回归问题提出
首先需要明确回归问题的根本目的在于预测。对于某个问题,一般我们不可能测量出每一种情况(工作量太大),故多是测量一组数据,基于此数据去预测其他未测量数据。
比如课程给出的房屋面积、房间数与价格的对应关系,如下表:
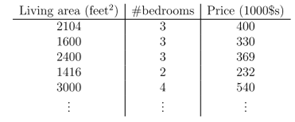
若要测量出所有情况,不知得测到猴年马月了。有了上面这一组测量数据,我们要估计出一套房子(如2800平方英尺5个房间)的价格,此时回归算法就可以荣耀登场了。
回归算法推导
有了上面这个问题,如何来估计房子的价格呢?首先需要建立模型,一种最简单的模型就是线性模型了,写成函数就是:
( h_ heta(x_1,x_2)={ heta_0}+{ heta_1}{x_1}+{ heta_2}{x_2} )
其中(x_1)是房子面积,(x_2)是房间数,(h)是对应的房子面积,( heta_j)就是我们需要求的系数。
对于每个具体问题,需要根据测量数据的情况来确定是否为线性。这里假设为线性模型会限制适用范围,如果房屋面积与价格不是线性关系,则此模型估计的房子价格可能会偏差很大。因此实际上这里也可以假设为其他关系(如指数、对数等),那么估计结果可能就极度不准确了,当然那也就不是线性回归,这里就不必讨论。具体为什么选择线性模型,将在后面广义回归模型中来解答。
上面公式写成向量形式,则为
( h_ heta(x)=sum_{i=0}^n{ heta_i{x_i}}= heta^T{x} )
其中
( heta=( heta_0, heta_1,..., heta_n)^T)
( x=(1,x_1, ... ,x_n)^T )
那么上面的测量数据可以表示为( (x^{(1)},y^{(1)}), (x^{(2)},y^{(2)}),..., (x^{(m)},y^{(m)}) ),其中的y为测量的房屋面积。这样如何根据这m个测量数据来求解参数( heta )就是我们需要解决的问题了。
我们可以通过保证此组测量的预测误差最小来约束求解。代价函数为
(J( heta)={frac{1}{2}}sum_{i=1}^m{(h_ heta(x^{(i)})-y^{(i)})^2})
该代价函数表达的是测量数据的均方误差和。通过最小化该代价函数,即可估计出参数( heta )。前面那个1/2并没有实质意义,主要为了后面求导方便加的;实际上为1/m更具有绝对意义。
回归算法求解
如何求解上述问题?主要有梯度下降法,牛顿迭代法,最小二乘法。这里主要讲梯度下降法,因为该方法在后面使用较多,如神经网络、增强学习等求解都是使用梯度下降。
函数在沿着其梯度方向增加最快的,那么要找到该函数的最小值,可以沿着梯度的反方向来迭代寻找。也就是说,给定一个初始位置后,寻找当前位置函数减小最快的方向,加上一定步长即可到达下一位置,然后再寻找下一位置最快的方向来到达再下一个位置……,直至其收敛。上述过程用公式表达出来即如下所示:
( heta_j = heta_j - alpha{frac{partial}{partial{ heta_j}}}{J( heta)})
根据上述表达式,可以求得代价函数的偏导数为:
( {frac{partial}{partial{ heta_j}}}{J( heta)} = sum_{i=1}^m{(h_ heta(x^{(i)})-y^{(i)}) {frac{partial}{partial{ heta_j}}}{h_ heta(x^{(i)})}} = sum_{i=1}^m{(h_ heta(x^{(i)})-y^{(i)})x_j^{(i)}} )
这样,迭代规则为
( heta_j = heta_j - alphasum_{i=1}^m{(h_ heta(x^{(i)})-y^{(i)})x_j^{(i)}}quad (j=1,2,...,n))
这个公式即是所谓的批量梯度下降。仔细观察该公式,每次迭代都需要把m个样本全部计算一遍,如果m很大时,其迭代将非常慢,因此一种每次迭代只计算1个样本的随机梯度下降(或增量梯度下降)可以极大减少运算量,其迭代如下:
