh的开销比较大,因此在批量构建索引时可以把refresh间隔设置成-1来临时关闭refresh,等到索引都提交完成之后再打开refresh,可以通过如下接口修改这个参数:
curl -XPUT 'localhost:9200/test/_settings' -d '{
"index" : {
"refresh_interval" : "-1"
}
}'
POST /_refresh 刷新(Refresh)所有的索引。
POST /blogs/_refresh 只刷新(Refresh) blogs 索引。
备注:
refresh_interval 需要一个 持续时间值, 例如 1s (1 秒) 或 2m (2 分钟)。 一个绝对值 1 表示的是 1毫秒 --无疑会使你的集群陷入瘫痪。
通常 buffer 里的内容被写入到 Segment 里去,有三个条件:
- 由索引中的设置所指定的 refresh_interval 启动的周期性的 refresh。在默认的情况下为1s
- 在导入文档时强制 refresh:PUT twitter/_doc/1?refresh=true
- 当 In Memory Buffer 满了,在默认的情况下为 node Heap 的 10%
另外当你在做批量索引时,可以考虑把副本数设置成0,因为document从主分片(primary shard)复制到从分片(replica shard)时,副本分片也要执行相同的分析、索引和合并过程,这样的开销比较大,你可以在构建索引之后再开启副本,这样只需要把数据从主分片拷贝到从分片:
curl -XPUT 'localhost:9200/my_index/_settings' -d ' {
"index" : {
"number_of_replicas" : 0
}
}'
执行完批量索引之后,把刷新间隔改回来:
curl -XPUT 'localhost:9200/my_index/_settings' -d '{
"index" : {
"refresh_interval" : "1s"
}
}'
你还可以强制执行一次refresh以及索引分段的合并:
curl -XPOST 'localhost:9200/my_index/_refresh'
curl -XPOST 'localhost:9200/my_index/_forcemerge?max_num_segments=5'
尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候, 手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。 相反,你的应用需要意识到 Elasticsearch 的近实时的性质,并接受它的不足。
Flush
每隔 1 秒钟,es 将 buffer 中的数据写入一个新的 segment file ,每秒钟会产生一个新的磁盘文件 segment file ,这个 segment file 中就存储最近 1 秒内 buffer 中写入的数据。但是如果 buffer 里面此时没有数据,那当然不会执行 refresh 操作,如果 buffer 里面有数据,默认 1 秒钟执行一次 refresh 操作,刷入一个新的 segment file 中。
文件缓存区:系统自动在内存区中为程序每一个正在使用的文件开辟开辟一个文件缓存区,从内存向磁盘输出时必须优先充满文件缓存区后,数据才会被一起送到磁盘。
文件缓冲区是用以暂时存放读写期间的文件数据而在内存区预留的一定空间。使用文件缓冲区可减少读取硬盘的次数
为什么叫 es 是准实时的:NRT,全称near real-time。默认是每隔 1 秒 refresh 一次的,所以 es 是准实时的,因为写入的数据 1 秒之后才能被看到。可以通过 es 的restful api或者java api,手动执行一次 refresh 操作,就是手动将 buffer 中的数据刷入os cache中,让数据立马就可以被搜索到。只要数据被输入os cache中,buffer 就会被清空了,因为不需要保留 buffer 了,数据在 translog 里面已经持久化到磁盘去一份了。
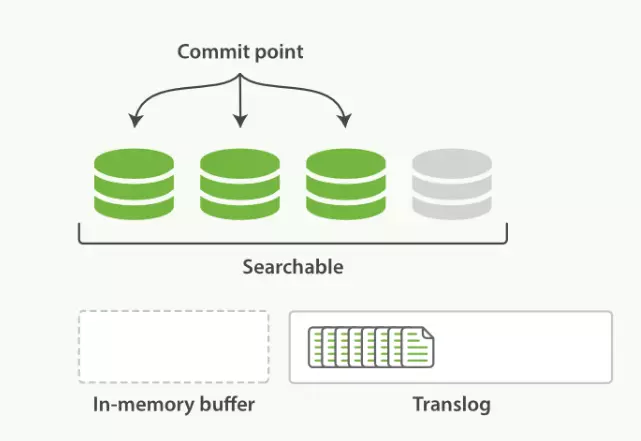
重复上面的步骤,新的数据不断进入 buffer 和 translog,不断将 buffer 数据写入一个又一个新的 segment file 中去,每次 refresh 完 buffer 清空,translog 保留。随着这个过程推进,translog 会变得越来越大。当 translog 达到一定长度的时候,就会触发 commit 操作。commit 操作发生第一步,就是将 buffer 中现有数据 refresh 到 os cache 中去,清空 buffer。然后,将一个 commit point 写入磁盘文件,里面标识着这个 commit point 对应的所有 segment file ,同时强行将 os cache 中目前所有的数据都 fsync 到磁盘文件中去。最后清空现有 translog 日志文件,重启一个 translog,此时 commit 操作完成。这个 commit 操作叫做 flush 。默认 30 分钟自动执行一次 flush ,但如果 translog 过大,也会触发 flush 。flush 操作就对应着 commit 的全过程,我们可以通过 Es api,手动执行 flush 操作,将 os cache 中的数据 fsync 强刷到磁盘上去。
