什么是宽窄依赖,及特殊join算子,join时何时产生shuffle,何时不产生shuffle
1、 什么是宽窄依赖,
宽依赖: 发生shuffle时,一定会产生宽依赖,宽依赖是一个RDD中的一个Partition被多个子Partition所依赖(一个父亲多有儿子),也就是说每一个父RDD的Partition中的数据,都可能传输一部分到下一个RDD的多个partition中,此时一定会发生shuffle
窄依赖: 一个RDD中的一个 Partition最多 被一个 子 Partition所依赖(一个父亲有一个儿子)
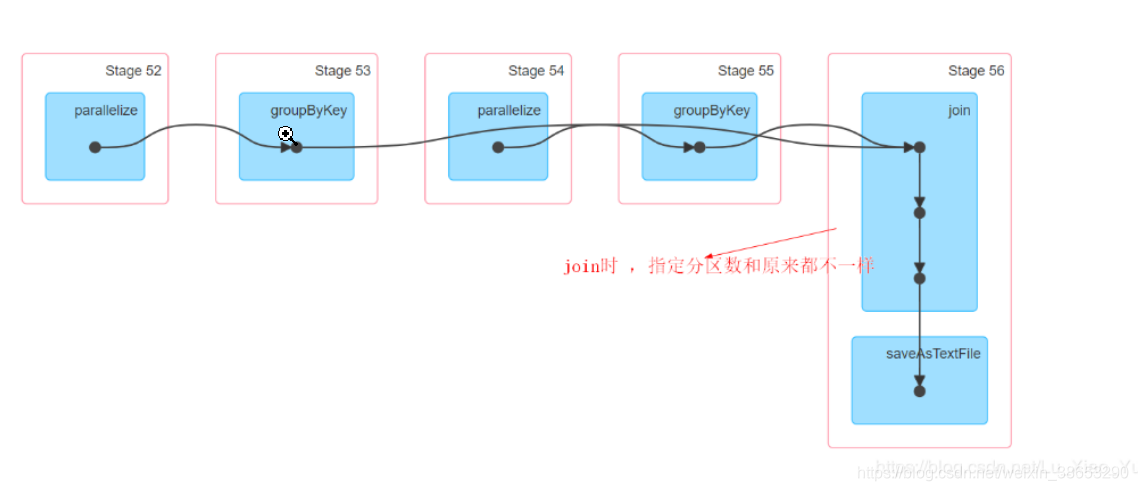
2、 Spark中产生宽窄依赖的依据是shuffle,当发生shuffle时,会产生宽依赖,基本上shuffle算子都会产生宽依赖,但是join除外,在执行join算子之前如果先执行groupByKey,执行groupByKey之后,会把相同的key分到同一个分区,再执行join算子,join算子是把key相同的进行join(只是对于k v形式的数据可以使用),不一定会产生shuffle ,有可能发生shuffle,也有可能不发生
最后返回的结果是(Key,(rdd1的v,rdd2的v)),如下平行化创建,两个RDD,对其进行Join。这中情况下就不一定会产生shuffle,根据具体情况而言
#第一种情况, 不使用groupByKey直接进行join
val rdd1 = sc.parallelize(List("aa"->5,"bb"->5,"dd"->6,"aa"->3,"tt"->2))
