1、首先安装Scala插件,File->Settings->Plugins,搜索出Scla插件,点击Install安装;
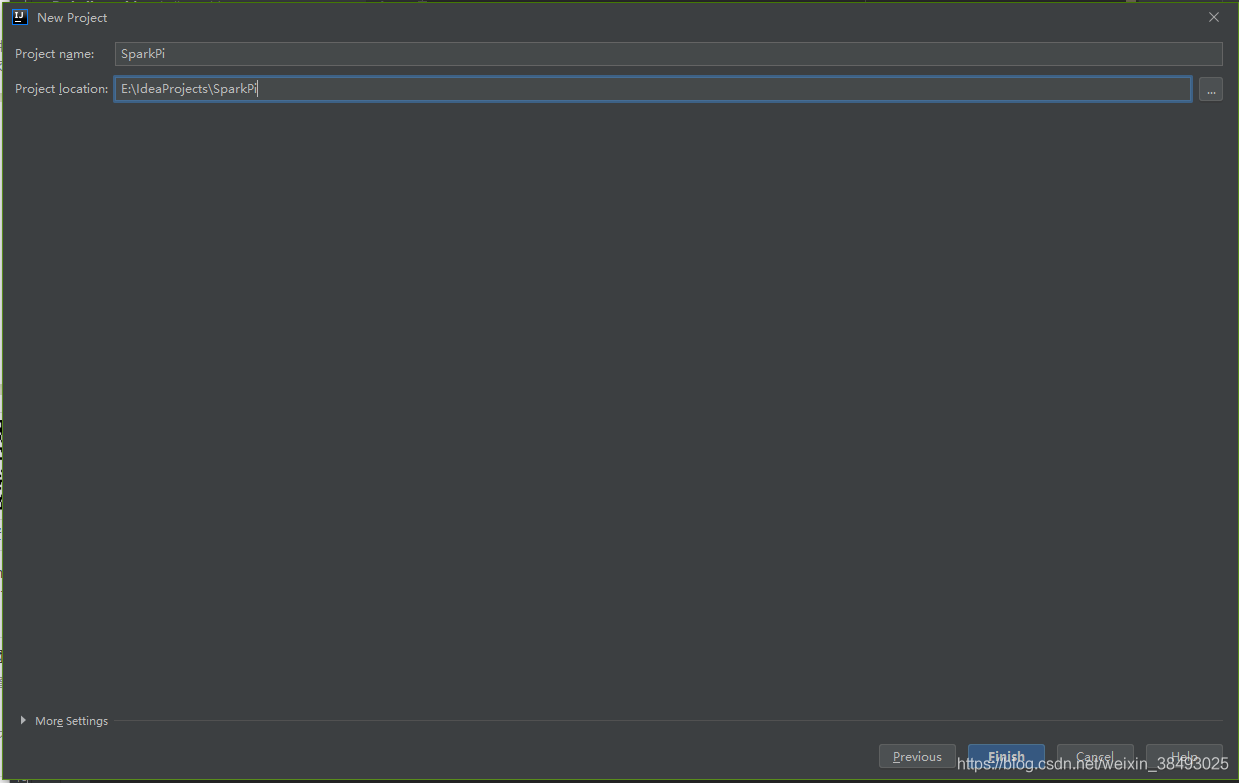
2、File->New Project->maven,新建一个Maven项目,填写GroupId和ArtifactId;


3、编辑pom.xml文件
添加项目所需要的依赖:前面几行是系统自动生成的,我们只需要从
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>test</groupId>
<artifactId>SparkPi</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.4.4</spark.version>
