目前绝大多数的网站的页面都是冬天页面,动态页面中的部分内容是浏览器运行页面中的JavaScript 脚本动态生成的,爬取相对比较困难
先来看一个很简单的动态页面的例子,在浏览器中打开 http://quotes.toscrape.com/js,显示如下:
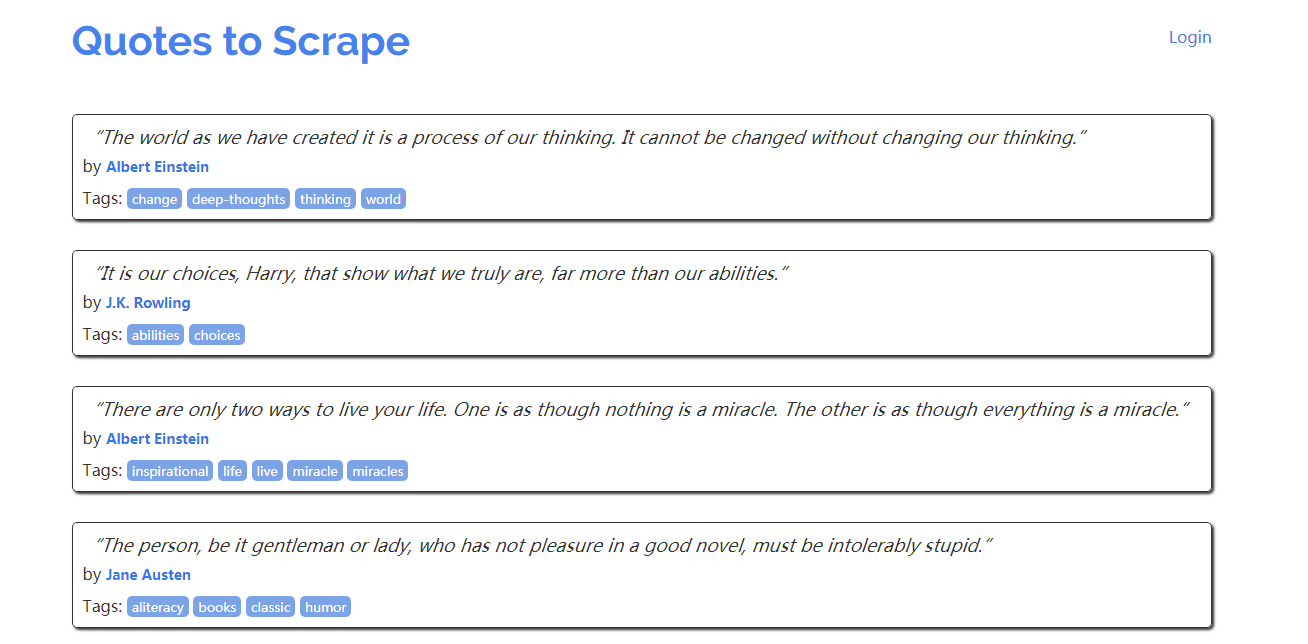
页面总有十条名人名言,每一条都包含在<div class = "quote">元素中,现在我们在 Scrapy shell中尝试爬取页面中的名人名言:
$ scrapy shell http://quotes.toscrape.com/js/ ... >>> response.css(''div.quote) []
从结果可以看出,爬取失败了,在页面中没有找到任何包含名人名言的 <div class = 'quote'>元素。这些 <div class = 'qoute'>就是动态内容,从服务器下载的页面中并不包含他们(多以我们爬去失败),浏览器执行了页面中的一段 JavaScript 代码后,他们才被生成出来。
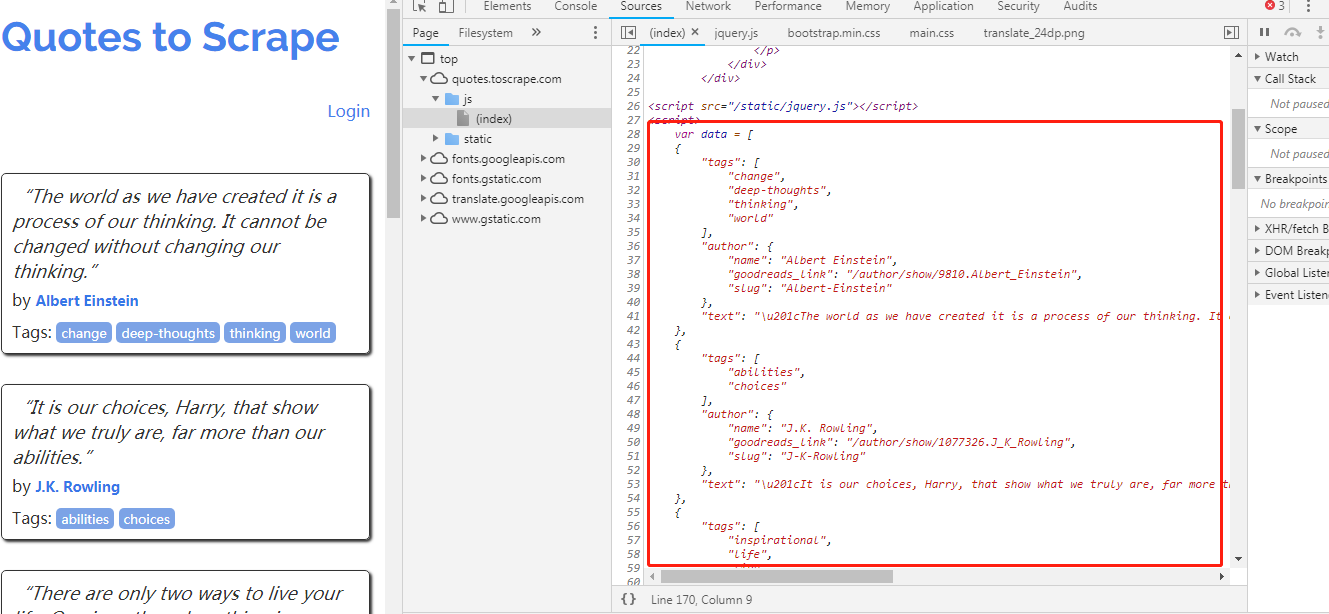
图中的 JavaScript 代码如下:
var data = [ { "tags": [ "change", "deep-thoughts", "thinking", "world" ], "author": { "name": "Albert Einstein", "goodreads_link": "/author/show/9810.Albert_Einstein", "slug": "Albert-Einstein" }, "text": "u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.u201d" }, { "tags": [ "abilities", "choices" ], "author": { "name": "J.K. Rowling", "goodreads_link": "/author/show/1077326.J_K_Rowling", "slug": "J-K-Rowling" }, "text": "u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.u201d" }, { "tags": [ "inspirational", "life", "live", "miracle", "miracles" ], "author": { "name": "Albert Einstein", "goodreads_link": "/author/show/9810.Albert_Einstein", "slug": "Albert-Einstein" }, "text": "u201cThere are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.u201d" }, { "tags": [ "aliteracy", "books", "classic", "humor" ], "author": { "name": "Jane Austen", "goodreads_link": "/author/show/1265.Jane_Austen", "slug": "Jane-Austen" }, "text": "u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.u201d" }, { "tags": [ "be-yourself", "inspirational" ], "author": { "name": "Marilyn Monroe", "goodreads_link": "/author/show/82952.Marilyn_Monroe", "slug": "Marilyn-Monroe" }, "text": "u201cImperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.u201d" }, { "tags": [ "adulthood", "success", "value" ], "author": { "name": "Albert