当translog达到一定长度(默认512m)的时候或者30分钟之后,就会触发flush操作(flush 完成了 Lucene 的 commit 操作):
- 第一步将 内存缓存区 中现有数据 refresh 到 文件缓存区 中去,清空 内存缓存区;
- 然后,将一个 commit point 写入磁盘文件,同时强行将 文件缓存区 中目前所有的数据都 fsync 到磁盘文件中去;
- 最后清空现有 translog 日志文件并重建一个。
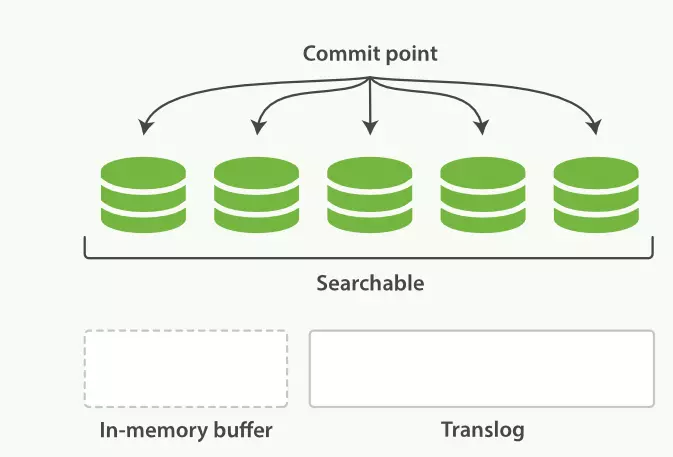
commit point:记录当前所有可用的segment,每个commit point都会维护一个.del文件(es删除数据本质是不属于物理删除),当es做删改操作时首先会在.del文件中声明某个document已经被删除,文件内记录了在某个segment内某个文档已经被删除,当查询请求过来时在segment中被删除的文件是能够查出来的,但是当返回结果时会根据commit point维护的那个.del文件把已经删除的文档过滤掉。
数据写入 segment file 之后,同时就建立好了倒排索引,其实就是refresh之后就建立好倒排索引了。
总结:Flush 操作将内存缓存区的数据全都写入文件缓存区新的Segments中, 并将文件缓存区中所有的Segments全部刷盘, 并且清空translog日志的过程。
每个 Shard 中都存在一个 translog,这意味着它与物理磁盘内存有关。 它是同步且安全的,因此即使对于尚未提交的文档,您也可以获得持久性。 如果发生问题,可以还原事务日志。 同样,在每个设置的时间间隔内,或在成功完成请求(索引,批量,删除或更新)后,将事务日志提交到磁盘。translog 提供所有还没有被刷到磁盘的操作的一个持久化纪录。当 Elasticsearch 启动的时候, 它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
这个执行一个提交并且截断 translog 的行为在 Elasticsearch 被称作一次 flush 。 分片每30分钟被自动刷新(flush),或者在 translog 太大的时候也会刷新。请查看 translog 文档 来设置,它可以用来 控制这些阈值:
flush API 可以被用来执行一个手工的刷新(flush):
POST /blogs/_flush # 刷新(flush) blogs 索引。
POST /_flush?wait_for_ongoing # 刷新(flush)所有的索引并且等待所有刷新在返回前完成。
translog 每 5s 刷新一次磁盘,所以故障重启,可能会丢失 5s 的数据。
translog 执行 flush 操作,默认 30 分钟一次,或者 translog 太大 也会执行。
注意:你很少需要自己手动执行 flush 操作;通常情况下,自动刷新就足够了。
这就是说,在重启节点或关闭索引之前执行flush有益于你的索引。当 Elasticsearch 尝试恢复或重新打开一个索引, 它需要重放 translog 中所有的操作,所以如果日志越短,恢复越快。
Es有几个条件来决定是否flush到磁盘,不同版本的es参数有所不同,大家可以参考es对应版本的文档来查看这几个参数:es translog,这里介绍下1.7版本的flush参数:
index.translog.flush_threshold_ops,执行多少次操作后执行一次flush,默认无限制
index.translog.flush_threshold_size,translog的大小超过这个参数后flush,默认512mb
index.translog.flush_threshold_period,多长时间强制flush一次,默认30m
index.translog.interval,es多久去检测一次translog是否满足flush条件
Translog
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-translog.html
- 同步间隔(index.translog.sync_interval):Translog的日志每次都会写入到操作系统的缓存中,只有执行fsync刷盘后才是安全的。因此ES会每隔一段时间执行fsync刷盘。默认时间间隔是5s,最低不能低于100ms。注:该参数只针对异步落盘方式才生效。
- 刷盘方式(index.translog.durability):Translog的刷盘方式有两种:同步(request)和异步(async)ES默认使用的是request,即每次写入、更新、删除操作后立刻执行fsync落盘。如果使用异步的方式,则根据同步间隔周期性的刷盘。两种方式各有千秋,同步刷盘具备更强数据可靠性保障,但同时带来更高的IO开销,性能更低。异步刷盘牺牲了一定的可靠性保障,但是降低了IO的开销,性能更佳,因此需要根据不同的场景需求选择合适的方式。