<scala.version>2.11</scala.version>
</properties>
<repositories>
<repository>
<id>nexus-aliyun</id>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>
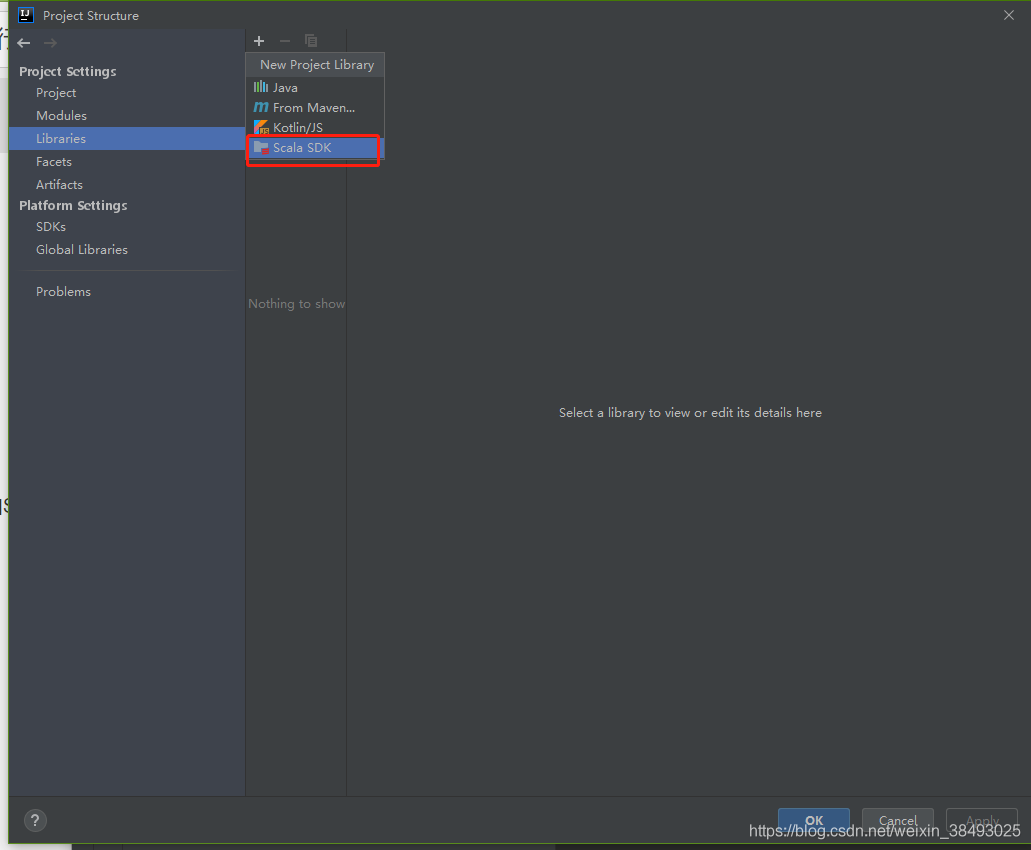
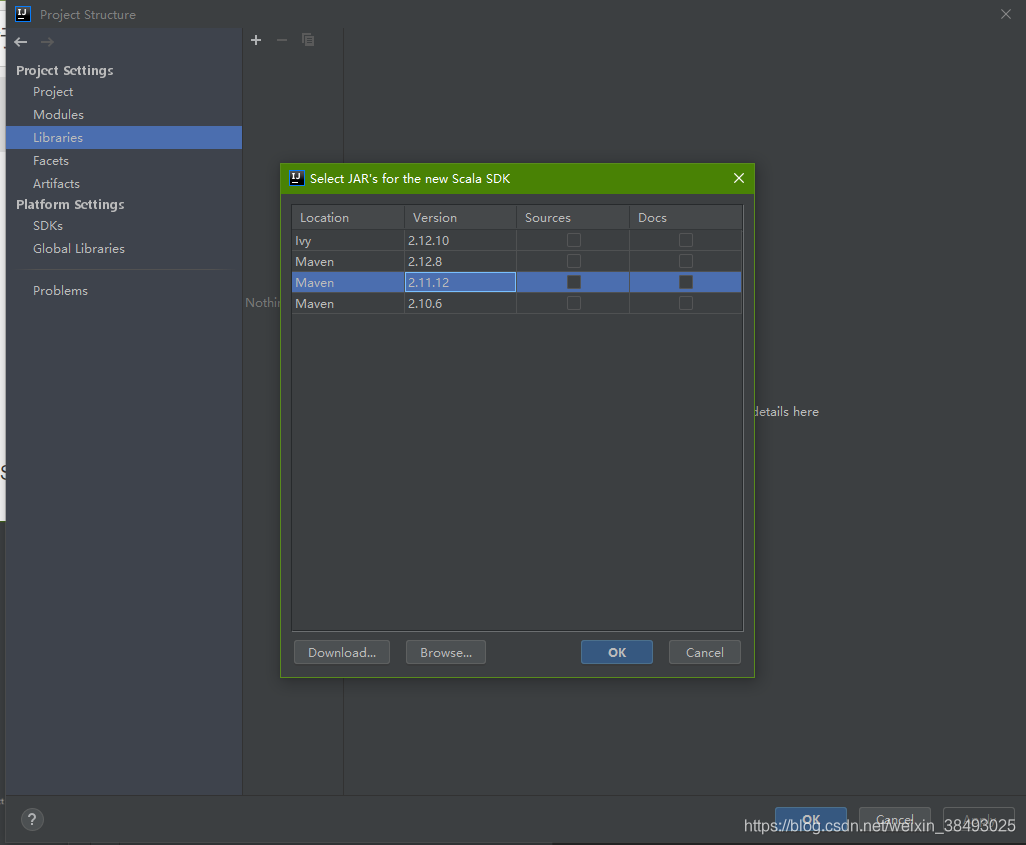
4、File->Project Structure->Libraries,选择和Spark运行环境一致的Scala版本
