MongoDB复制集相关概念
- 为什么要使用使用分布式的节点恢复
数据库总是会遇到各种宕机场景,如断电断网等。尽管日志功能也提供了数据恢复的功能,但它通常是针对单个节点来说的,只能保证单节点数据的一致性。
- 什么是 复制集(replica Set)
由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据通过上述方式来保持复制集内所有成员存储相同的数据集,提供数据的高可用性。而且只有Primary节点有写入的功能,开发的时候需要注意重新选举主节点,做出异常处理(更换主机和端口)。
- 复制集(replica Set)主要作用
- Failover (故障转移,故障切换,故障恢复)
- Redundancy(数据冗余)
- 避免单点,用于灾难时恢复,报表处理,提升数据可用性
- 读写分离,分担读压力
- 对用户透明的系统维护升级
MongoDB复制集的原理
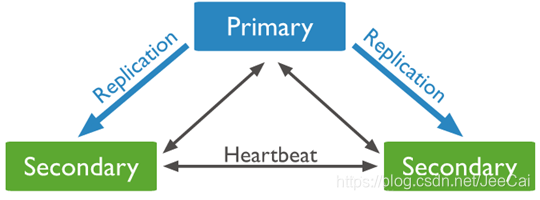
-
主节点记录所有的变更到oplog日志
-
辅助节点(Secondary)复制主节点的oplog****日志并且将这些日志在辅助节点进行重放(做)
-
各个节点之间会定期发送心跳信息,一旦主节点宕机,则触发选举一个新的主节点,剩余的辅助节点指向新的主节点
-
10s内各辅助节点无法感知主节点的存在,则开始触发选举
-
通常1分钟内完成主辅助节点切换,10-30s内感知主节点故障,10-30s内完成选举及切换
-
复制集≠备份 :复制集主要应对的是用户恢复数据,防止数据丢失,实现灾难恢复人为误操作导致数据删除,程序Bug导致数据损坏等行为。
MongoDB复制集集群的搭建
-
节点的类型与职责
- Primary
首要复制节点,由选举产生,提供读写服务的节点,产生oplog日志,一般由性能最好的服务器充当。
- Secondary
备用辅助复制节点,可以提供读服务,增加节点可以提供复制集的读服务能力在故障时,备用节点可以根据设定的优先级别提升为首要节点。提升了复制集的可用性。
- Arbiter
Arbiter节点只参与投票,不能被选为Primary,并且不从Primary同步数据 。Arbiter本身不存储数据,是非常轻量级的服务。当复制集成员为偶数时,最好加入一个Arbiter节点,以提升复制集可用性。
MongoDB复制集灾难转移

mongod实例每隔两秒就向其他成员发送一个心跳包并且通过rs.staus()中返回的成员的”health”值来判断成员的状态。当Primary节点宕机时,那么复制集中所有secondary的节点就会触发一次选举操作,选出一个新的primary节点。
-
选举规则:
如果secondary节点有多个则会选择拥有最新时间截 OPlog记录或较高权限的节点成为primary节点。arbiter节点只是参与选举其他成员成为primary节点,自己永远不会成为primary节点。