( heta_j = heta_j - alpha {(h_ heta(x^{(i)})-y^{(i)})x_j^{(i)}}quad (i=1,2,...,n quad j=1,2,...,n))
若所有样本迭代完成后还未收敛,则继续从第1个样本开始迭代。
算法实现与结果
首先使用下面代码生成一组数据,为了后续显示方便,数据为一条直线上叠加一定噪声:


1 N = 100; 2 x = rand(N, 1) * 10; 3 y = 5 * x + 10 + 5 * randn(N, 1); 4 Sample = [x y]; 5 save('data.mat', 'Sample') 6 figure,plot(x, y, 'o');
数据显示出来如下图: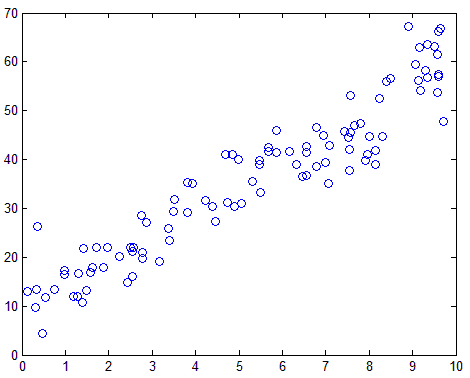
线性回归函数使用梯度下降求解:
1 %返回值Theta为回归结果 2 %IterInfo为迭代的中间过程信息,用于调试,查看 3 %Sample为训练样本,每一行为一个样本,每个样本最后一个为Label值 4 %BatchSize为每次批量迭代的样本数 5 function [Theta, IterInfo]=LinearRegression(Sample, BatchSize) 6 [m, n] = size(Sample); %m个样本,每个n维 7 Y = Sample(:, end); %label 8 X = [Sample(:,1:end-1), ones(m,1)]';%x加入常数项1,并转换为每列表示1个样本 9 10 BatchSize = min(m, BatchSize); 11 Theta = zeros(n, 1); 12 Theta0= Theta; 13 Alpha = 1e-2 * ones(n, 1); 14 StartID = 1; 15 16 IterInfo.Grad = []; 17 IterInfo.Theta = [Theta]; 18 19 %梯度下降,迭代求解 20 MaxIterTime = 5000; 21 for i = 1:MaxIterTime 22 EndID = StartID + BatchSize; 23 if(EndID > m) 24 TX = [X(:, StartID:m) X(:, 1:EndID-m)]; 25 TY = [Y(StartID:m); Y(1:EndID-m)]; 26 else 27 TX = X(:, StartID:EndID); 28 TY = Y(StartID:EndID); 29 end 30 31 Grad = CalcGrad(TX, TY, Theta); 32 Theta = Theta + Alpha .* Grad; 33 34 %记录中间结果 35 IterInfo.Grad = [IterInfo.Grad Grad]; 36 IterInfo.Theta = [IterInfo.Theta Theta]; 37 38 %迭代收敛检验 39 Delta = Theta - Theta0; 40 if(Delta' * Delta < 1e-10) 41 break; 42 end 43 44 Theta0 = Theta; 45 StartID = EndID + 1; 46 StartID = mod(StartID, m) + 1; 47 end 48 49 IterInfo.Time = i; 50 end 51 52 %梯度计算 53 function Grad = CalcGrad(X, Y, Theta) 54 D = 0; 55 for i = 1:size(X,2) 56 G = (Y(i) - Theta' * X(:,i)) * X(:,i); 57 D = D + G; 58 end 59 Grad = D / size(X,2); 60 end