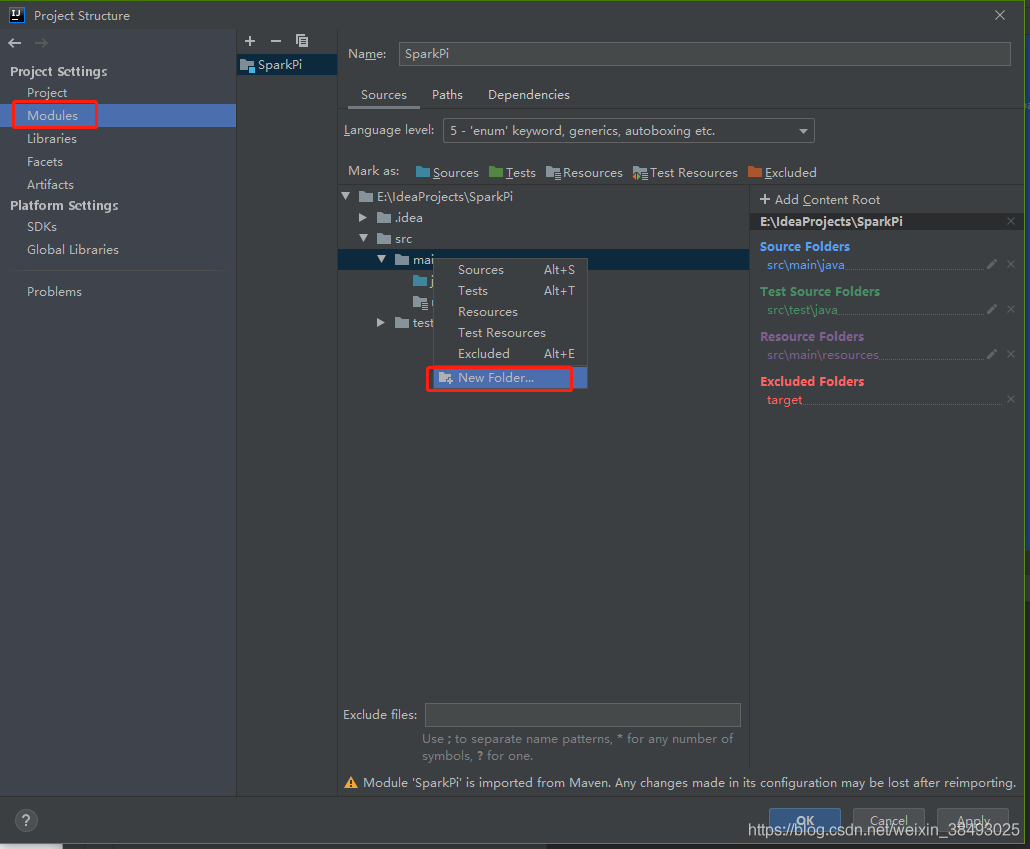
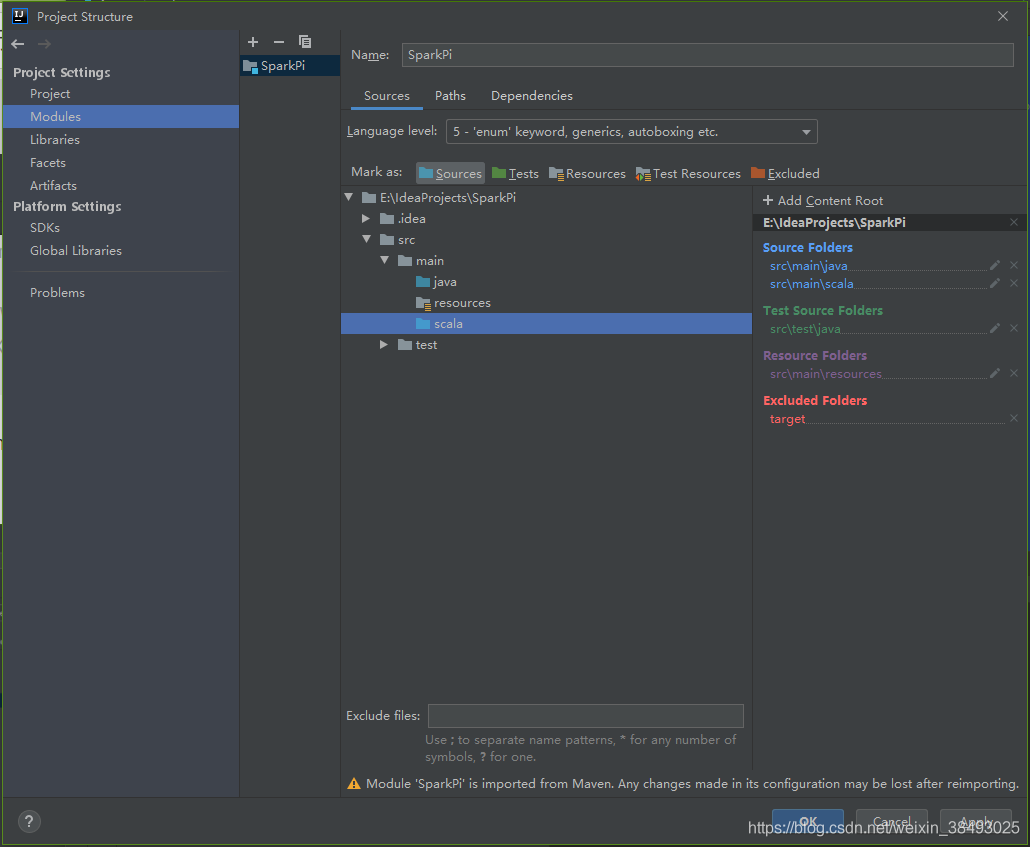
5、File->Project Structure->Modules,在src/main/下面增加一个scala文件夹,并且设置成source文件夹
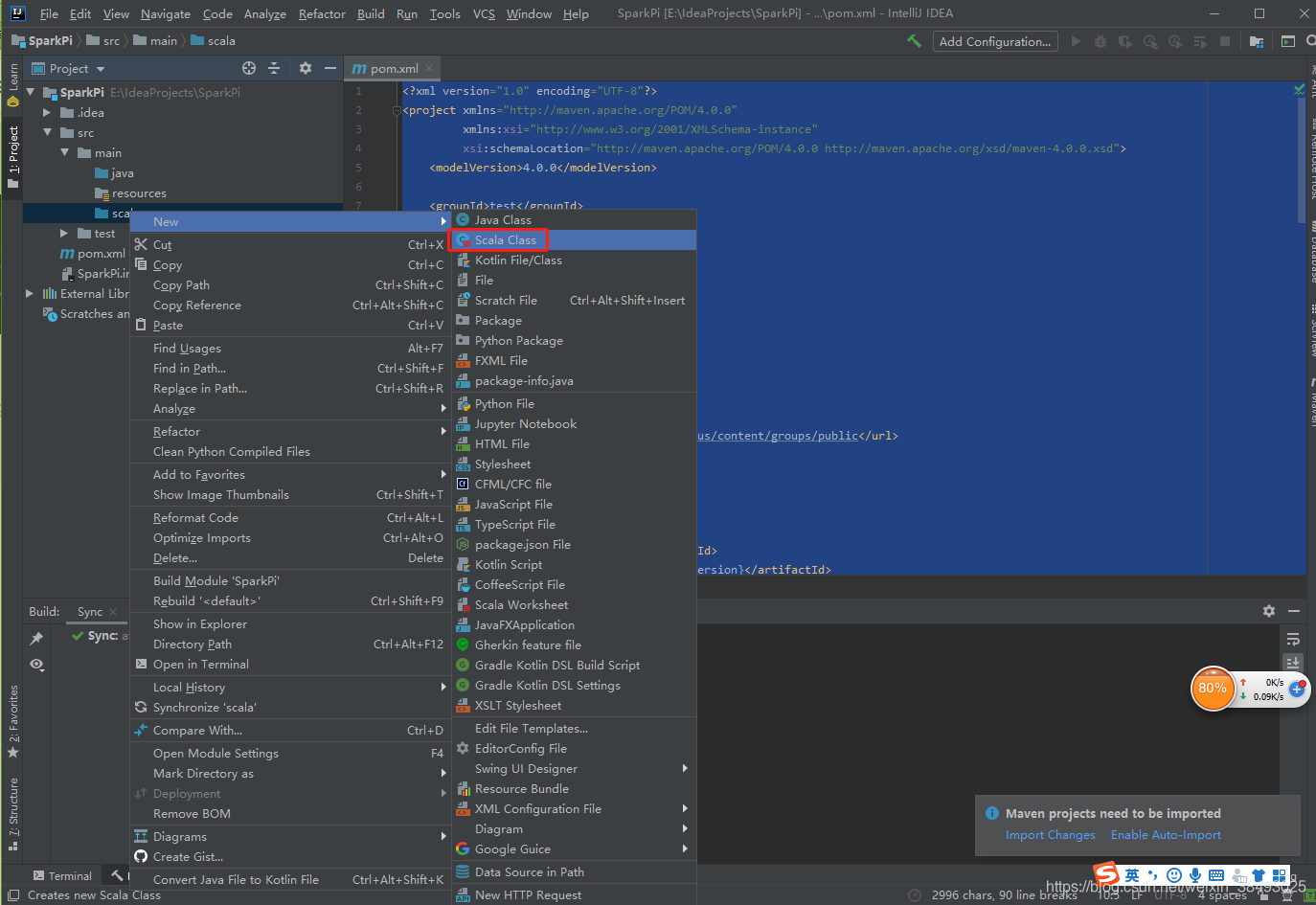
6、在scala文件夹下面新建一个scala文件SparkPi

SparkPi文件的代码如下:其中,setMaster用来指定spark集群master的位置;setJars用来指定程序jar包的位置,此位置在下面1步中添加程序jar包的output directory可以看到。
import scala.math.random