Einstein", "goodreads_link": "/author/show/9810.Albert_Einstein", "slug": "Albert-Einstein" }, "text": "u201cTry not to become a man of success. Rather become a man of value.u201d" }, { "tags": [ "life", "love" ], "author": { "name": "Andru00e9 Gide", "goodreads_link": "/author/show/7617.Andr_Gide", "slug": "Andre-Gide" }, "text": "u201cIt is better to be hated for what you are than to be loved for what you are not.u201d" }, { "tags": [ "edison", "failure", "inspirational", "paraphrased" ], "author": { "name": "Thomas A. Edison", "goodreads_link": "/author/show/3091287.Thomas_A_Edison", "slug": "Thomas-A-Edison" }, "text": "u201cI have not failed. I've just found 10,000 ways that won't work.u201d" }, { "tags": [ "misattributed-eleanor-roosevelt" ], "author": { "name": "Eleanor Roosevelt", "goodreads_link": "/author/show/44566.Eleanor_Roosevelt", "slug": "Eleanor-Roosevelt" }, "text": "u201cA woman is like a tea bag; you never know how strong it is until it's in hot water.u201d" }, { "tags": [ "humor", "obvious", "simile" ], "author": { "name": "Steve Martin", "goodreads_link": "/author/show/7103.Steve_Martin", "slug": "Steve-Martin" }, "text": "u201cA day without sunshine is like, you know, night.u201d" } ]; for (var i in data) { var d = data[i]; var tags = $.map(d['tags'], function(t) { return "<a class='tag'>" + t + "</a>"; }).join(" "); document.write("<div class='quote'><span class='text'>" + d['text'] + "</span><span>by <small class='author'>" + d['author']['name'] + "</small></span><div class='tags'>Tags: " + tags + "</div></div>"); }
阅读代码可以了解页面中动态生成的细节,所有名人名言信息被保存在数组 data 中,最后的 for 循环迭代 data 中的每项信息,使用 document。write 生成每条名人名言对应的 <div class = ‘quote’>元素。
上面是动态页面中最简单的一个例子,数据被应编码到 JavaScript 代码中, 实际中更常见的是JavaScript 通过 HTTP 请求跟网站动态交互获取数据(AJAX),然后使用数据更新 HTMML 页面。爬取此类动态网页需要先执行页面使用 JavaScript 渲染引擎页面,咋进行爬取。