林子雨实验六
(1)解压安装包
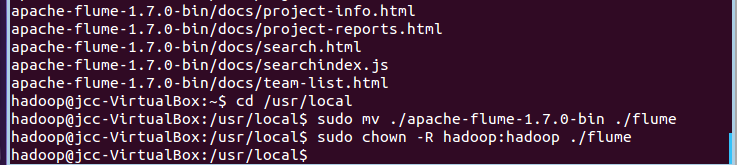
sudo tar -zxvf /home/hadoop/下载/apache-flume-1.7.0-bin.tar.gz -C /usr/local cd /usr/local sudo mv ./apache-flume-1.7.0-bin ./flume sudo chown -R hadoop:hadoop ./flume
(2)配置环境变量
sudo vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64; export FLUME_HOME=/usr/local/flume export FLUME_CONF_DIR=$FLUME_HOME/conf export PATH=$PATH:$FLUME_HOME/bin
注意, 上面的JAVA_HOME,如果以前已经在.bashrc文件中设置过,就不要重复添加了,使用以前的设置即可。

接下来使环境变量生效:
source ~/.bashrc
修改 flume-env.sh 配置文件:
cd /usr/local/flume/conf sudo cp ./flume-env.sh.template ./flume-env.sh sudo vim ./flume-env.sh

3.查看flume版本信息
cd /usr/local/flume
./bin/flume-ng version
注意:如果系统里安装了hbase,会出现错误: 找不到或无法加载主类 org.apache.flume.tools.GetJavaProperty。如果没有安装hbase,这一步可以略过。
cd /usr/local/hbase/conf sudo vim hbase-env.sh
#1、将hbase的hbase.env.sh的这一行配置注释掉,即在export前加一个# #export HBASE_CLASSPATH=/home/hadoop/hbase/conf #2、或者将HBASE_CLASSPATH改为JAVA_CLASSPATH,配置如下 export JAVA_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar #笔者用的是第一种方法

安装成功:

使用Avro数据源测试Flume
Avro 可以发送一个给定的文件给 Flume,Avro 源使用 AVRO RPC 机制。请对 Flume 的的相关配置文件进行设置,从而可以实现如下功能:在一个终端中新建一个文件helloworld.txt(里面包含一行文本“Hello World”),在另外一个终端中启动 Flume 以后,可以把 helloworld.txt 中的文本内容显示出来。
创建agent配置文件
cd /usr/local/flume sudo vim ./conf/avro.conf
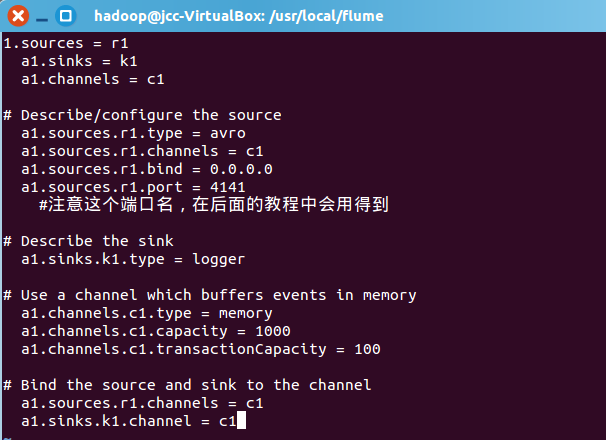
然后,我们在avro.conf写入以下内容
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
#注意这个端口名,在后面的教程中会用得到
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume agent a1
/usr/local/flume/bin/flume-ng agent -c . -f /usr/local/flume/conf/avro.conf -n a1 -Dflume.root.logger=INFO,console
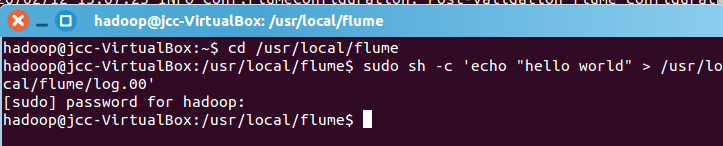
创建指定文件
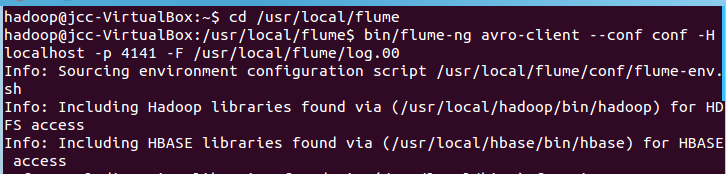
先打开另外一个终端,在/usr/local/flume下写入一个文件log.00,内容为hello,world:
我们再打开另外一个终端,执行:
cd /usr/local/flume bin/flume-ng avro-client --conf conf -H localhost -p 4141 -F /usr/local/flume/log.00 #4141是avro.conf文件里的端口名

创建agent配置文件
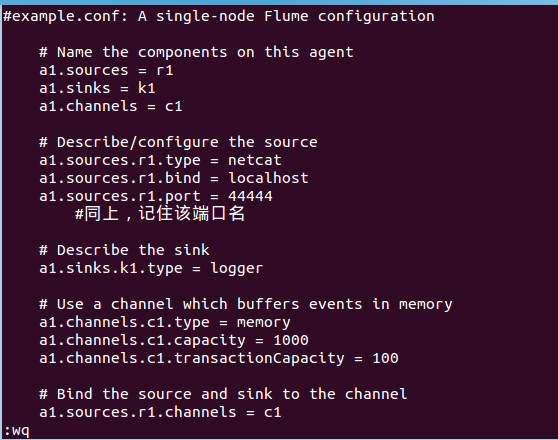
cd /usr/local/flume sudo vim ./conf/example.conf

在example.conf里写入以下内容:
#example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#同上,记住该端口名
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
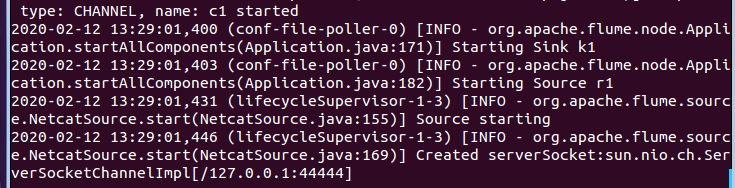
启动flume agent (即打开日志控制台):
/usr/local/flume/bin/flume-ng agent --conf ./conf --conf-file ./conf/example.conf --name a1 -Dflume.root.logger=INFO,console
再打开一个终端,输入命令:telnet localhost 44444
telnet localhost 44444
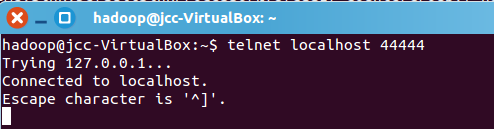
然后我们可以在终端下输入任何字符,第一个终端的日志控制台也会有相应的显示,如我们输入”hello,world”,得出
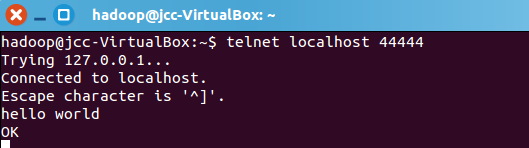
第一个终端的日志控制台显示:

netcatsource运行成功!
这里补充一点,flume只能传递英文和字符,不能用中文。