一、同步容器与并发容器
我们知道在java.util包下提供了一些容器类,而Vector和HashTable是线程安全的容器类,但是这些容器实现同步的方式是通过对方法加锁(sychronized)方式实现的,这样读写均需要锁操作,导致性能低下。而即使是Vector这样线程安全的类,在面对多线程下的复合操作的时候也是需要通过客户端加锁的方式保证原子性。如下面例子说明:
public class TestVector { private Vector<String> vector; //方法一 public Object getLast(Vector vector) { int lastIndex = vector.size() - 1; return vector.get(lastIndex); } //方法二 public void deleteLast(Vector vector) { int lastIndex = vector.size() - 1; vector.remove(lastIndex); } //方法三 public Object getLastSysnchronized(Vector vector) { synchronized(vector){ int lastIndex = vector.size() - 1; return vector.get(lastIndex); } } //方法四 public void deleteLastSysnchronized(Vector vector) { synchronized (vector){ int lastIndex = vector.size() - 1; vector.remove(lastIndex); } } }
如果方法一和方法二为一个组合的话。那么当方法一获取到了vector的size之后,方法二已经执行完毕,这样就导致程序的错误。
如果方法三与方法四组合的话。通过锁机制保证了在vector上的操作的原子性。
并发容器是Java 5 提供的在多线程编程下用于代替同步容器,针对不同的应用场景进行设计,提高容器的并发访问性,同时定义了线程安全的复合操作。
二、并发容器类介绍
整体架构(列举常用的容器类)
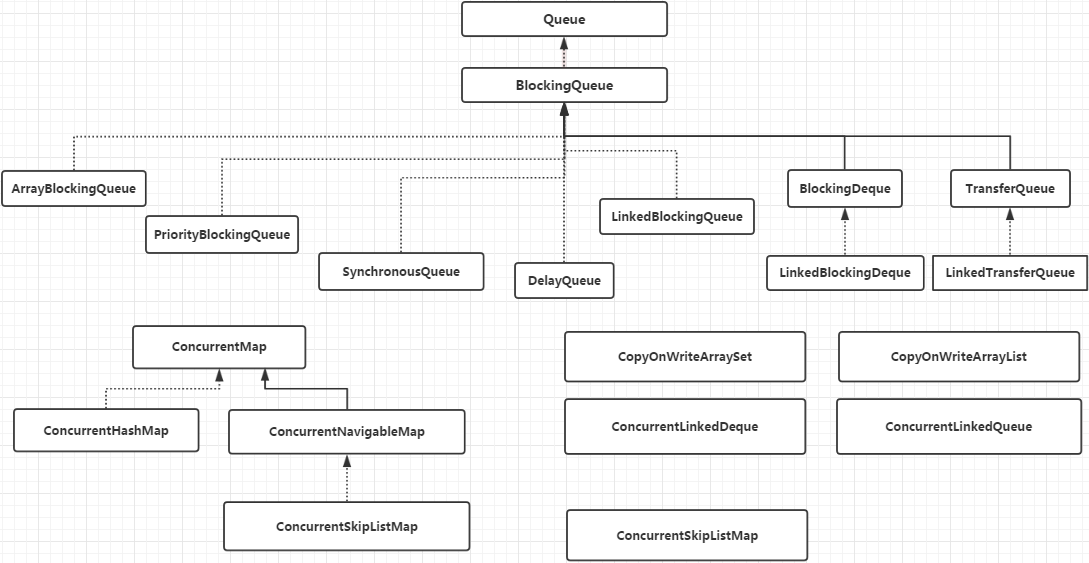
其中,阻塞队列(BlockingQueue)在第十三章有介绍,CopyOnWrite容器(CopyOnWritexxx)在第十六章有介绍,这里不做过多介绍。
下面分别介绍一些常用的并发容器类和接口,因篇幅原因,这里只介绍这些类的用途和基本的原理,不做过多的源码解析。
(1)、ConcurrentMap接口
ConcurrentMap接口继承了Map接口,在Map接口的基础上又定义了四个方法:
public interface ConcurrentMap<K, V> extends Map<K, V> { //插入元素 V putIfAbsent(K key, V value); //移除元素 boolean remove(Object key, Object value); //替换元素 boolean replace(K key, V oldValue, V newValue); //替换元素 V replace(K key, V value); }
- putIfAbsent:与原有put方法不同的是,putIfAbsent方法中如果插入的key相同,则不替换原有的value值;
- remove:与原有remove方法不同的是,新remove方法中增加了对value的判断,如果要删除的key-value不能与Map中原有的key-value对应上,则不会删除该元素;
- replace(K,V,V):增加了对value值的判断,如果key-oldValue能与Map中原有的key-value对应上,才进行替换操作;
- replace(K,V):与上面的replace不同的是,此replace不会对Map中原有的key-value进行比较,如果key存在则直接替换;
(2)、ConcurrentHashMap类
ConcurrentHashMap同HashMap一样也是基于散列表的map,但是它提供了一种与HashTable完全不同的加锁策略提供更高效的并发性和伸缩性。
ConcurrentHashMap在JDK 1.7 和JDK 1.8中有一些区别。这里我们分开介绍一下。
JDK 1.7
ConcurrentHashMap在JDK 1.7中,提供了一种粒度更细的加锁机制来实现在多线程下更高的性能,这种机制叫分段锁(Lock Striping)。
提供的优点是:在并发环境下将实现更高的吞吐量,而在单线程环境下只损失非常小的性能。
可以这样理解分段锁,就是将数据分段,对每一段数据分配一把锁。当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
有些方法需要跨段,比如size()、isEmpty()、containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。如下图:

ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,HashEntry则用于存储键值对数据。
一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
JDK 1.8
而在JDK 1.8中,ConcurrentHashMap主要做了两个优化:
-
-
同HashMap一样,链表也会在长度达到8的时候转化为红黑树,这样可以提升大量冲突时候的查询效率;
-
以某个位置的头结点(链表的头结点或红黑树的root结点)为锁,配合自旋+CAS避免不必要的锁开销,进一步提升并发性能。
-
(3)、ConcurrentNavigableMap接口与ConcurrentSkipListMap类
ConcurrentNavigableMap接口继承了NavigableMap接口,这个接口提供了针对给定搜索目标返回最接近匹配项的导航方法。
ConcurrentNavigableMap接口的主要实现类是ConcurrentSkipListMap类。从名字上来看,它的底层使用的是跳表(SkipList)的数据结构。关于跳表的数据结构这里不做太多介绍,它是一种”空间换时间“的数据结构,可以使用CAS来保证并发安全性。
JDK并没有提供线程安全的List类,因为对List来说,很难去开发一个通用并且没有并发瓶颈的线程安全的List。因为即使简单的读操作,拿contains() 这样一个操作来说,很难想到搜索的时候如何避免锁住整个list。
所以退一步,JDK提供了对队列和双端队列的线程安全的类:ConcurrentLinkedQueue和ConcurrentLinkedDeque。因为队列相对于List来说,有更多的限制。这两个类是使用CAS来实现线程安全的。
2.3、并发Set
JDK提供了ConcurrentSkipListSet,是线程安全的有序的集合。底层是使用ConcurrentSkipListMap实现。
谷歌的guava框架实现了一个线程安全的ConcurrentHashSet:
Set<String> s = Sets.newConcurrentHashSet();
参考资料