一、使用Docker-compose实现Tomcat+Nginx负载均衡
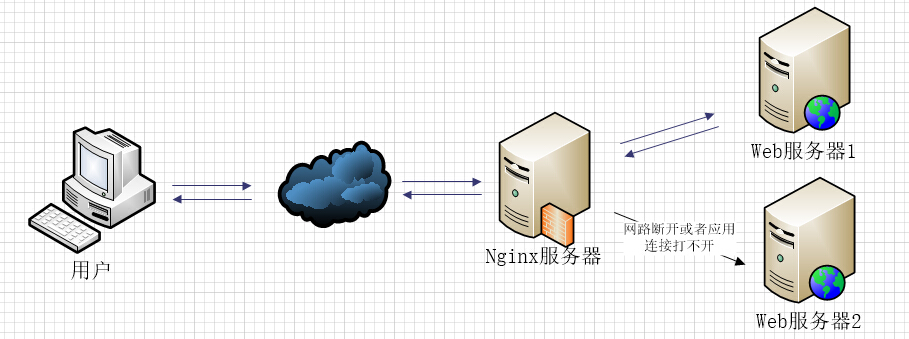
Nginx反向代理机制:简而言之就是Nginx服务器与服务商众多个web服务器形成一个整体,用户在向服务器发送请求后,Nginx服务器给web服务器代理这些请求,然后选择某个web服务器交互,然后将应答返回给用户。而这些过程是对用户透明的。
-
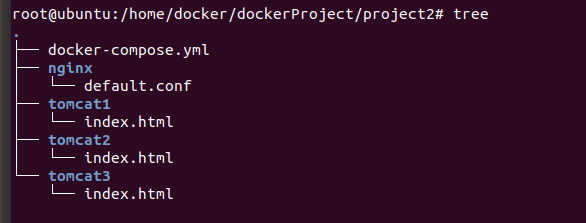
项目结构
-
nginx负载均衡配置文件的重点部分
upstream tomcats {
server nt-tomcat1:8080 ; #tomcat服务器
server nt-tomcat2:8080 ;
server nt-tomcat3:8080 ;
ip_hash;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location / {
root /usr/nginx-3/html ;
index index.html index.htm ;
proxy_pass http://tomcats ; #请求tomcats
}
-
nginx的docker-compose文件
version: "3" services: nginx: image: nginx container_name: nt-nginx ports: - "80:80" volumes: - ./nginx/default.conf:/etc/nginx/conf.d/default.conf depends_on: - tomcat1 - tomcat2 - tomcat3 tomcat1: image: tomcat container_name: nt-tomcat1 volumes: - ./tomcat1:/usr/local/tomcat/webapps/ROOT tomcat2: image: tomcat container_name: nt-tomcat2 volumes: - ./tomcat2:/usr/local/tomcat/webapps/ROOT tomcat3: image: tomcat container_name: nt-tomcat3 volumes: - ./tomcat3:/usr/local/tomcat/webapps/ROOT
-
docker-compose up -d 搭建nginx+tomcat环境

-
编写运行python文件来对服务器request,测试负载均衡3种策略
1、轮询方式(默认):对客户端请求,nginx服务器与每个服务器逐个交互
upstream tomcats { server tomcat1:8080 ; server tomcat2:8080 ; server tomcat3:8080 ; }

2、给服务器设定权重:多个请求下每个服务器占不同服务次数的比例
upstream tomcats { server tomcat1:8080 weight=1; server tomcat2:8080 weight=2; server tomcat3:8080 weight=3; }

3、iphash:相同客户端ip只访问一个服务器
upstream tomcats { server tomcat1:8080 ; server tomcat2:8080 ; server tomcat3:8080 ; ip_hash; }
(2) 使用Docker-compose部署javaweb运行环境
-
就尝试跑一下酒馆管理的样例吧