val rdd2 = sc.parallelize(List("bb"->1,"aa"->3,"dd"->3,"ss"->6))对于join,第一种情况,在join之前不是groupByKey,发生shuffle
val rdd1 = sc.parallelize(List("aa"->5,"bb"->5,"dd"->6,"aa"->3"tt"->2),1)
val rdd2 = sc.parallelize(List("bb"->1,"aa"->3,"dd"->3,"ss"->6),1)
//设置两个rdd的分区都是1,相同,
val joind: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
通过UI界面可以观察到,一共有三个stage,在join 时进行了shuffle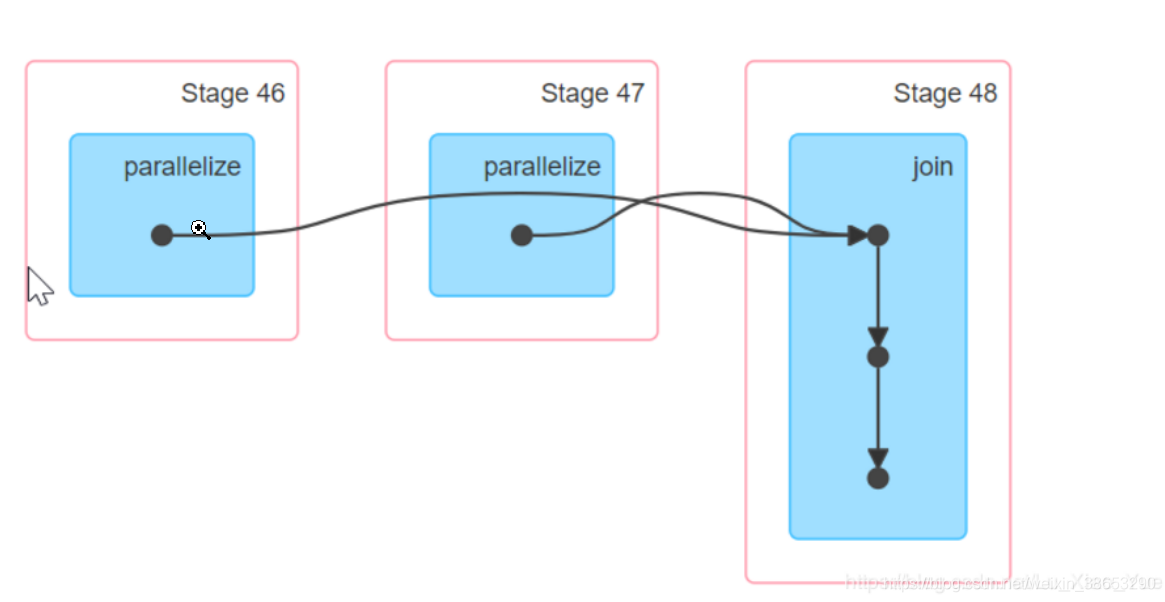
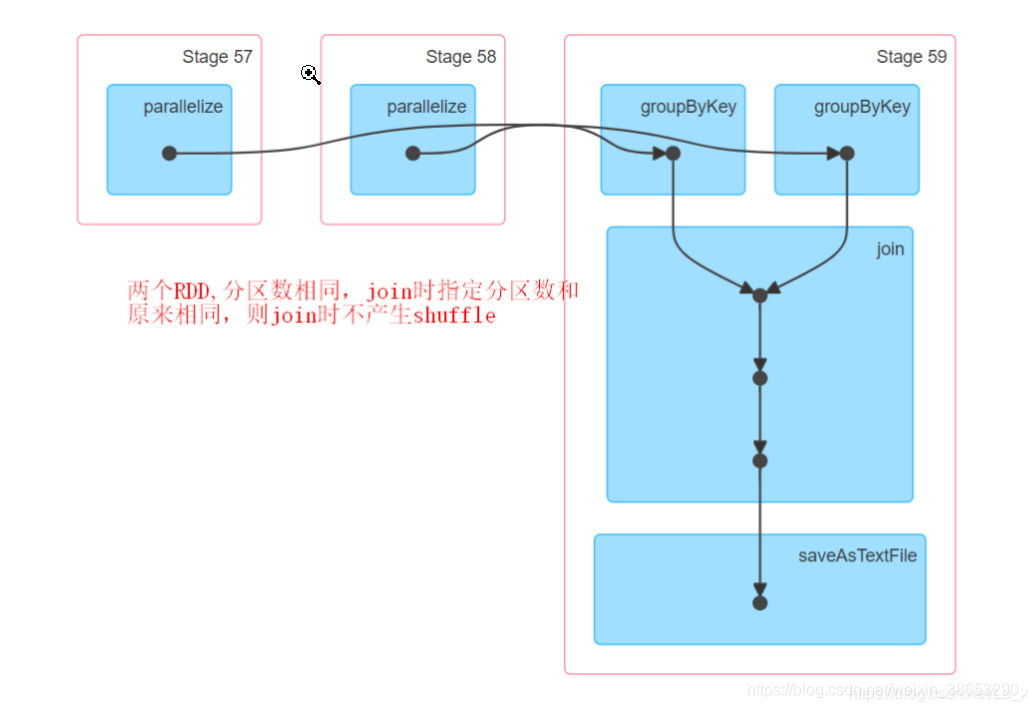
#第二种情况,分区相同,join之前进行groupByKey
val rdd1 = sc.parallelize(List("aa"->5,"bb"->5,"dd"->6,"aa"->3"tt"->2),2)
val rdd2 = sc.parallelize(List("bb"->1,"aa"->3,"dd"->3,"ss"->6),2)
//设置两个rdd的分区相同,在进行join之前使用groupBykey()
val gb1 = rdd1.groupByKey()
val gb2 = rdd2.groupByKey()