import org.apache.spark._
object SparkPi {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi").setMaster("spark://222.201.187.178:7077").setJars(Seq("E:\IdeaProjects\SparkPi\out\artifacts\SparkPi_jar\SparkPi.jar"))
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
println("Time:" + spark.startTime)
val n = math.min(1000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y < 1) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}
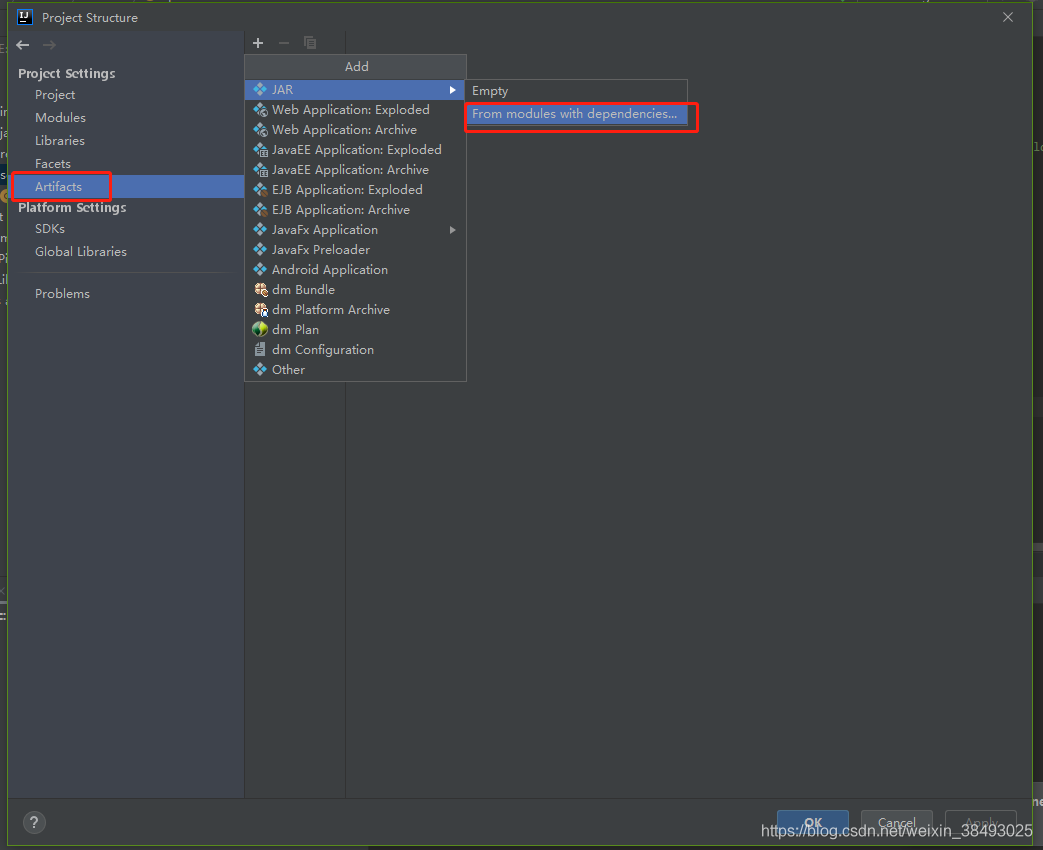
7、File->Project Structure->Artifacts,新建一个Jar->From modules with dependencies…,选择Main Class,之后在Output Layput中删掉不必要的jar
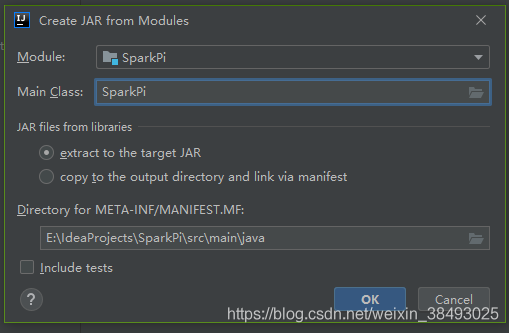
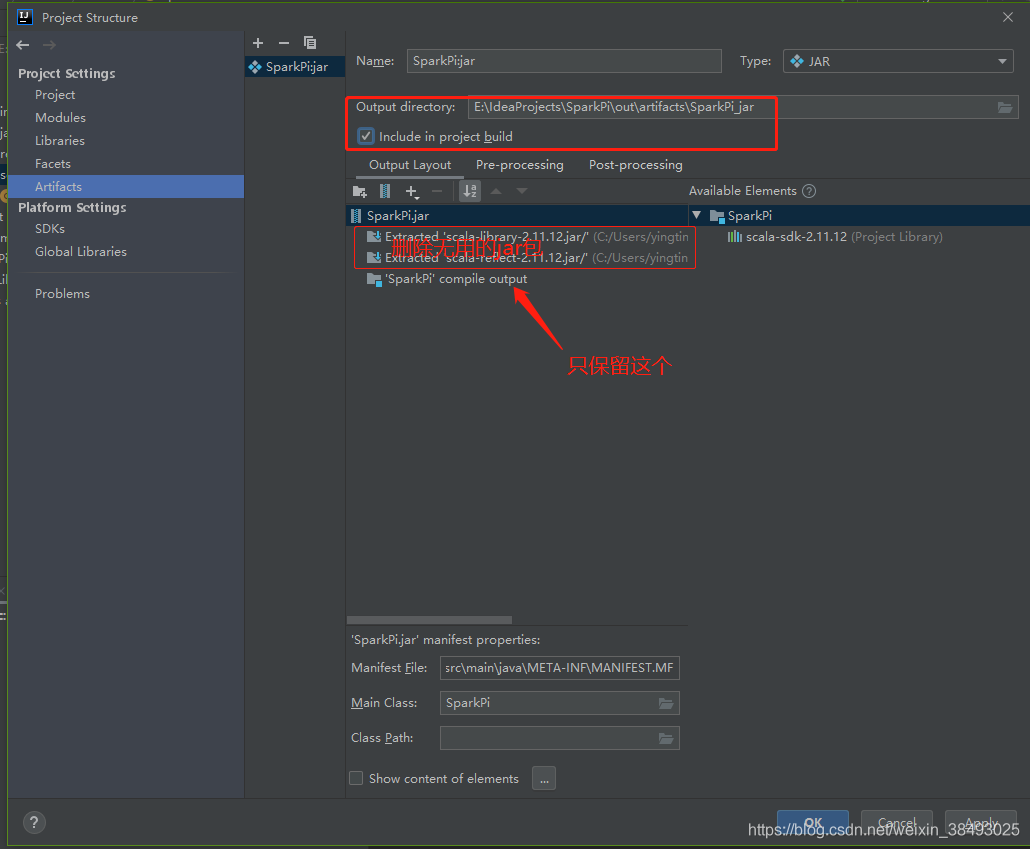