- 大小阈值(index.translog.flush_threshold_size):我们不可能让translog的大小无限增长(内存)。translog的大小过大会带来如下问题:占用磁盘空间;节点恢复需要同步translog回放日志,如果太大会导致恢复时间过长。因此,需要设定一个阈值,当日志量达到该阈值时,触发flush,生成一个新的提交点,提交点之前的日志便可以删除了(具体能否删除还需结合日志的保留时长和保留大小而定)。
- 日志保留大小(index.translog.retention.size):它控制为每个分片保留的translog文件的总大小(磁盘)。保留更多的translog文件可以增加在恢复副本时执行基于操作的同步的机会。如果translog文件不够,副本恢复将退回到基于文件的同步。默认为512mb。如果启用了软删除,此设置将被忽略,并且不应设置。默认情况下,在Elasticsearch7.0.0及更高版本中创建的索引中启用软删除。
- 日志保留时长(index.translog.retention.age):它控制每个分片保存translog文件的最大持续时间(磁盘)。保留更多的translog文件可以增加在恢复副本时执行基于同步操作的机会。如果translog文件不够,副本恢复将退回到基于文件的同步。默认为12h。如果启用了软删除,此设置将被忽略,并且不应设置。默认情况下,在Elasticsearch7.0.0及更高版本中创建的索引中启用软删除。
- 日志generation阈值大小(index.translog.generation_threshold_size):为了避免translog越来越大,增加恢复的时间。在translog达到阈值时,会执行flush,触发lucenecommit,并滚动translog生成新的文件,当前generation前的操作数据都会提交到lucene持久化,恢复时,只需恢复当前translog中的操作即可。
Elasticsearch采用另一种方法来解决持久性问题。它在每个分片中引入一个事务日志(transactionlog)。已建立索引的新文档将传递到此事务日志和内存缓冲区中。此处可以联想Mysql的binlog,ES中也存在一个translog用来失败恢复。translog文件中存储了上一次flush(即上一个commitpoint)到当前时间的所有数据的变更记录——即translog中存储的是还没有被刷到磁盘的所有最新变更记录。
- Document不断写入到In-memorybuffer,此时也会追加translog。
- 当buffer中的数据每秒refresh到cache中时,translog并没有进入到刷新到磁盘,是持续追加的。
- translog每隔5s会fsync到磁盘。
- translog会继续累加变得越来越大,当translog大到一定程度或者每隔一段时间,会执行flush。
"translog": { "generation_threshold_size": "64mb", # 超过该阈值会产生新的 translog 文件 "flush_threshold_size": "512mb", # 可以适当调大,但不能超过 indexBufferSize*1.5 倍,否则会触发限流,并导致 JVM 内存不释放 "sync_interval": "5s", # 同步 "retention": { "size": "512mb", "age": "12h" }, "durability": "REQUEST" # 每次请求执行一次flush }
translog 其实也是先写入 os cache 的,默认每隔 5 秒刷一次到磁盘中去,所以默认情况下,可能有 5 秒的数据会仅仅停留在 buffer 或者 translog 文件的 os cache 中,如果此时机器挂了,会丢失 5 秒钟的数据。但是这样性能比较好,最多丢 5 秒的数据。也可以将 translog 设置成每次写操作必须是直接 fsync 到磁盘,但是性能会差很多。
默认情况下,如果index.translog.durability被设置为async的话,Elasticsearch每5秒钟同步并提交一次translog。或者如果被设置为request(默认)的话,每次index,delete,update,bulk请求时就同步一次translog。更准确地说,如果设置为request, Elasticsearch只会在成功地在主分片和每个已分配的副本分片上fsync并提交translog之后,才会向客户端报告index、delete、update、bulk成功。
PUT /my_index/_settings { "index.translog.durability": "async", # 异步 这个参数有2个取值:request(每次请求都执行fsync,es要等translog fsync到磁盘后才会返回成功)和async(translog每隔5秒钟fsync一次) "index.translog.sync_interval": "5s" # 控制translog多久fsync到磁盘,最小为100ms }
这个选项可以针对索引单独设置,并且可以动态进行修改。如果你决定使用异步 translog 的话,你需要 保证 在发生crash时,丢掉 sync_interval 时间段的数据也无所谓。请在决定前知晓这个特性。