val joind: RDD[(String, (Int, Int))] = gb1.join(gb2)通过UI界面观察到,一个共有3个stage,虽然使用了两个shuffle算子,但是和使用一个join的stage相同
从平行化到groupByKey是一个stage,这样就是两个stage,groupByKey到saveAsTextFile是一个stage
rdd1经过groupByKey后,假设两个分区分别是P1:(aa,5)(aa,3) ,P2:(bb,5),(dd,6),(tt,2)
rdd2经过groupByKey后,假设两个分区分别是P1:(aa,3), P2:(bb,1),(dd,3).(ss,6)
在进行join时按key 进行join,不会发生shuffle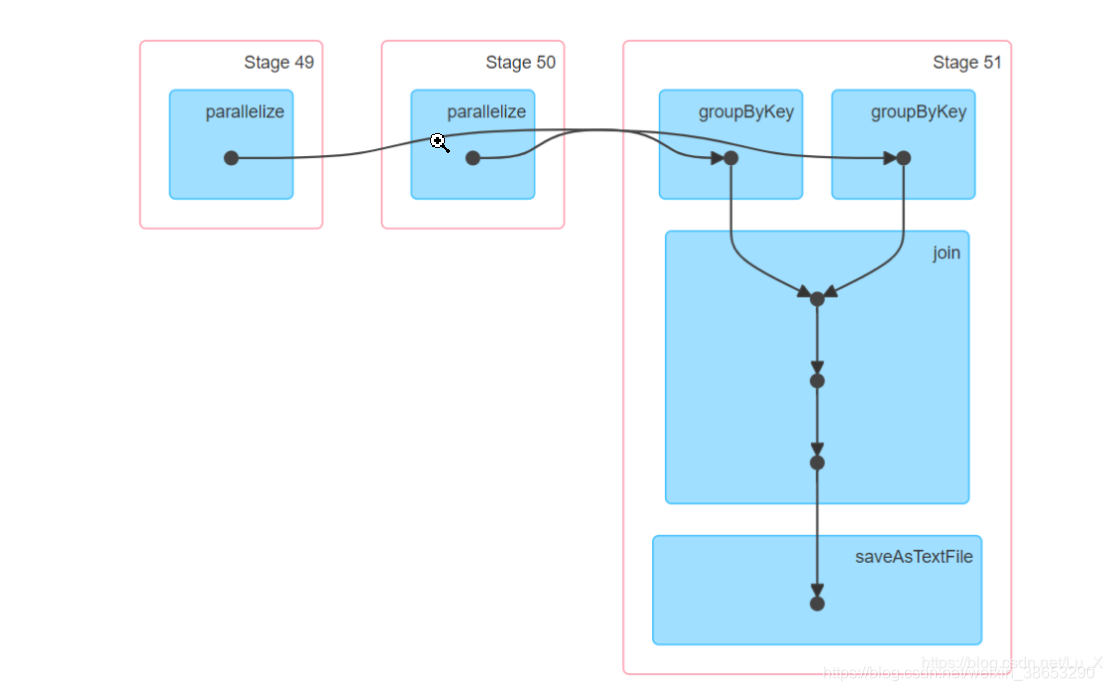
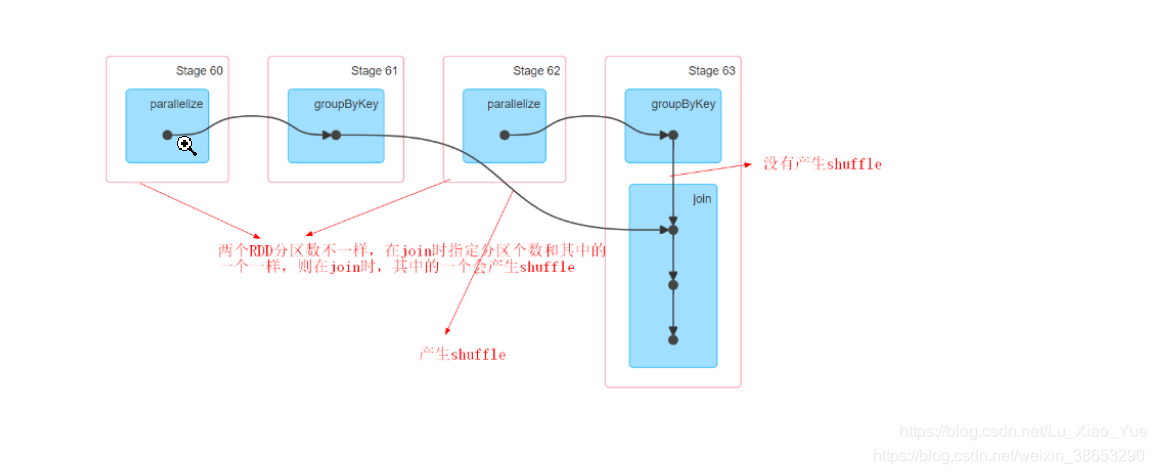
#第三种情况,两个rdd的分区数不同,在join之前进行groupByKey
val rdd1 = sc.parallelize(List("aa"->5,"bb"->5,"dd"->6,"aa"->3"tt"->2),1)
val rdd2 = sc.parallelize(List("bb"->1,"aa"->3,"dd"->3,"ss"->6),5)
//设置两个rdd的分区不同相同,在进行join之前使用groupBykey()
//注:在分区不同时进行join,最后在join时的分区,和rdd分区的数相同
//这种情况下一共 会 产生1+1+5+5个task