-
登入
-
基本增删改查

-
给以上javaweb增加nginx反向代理,并实现负载均衡
#docker-compose.yml
version: '2' services: tomcat1: image: tomcat:7 container_name: nmt-tomcat1 ports: - "5050:8080" volumes: - "$PWD/webapps:/usr/local/tomcat/webapps" networks: webnet: ipv4_address: 15.22.0.17 tomcat2: image: tomcat:7 container_name: nmt-tomcat2 ports: - "5051:8080" volumes: - "$PWD/webapps:/usr/local/tomcat/webapps" networks: webnet: ipv4_address: 15.22.0.16 mymysql: build: . image: mymysql:test container_name: nmt-mysql ports: - "3306:3306" command: [ '--character-set-server=utf8mb4', '--collation-server=utf8mb4_unicode_ci' ] environment: MYSQL_ROOT_PASSWORD: "123456" networks: webnet: ipv4_address: 15.22.0.6 nginx: image: nginx container_name: nmt-nginx ports: - "8080:8080" volumes: - ./default.conf:/etc/nginx/conf.d/default.conf networks: webnet: driver: bridge ipam: config: - subnet: 15.22.0.0/24 gateway: 15.22.0.2
#nginx的配置文件default.conf
upstream tomcats { server nmt-tomcat1:8080 weight=1; server nmt-tomcat2:8080 weight=2; } server { listen 80; server_name localhost; location / { proxy_pass http://tomcats ; }
以上参考大佬的思路,理解一下就是再创建一个tomcat容器作为web服务器运行webapp,然后nginx容器作为反向代理服务器来代理两个tomcat服务器,策略为权重询问。
3)使用Docker搭建大数据集群环境
-
拉取原生Ubuntu镜像,安装openjdk和hadoop环境
-
apt-get安装openjdk后需要修改环境变量并生效
-
把下载好的hadoop的压缩包解压到ubuntu的/usr/local下
-
这里如果缺少某些功能指令请先app-get相关,如vim,ssh等
-
-
设置ssh免登录
-
进入~/.ssh环境(即含有.ssh隐藏目录)下,
ssh-keygen -t rsa 获取密钥 -
生成密钥后存储在id_rsa文件下,cat id_rsa.pub >> authorized_key 写入密钥
-
这里需要在环境变量文件bashrc下写入 /etc/init.d/ssh.start指令,即在打开容器时自动执行获取免登入
-
-
配置hadoop相关文件
-
到hadoop安装目录下的etc/hadoop内配置一下文件
-
到hadoop安装目录下sbin内修改内容start-dfs.sh和stop-dfs.sh start-yarn.sh和stop-yarn.sh
-
#core-site.xml <configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop-3.1.3/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>
hdfs-site.xml <configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop-3.1.3/namenode_dir</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop-3.1.3/datanode_dir</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
#mapred-site.xml <configuration> <property> <!--使用yarn运行MapReduce程序--> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <!--jobhistory地址host:port--> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <!--jobhistory的web地址host:port--> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <!--指定MR应用程序的类路径--> <name>mapreduce.application.classpath</name> <value>/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/lib/*,/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/*</value> </property> </configuration>
#yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> </configuration>
#start-dfs.sh和stop-dfs.sh HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
#start-yarn.sh和stop-yarn.sh YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
-
容器->镜像保存,生成hadoop集群的3个容器(master、slave01、slave02)
-
docker commit指令将容器配置保存成镜像,因为Ubuntu原生镜像的容器在关闭会所有配置会初始化。
-
docker run去创建3个含有hadoop+jdk环境的ubuntu镜像容器
-
修改etc/hosts文件内的主机ip映射,还有hadoop安装目录下的/etc/hadoop/workers增加工作者
-
-
格式化并启动hadoop
cd /usr/local/hadoop-3.1.3 bin/hdfs namenode -format #格式化 sbin/start-all.sh #全部打开
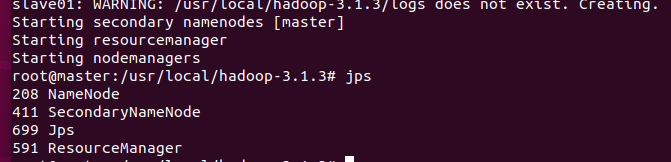
jps #查看节点是否全部打开
——以上过程参考前面大佬标答和docker配置hadoop集群教程 ,由于中途过多bug导致截图省略。。。
部署完成:
master节点
slave02节点
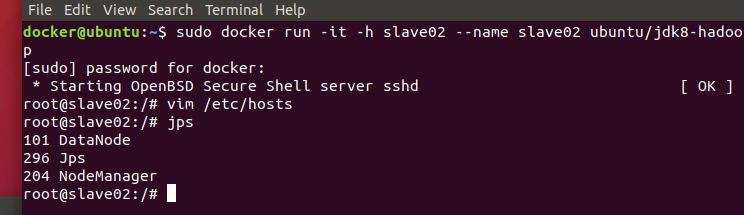
slave01节点
测试样例:
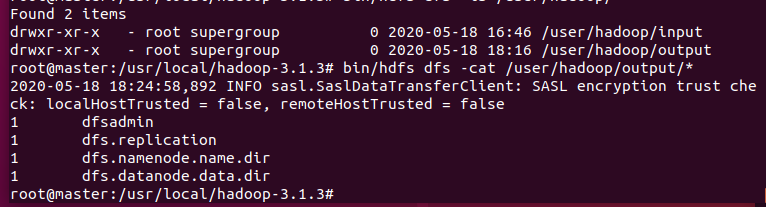
现在创建一个工作目录:hdfs dfs -mkdir /user/hadoop/input
然后将本地usr/etc/下的*.xml文件上传至hadoop的/user/hadoop/input下: hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
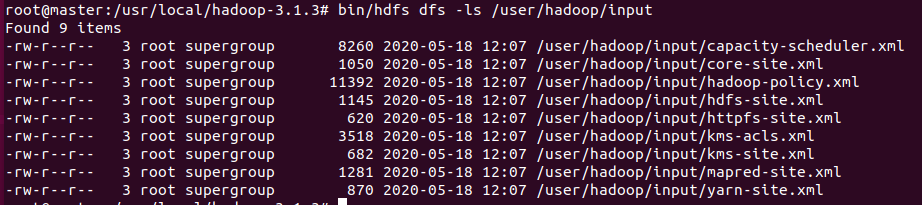
可使用grep功能测试数据:
bug1:
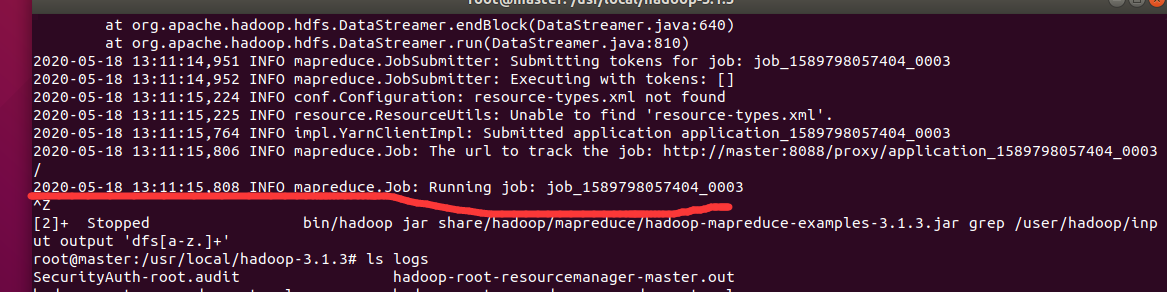
卡住跑不动,修改过yarn的虚拟物理内存比例的配置了也不行。。。logs下面所有的日志文件看过去看不出明显的bug
怪自己菜把,可能前面配置时候出了一些bug补完还是遗存错误吧
重做一遍,bug2:
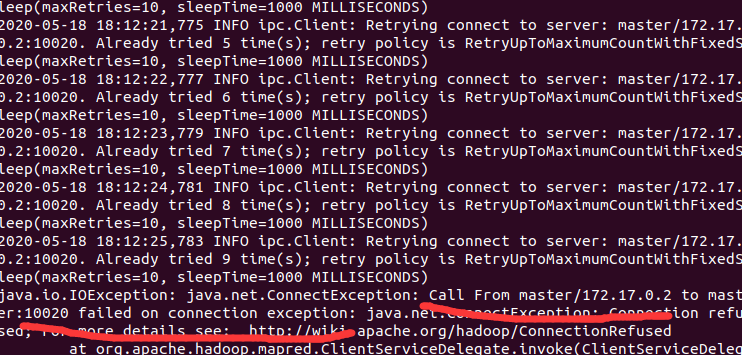
一开始显示跑一半连接失败connection refuse,然后nadenode也关闭了。
重启容器(hosts会被格式化,但hadoop的缓存依然还在),重写hosts文件后继续跑样例突然能跑还流畅了。。。但突然疯狂重连然后失败。。。
重试n次之后:突然成功
实验总结
做崩了...
前两个实验现在看来,虽然刚接触nginx反向代理和tomcat轻量级web服务器,但显然第一个实验对于学习nginx反向代理的大致理念-代理服务器,和负载均衡的简单应用是可以接受的。
但对于最后一个hadoop集群,一开始以为之前做过大数据hadoop从单机、伪分布、完全式分布的相关再到文件系统的流畅的使用,但显然docker镜像下的hadoop集群架构着实有一些坑点会给人带来困难。
一开始不知道为何ubuntu镜像不能拉取openjdk8,于是拉去default-jdk(教程上的),突然就下了个openjdk11,想说大不了后面一些环境变量改一改就行,呵呵版本不兼容

然后如果是你,肯定觉得卸载重装一下呗?呵呵,按着网上教程去卸载重装,你会发现删不干净!好吧即使我最后删完已经可以显示java版本1.8,但java list下依然还有jdk11
然后硬着头皮跑到最后,发现如上bug1:卡住了!群里老师解答:yarn-site.xml下的虚拟内存和物理内存比例配置——哦~我好像忘了写...重新配置,fail again。。。
最后,干脆重新用原生镜像一步一步仔细地做,做到最后似乎还很顺利,bug2 is coming~slave02主机请求master一直会连接失败,第一次失败后master内的hdfs断连,namenode关闭,重启start-all.sh节点有重新恢复正常,继续跑...失败如是
然后突然一次死机,重开机后重新配置,感觉似乎好起来了,mapredure开跑了!然后还是会产生断连...数次之后离奇成功。
总结经验:照着大佬的教程都能失败?菜要承认,挨打站稳
再附:

竟然继一次开头彩后,wordcount也能跑成功了。。。