注意这里如果没有删除没用的jar包,后面执行会报错java.lang.ClassNotFoundException: SparkPi$$anonfun$1
8、在服务器集群配置文件/usr/local/spark/conf/spark-env.sh中加入以下代码:
export SPARK_SUBMIT_OPTS="-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005"
# address:JVM在5005端口上监听请求,这个设定为一个不冲突的端口即可。
# server:y表示启动的JVM是被调试者,n表示启动的JVM是调试器。
# suspend:y表示启动的JVM会暂停等待,直到调试器连接上才继续执行,n则JVM不会暂停等待。
9、在服务器Master节点主机上启动hadoop集群,然后再启动spark集群,最后运行jps命令检查进程。
cd /usr/local/hadoop/
sbin/start-all.sh # 启动hadoop集群
cd /usr/local/spark/
sbin/start-master.sh # 启动Master节点
sbin/start-slaves.sh # 启动所有Slave节点
jps
10、在IDEA上添加远程配置,根据spark集群中spark-env.sh的SPARK_SUBMIT_OPTS的变量,对远程执行进行配置,保持端口号一致
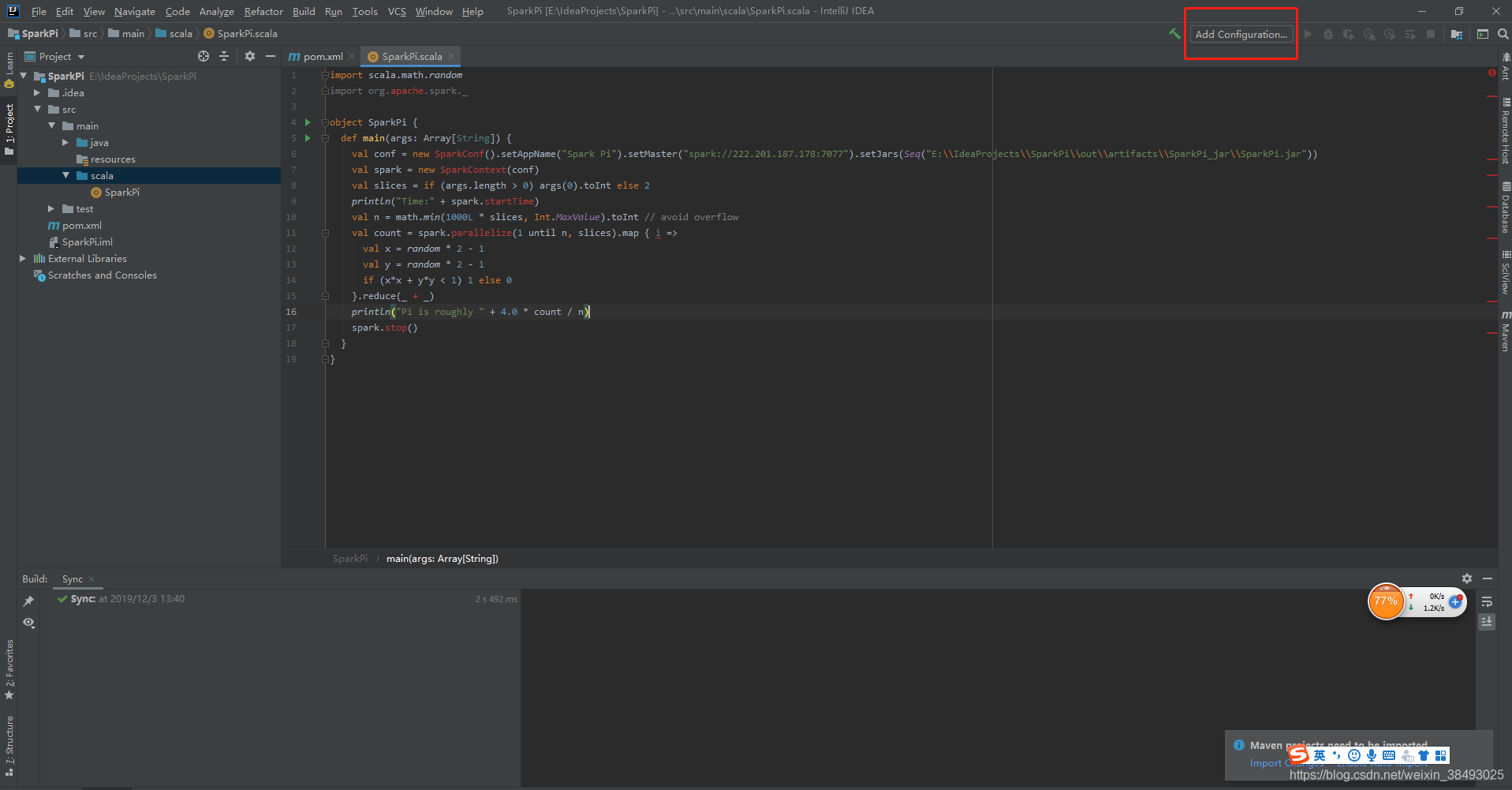
