参考:https://www.cnblogs.com/aspwebchh/p/6652855.html
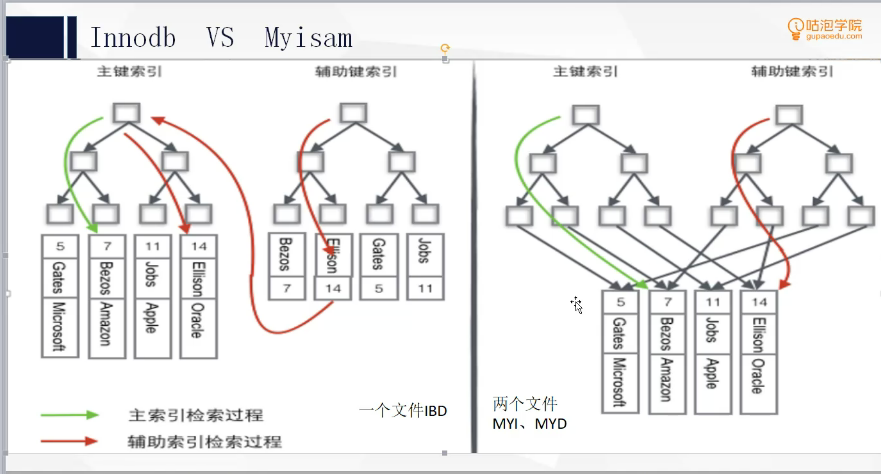
对于mysql而言,常用的是innodb和myisam引擎,只有innodb有聚集索引
1、聚集索引
一般是主键,可以自己指定。一个表只能有聚集索引,它的特点是索引的排列顺序和表记录的排列顺序相同。这区别于非聚集索引。
当表没有建立聚集索引时,表数据的无序的排列在磁盘上。创建聚集索引后,表数据向二叉树一样分布在磁盘上。

除了最底层数据,其他节点都是聚集索引,当sql通过聚集索引查询时,他们会先通过上面的节点快速定位到数据具体的位置,再查询信息。
2、非聚集索引
就是我们经常自己创建的索引了,非聚集索引可以创建多个。当我们再某个字段创建索引时,该字段会被复制一份用来生成索引。当sql通过该索引查询时,会先在索引查询到数据的聚集索引,在通过聚集索引查询到具体的数据。除了覆盖索引外,其他的索引查询都会用到聚集索引。

截图一张咕泡的公开课的图(侵删)
3、优缺点
优点很明显了,查询快。但是缺点也显而易见:
1、每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
2、每次增删改数据都会改变各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, 数据库必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销。
4.设计索引
(单字段索引,多字段索引相同)最左原则,离散型高原则,宽带小原则
5.覆盖索引
如果需要查询的字段就是索引字段,则查询的适合,可以直接从索引出获取数据,不需要查询具体的数据,减少io