想爬一下各大高校的链接,因此就百度找了一下,发现在这里爬是最舒服的,因此就开始了爬虫。
http://daxue.exam8.com/Contact?ProvinceID=0&CityID=0&leixingID=0&xingzhi=&keyword=&page=2
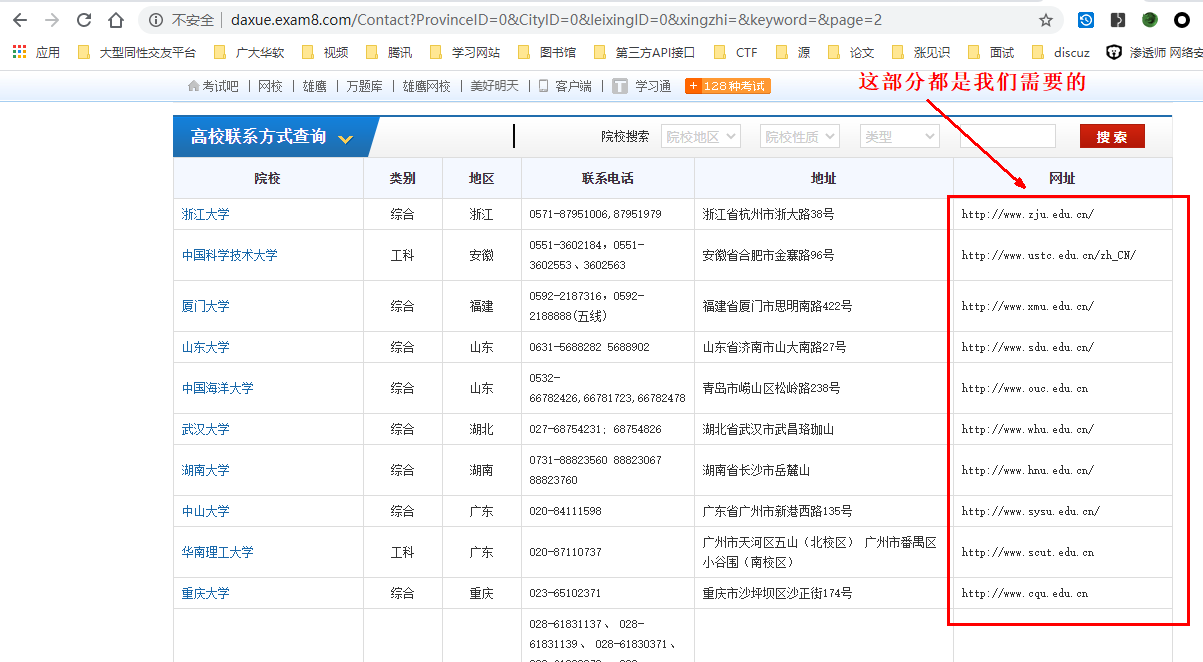
爬虫,肯定得先分析一下页面结构

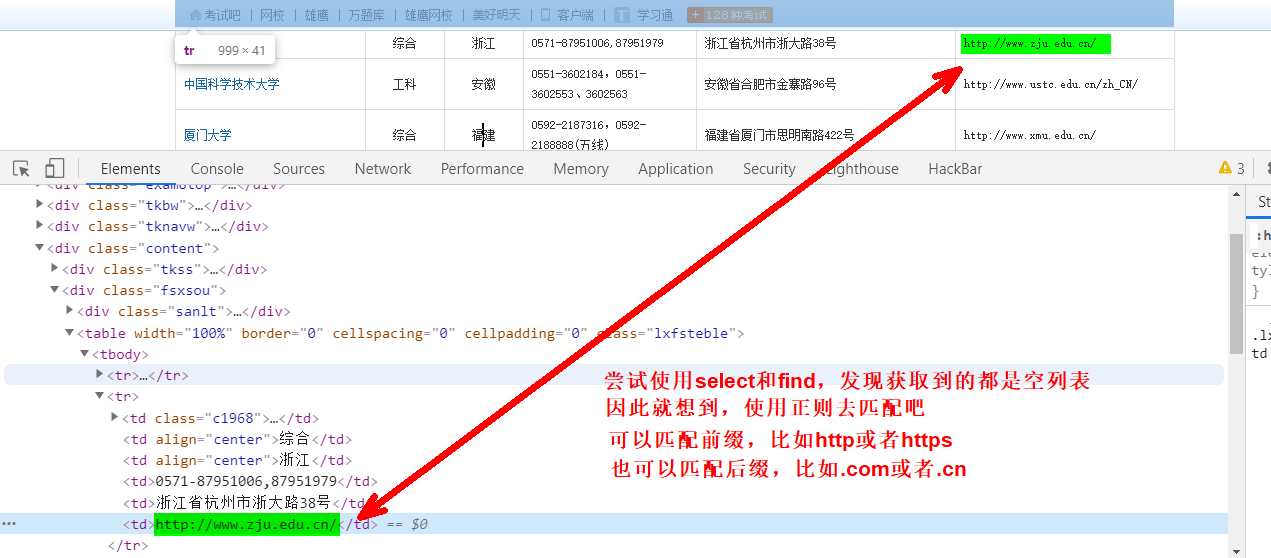
然后直接贴源码吧!