测试函数:
1 %回归 2 load('data.mat'); 3 4 BatchSize = 100; 5 [Theta, IterInfo] = LinearRegression(Sample, BatchSize) 6 7 %显示结果,以下代码不通用,样本维数增加时显示不可用 8 figure,plot(Sample(:,1), Sample(:,2), 'o'); 9 t = 0:0.1:10; 10 z = Theta(1) * t + Theta(2); 11 hold on, plot(t, z, 'r') 12 13 for i = 1:size(IterInfo.Theta,2) 14 err(i) = Error(Sample, IterInfo.Theta(:,i)); 15 end 16 figure,plot(log(err),'b');pause(.1) 17 18 [t1,t2]=meshgrid(0:0.1:20); 19 for i = 1:size(t1,1) 20 for j = 1:size(t1,2) 21 E(i,j) = Error(Sample, [t1(i,j); t2(i,j)]); 22 end 23 end 24 figure,mesh(t1, t2, E);hold on 25 [R,C]=find(E==min(min(E))); 26 plot3(t1(R,C), t2(R,C), min(min(E)), 'rs','MarkerEdgeColor','b',... 27 'MarkerFaceColor','r',... 28 'MarkerSize',15);hold on 29 30 t1 = IterInfo.Theta(1,:); 31 t2 = IterInfo.Theta(2,:); 32 for i = 1:size(IterInfo.Theta,2) 33 ItErr(i)=Error(Sample, IterInfo.Theta(:,i)); 34 end 35 plot3(t1,t2,ItErr,'--rs','LineWidth',1,... 36 'MarkerEdgeColor','k',... 37 'MarkerFaceColor','g',... 38 'MarkerSize',10);hold on
实际上上述代码中真正涉及算法求解的不多,其他都是保存中间结果和绘图等用于调试分析的。回归结果如图,蓝色点为上面保存的数据,红色直线是回归拟合的直线:

其中每次迭代后,代价函数J的变化则如下图(考虑其范围过大,绘制的是其对数图):
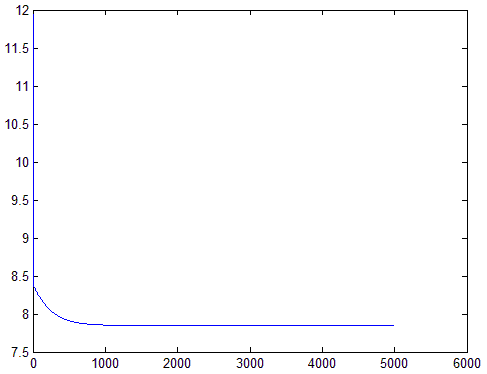
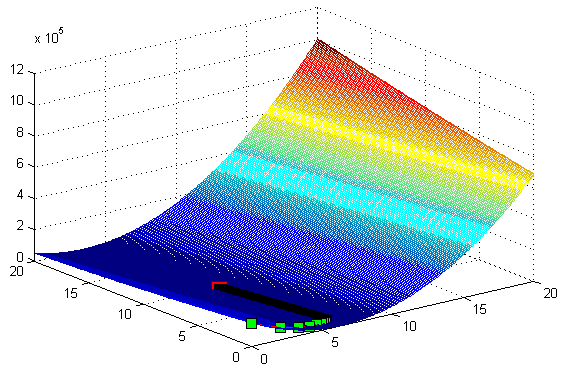
可以看出,当迭代超过1000次时,代价函数已经基本不变了。梯度下降迭代过程如下左图,xy坐标分别为( heta_0和 heta_1),z轴为对应( heta)的代价函数值,图中心的红色小块是真实的最优值,绿色方块是每次迭代的位置,可以看到迭代过程是不断靠近最优解。由于图中绿色方块重叠过多导致绘图出来中间部分显示为黑色了,右图为局部放大的结果。
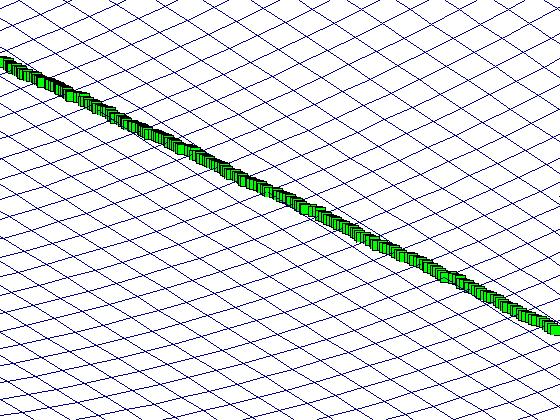
算法分析
1. 梯度下降法中,BatchSize为一次迭代使用的样本数量,当其为m时,即为批量梯度下降,为1时即是随机梯度下降。实验效果显示,BatchSize越大,迭代越耗时,但其收敛越稳定;反之,则迭代越快,而易产生振荡现象;具体可修改测试代码中的BatchSize来看实验结果。
2. 关于步长的选择。在梯度下降法中,步长的影响是非常大的,步长过小会导致收敛非常慢,过大则容易导致不收敛。上述程序中的步长是经过若干次运行修改的,换一组其他数据可能不收敛,这是该程序存在的问题,待回归算法完结后将专门来一篇分析该问题,并给出解决方法。