val gb1 = rdd1.groupByKey()
val gb2 = rdd2.groupByKey()
val joind: RDD[(String, (Int, Int))] = gb1.join(gb2)有stage的图可以看出来,分区数小的rdd,在join时发生shuffle,
分区数大的rdd,在join时没有发生shuffle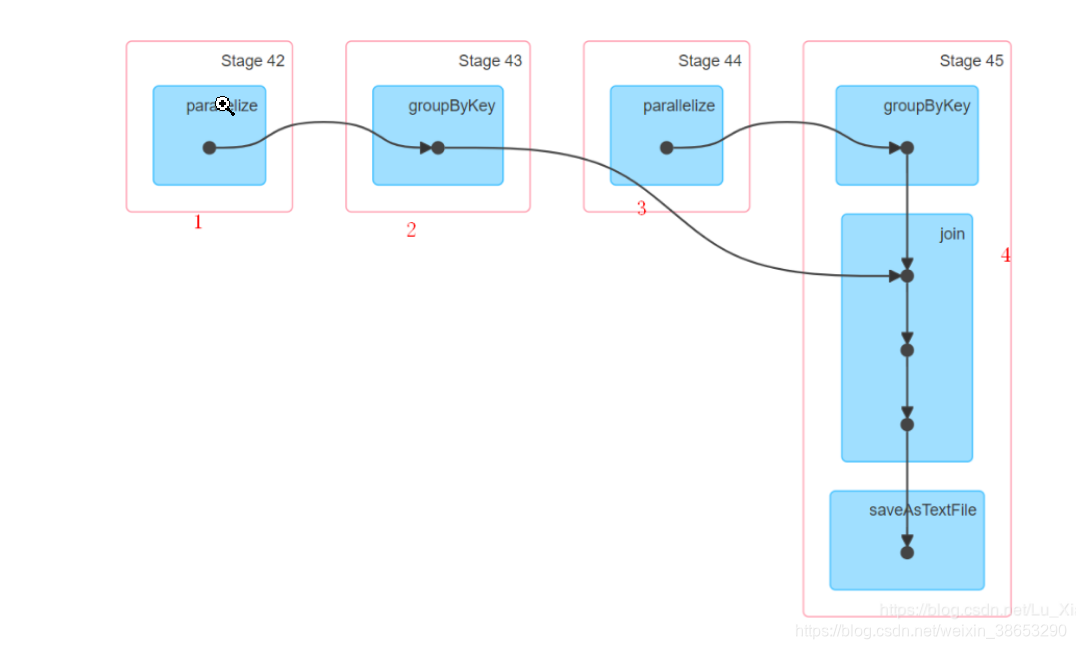
#第四种情况,两个rdd的分区数不同,在join之前进行groupByKey,在join时从新指定分区
val rdd1 = sc.parallelize(List("aa"->5,"bb"->5,"dd"->6,"aa"->3"tt"->2),1)
val rdd2 = sc.parallelize(List("bb"->1,"aa"->3,"dd"->3,"ss"->6),5)
//设置两个rdd的分区不同相同,在进行join之前使用groupBykey()
//注:在分区不同时进行join,最后在join时的分区,和rdd分区的数相同
val gb1 = rdd1.groupByKey()
val gb2 = rdd2.groupByKey()
val joind: RDD[(String, (Int, Int))] = gb1.join(gb2,6)
// val joind: RDD[(String, (Int, Int))] = gb1.join(gb2,5)
//val joind: RDD[(String, (Int, Int))] = gb1.join(gb2,6)