import re import requests from bs4 import BeautifulSoup edu_file = "edu.txt" # 保存链接的文本 headers = { 'user-agent': 'Mozilla/5.0' # 头部 } count = 0 # 统计 link = re.compile(r'[a-zA-Z]+://[^s]*[.com|.cn]') # 正则匹配.com或.cn target = 'http://daxue.exam8.com/' # 目标链接 # 链接后面跟着的参数 parameter = 'Contact?ProvinceID=0&CityID=0&leixingID=0&xingzhi=&keyword=&page=' for page in range(1, 122): # 页数 basic_url = target+parameter+str(page) # 每一页的链接 html = requests.get(basic_url, headers) # 获取每一页的内容 soup = BeautifulSoup(html.text, "html.parser") # 解析每一页的内容 for item in soup.find_all('table', 'lxfsteble'): # 找到所有table类名为lxfsteble for i in re.findall(link, item.text): # 正则匹配含有.com或者.cn的文本,即链接 with open(edu_file, 'a+') as f: # 创建或打开一个txt文档 f.write(i) # 写入数据 f.write(' ') # 换行 print(i) # 输出 count += 1 # 统计链接个数 print('一个爬了'+str(count)+'个链接')
输出如下:
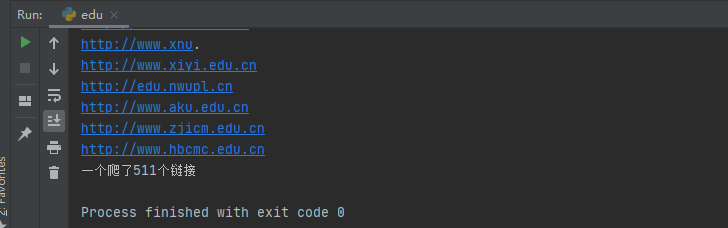
啥???只有511个链接?检查一下页面
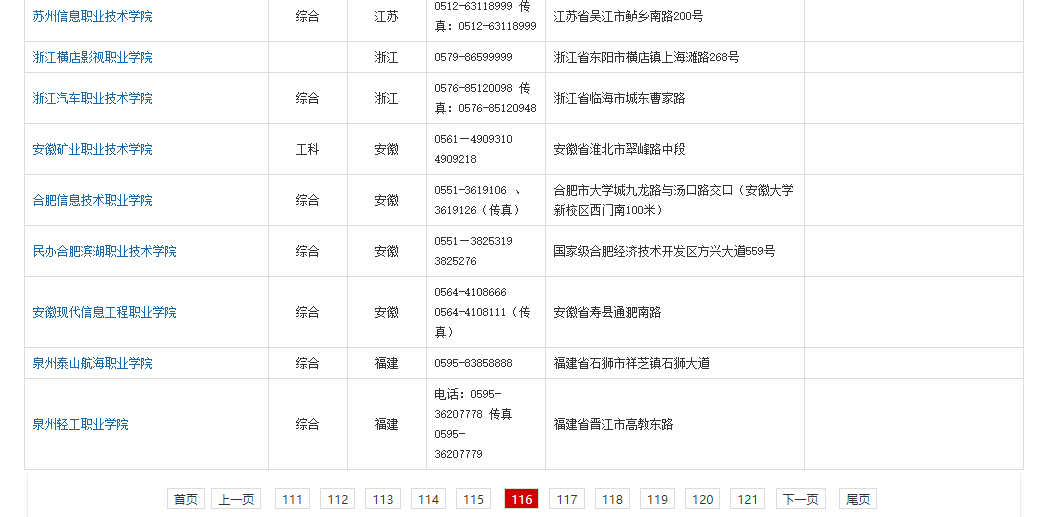
emmm
链接爬取完后,需要过滤一下有效链接,这里我就不写了,方法挺多的。