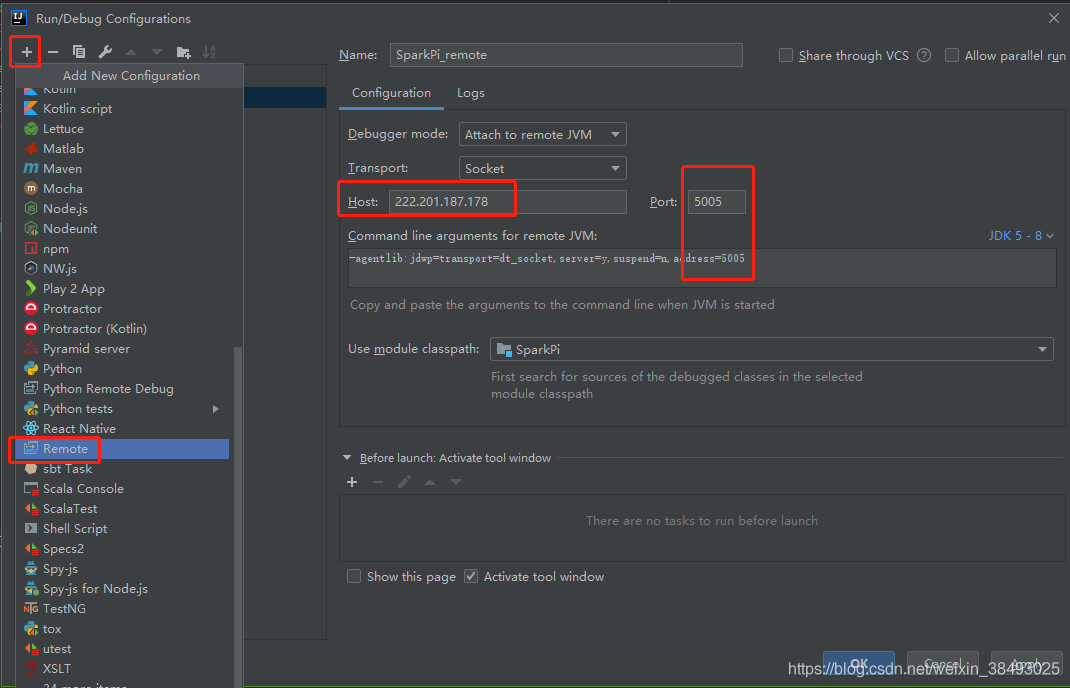
11、配置完成,右键run执行scala程序。初次运行报错如下,选择右下角弹窗中的enable auto import,然后再重新执行一次。

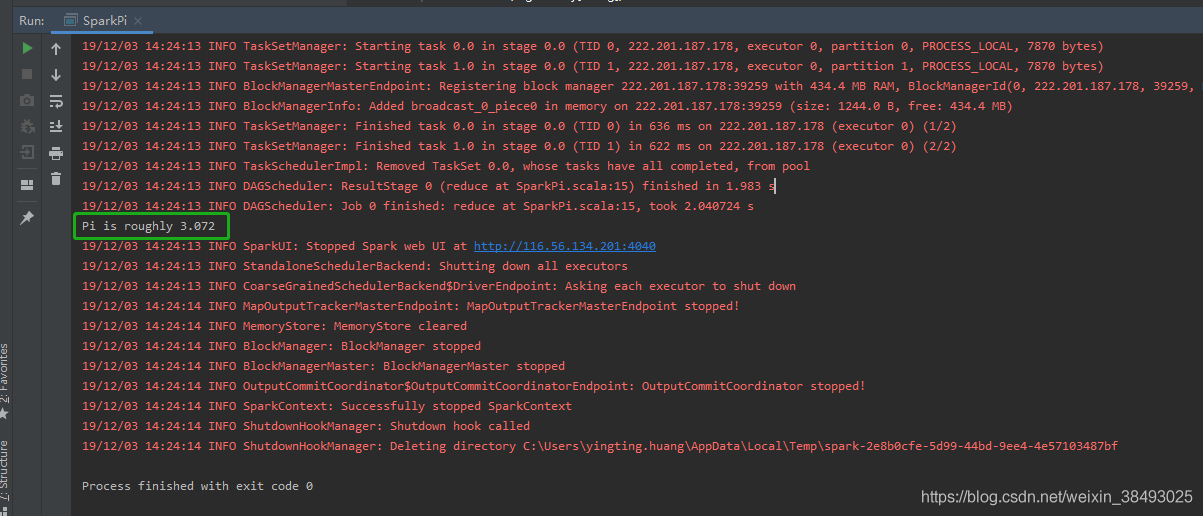
12、结束记得关闭spark集群
sbin/stop-master.sh # 关闭Master节点
sbin/stop-slaves.sh # 关闭Worker节点
cd /usr/local/hadoop/
sbin/stop-all.sh # 关闭Hadoop集群
参考链接:https://blog.csdn.net/weixin_38493025/article/details/103365712