由于translog是追加写入,因此性能要比随机写入要好。与传统的分布式系统不同,这里是先写入Lucene再写入translog,原因是写入Lucene可能会失败,为了减少写入失败回滚的复杂度,因此先写入Lucene。
软删除
软删除在最新版本中创建的索引上默认启用,但是可以在创建索引时显式启用或禁用软删除。如果禁用了软删除,那么有时仍然可以通过从translog中复制丢失的操作来进行对等恢复,只要这些操作保留在translog中。如果禁用软删除,则跨集群复制将不起作用。
index.soft_deletes.enabled
在7.6.0弃用。禁用软删除创建索引已被弃用,并将在未来的Elasticsearch版本中删除。指示是否对索引启用软删除。软删除只能在创建索引时配置,并且只能在Elasticsearch 6.5.0上或之后创建的索引上配置。默认值为true。
如果一个索引没有使用软删除来保留历史操作,那么Elasticsearch通过重放主节点的translog操作来恢复每个副本分片。这意味着对于主节点来说,在它的translog中保留额外的操作是很重要的,以防它需要重建一个副本。此外,重要的是每个副本在其translog中保留额外的操作,以防它被提升为主副本,然后需要依次重建自己的副本。
Merge
我们已经知道在elasticsearch中每个shard每隔1秒都会refresh一次,每次refresh都会生成一个新的segment,按照这个速度过不了多久segment的数量就会爆炸,所以存在太多的segment是一个大问题,因为每一个segment都会占用文件句柄,内存资源,cpu资源,更加重要的是每一个搜索请求都必须访问每一个segment,这就意味着存在的segment越多,搜索请求就会变的更慢。
为什么要这么麻烦进行段合并?
- 首先,索引中存在的段越多,搜索响应速度就会越慢,内存占用也会越大。
- 此外,段文件是无法改动的,因此段数据信息不会删除。如果恰好删除了索引中的很多文档,在索引合并之前,这些文档只是标记删除,并非物理删除。因此,当段合并时,标记删除的文档不会写入到新的段中,通过这种方式实现真正的删除,并缩减了段数据的大小。
从用户的角度,段合并将产生以下两种影响:
- 当几个段合并成一个段时,通过减少段的数量提升了搜索的性能
- 段合并完成后,索引大小会由于标记删除转成物理删除而有所缩减
要记住段合并也是有开销的:段合并引|起的I/O操作可能会使系统变慢从而影响性能。
Segment merge操作对系统的IO和内存占用都比较高,从Es2.0开始,merge行为不再由Es控制,而是由Lucene控制。尽管段合并是Lucene的责任,ElasticSearch也允许用户配置想用的段合并策略。到目前为止,有三种可用的合并策略:
- tiered(默认-分层合并策略)
- log_byte_size(字节大小对数合并策略)
- log_doc(文档数量对数合并策略)
配置合并策略:修改elasticsearch.yml
配置文件的index.merge.policy.type字段配置成我们期望的段合并策略类型(创建之后不可更改)。例如下面这样:
index.merge.policy.type:tiered
内存缓存区 每 refresh 一次,就会产生一个 segment(默认情况下是 1 秒钟产生一个),这样 segment 会越来越多,为了解决这个问题,ES 会不断在后台运行任务,主动将这些零散的 segment 做数据归并,尽量让索引内只保有少量的,每个都比较大的segment 文件。这个过程是有独立的线程来进行的,并不影响新 segment 的产生。合并的segment可以是磁盘上已经commit过的索引,也可以在内存中还未commit的segment。
- 将多个 segment 合并成一个,并将新的 segment 写入磁盘;
- 新增一个 commit point,标识所有新的 segment;
- 新的 segment 被打开供搜索使用;
- 删除旧的 segment。
归并过程中,尚未完成的较大的 segment 是被排除在检索可见范围之外的。当归并完成,较大的这个 segment 刷到磁盘后,commit 文件做出相应变更,等检索请求都从小 segment 转到大segment 上以后,删除没用的小 segment,改成新的大 segment。这时候,索引里 segment 数量就下降了。
POST index/_forcemerge?only_expunge_deletes=true
merge过程也是文档删除和更新操作后,旧的doc真正被删除的时候。还可以手动调用_forcemerge API来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。
总结:merge能够通过减少segment数量来提高搜索速度。但是merge的过程会对索引吞吐量及搜索速度有一定的影响,因此需要配置适当的合并策略参数。对于资源不足的环境,最好禁止自动merge,选择空闲时段手动进行merge。
缓存
参考博客:https://cloud.tencent.com/developer/article/1765827