事务具有ACID,atomic原子性,consistent一致性,isolation隔离性,duration持久性
atomic:将所有sql都当做原子单位来执行,即要么全部执行要么全部不执行。
consistent:事务执行完毕后,所有数据的状态都应该是一致的,如果a的钱少了b的钱就必须增加
isolation:如果有多个事务并发执行,则每个事务做出的修改必须与其他事务进行隔离。
duration:事务对数据库的修改会被持久化存储。持久化即把数据保存到硬盘中,使得应用程序或机器重启后可以访问修改之前的数据。
最经典的使用事务情况:比如转账,如果a向b转100元,那么必须保证a的账户减少的同时b的账户增加,如果转账过程中出现了异常就必须回滚到转账之前。
隔离级别:
Read-Uncommitted:读未提交,一个事务会读取到另一个事务更新后但是没提交的数据,这样这个事务读取到的数据就会有两种情况,这就是脏读
数据表:
事务A:
set transaction isolation level read-uncommitted;
begin;
update tb_user set name="zyhtrans" where id=1;
事务B:
set transaction isolation level read-uncommitted
begin;
select * from tb_user where id=1
这个时候事务B查询到的数据是:
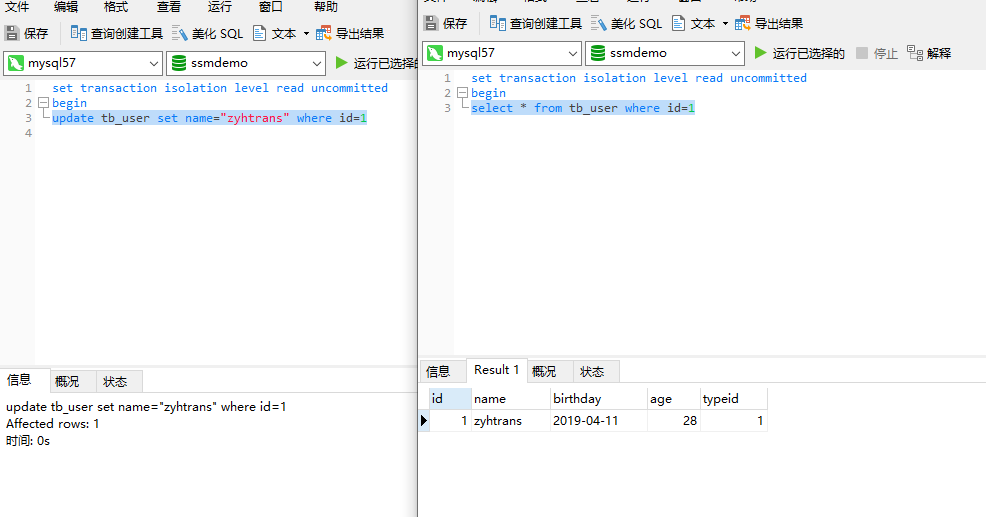
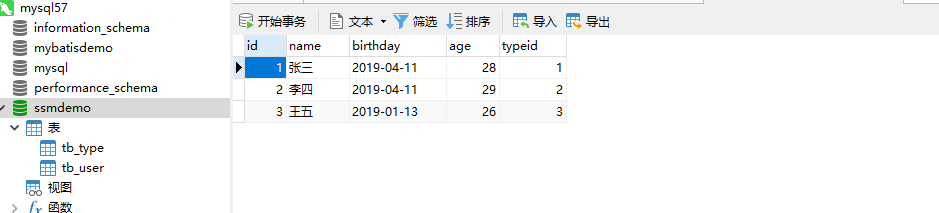
实际上数据库并没有修改
然后事务A进行回滚ROOLLBACK,事务b再次执行select语句又会出现另外一种数据
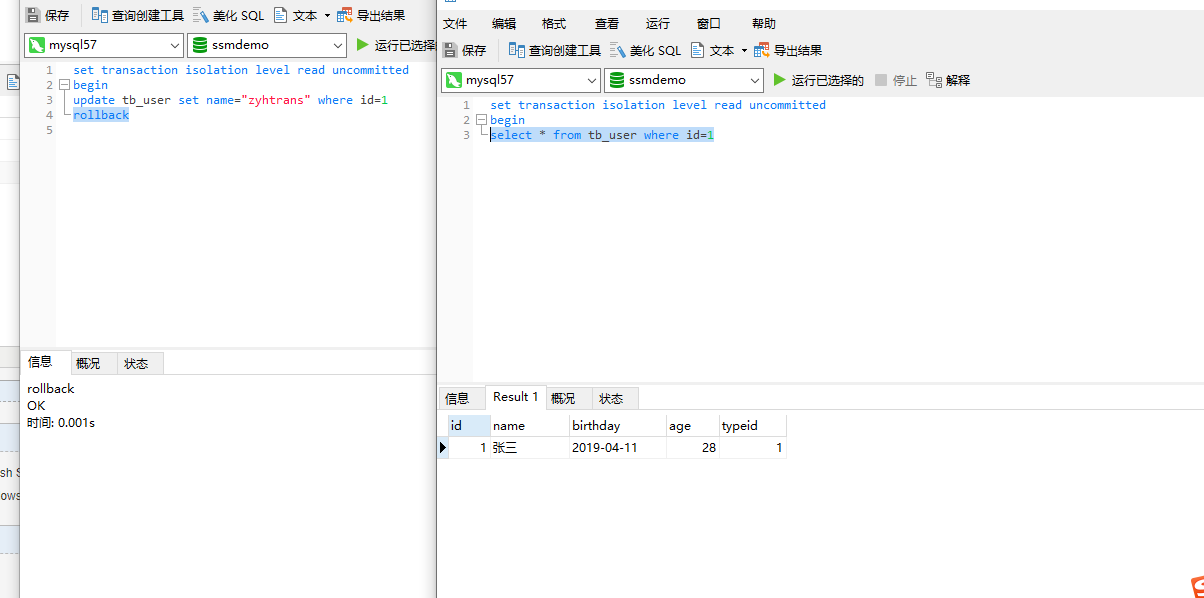
这就造成了事务B读取到的数据不一致,这就是脏读,所以这种最低层次的隔离会造成脏读
read-committed:读已提交,一个事务先读取一次数据,另一个事务对数据进行了更新并提交,让后这个事务再次读取数据就会读取到不同的数据。

第一次读取到的name是张三,然后一个事务对其进行了update修改并且committed提交了,这次另一个事务再读取就会出现不同的数据。
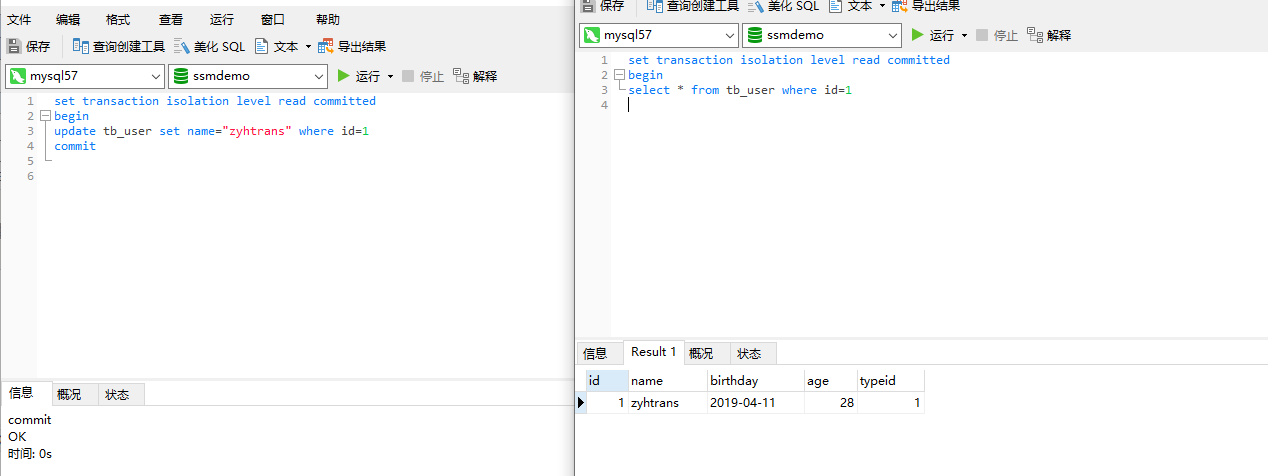
并且数据库也已经修改

这下就会造成读取出来的两次数据不同,这就是不可重复读(为什么叫做不可重复读我也不是很理解)。个人认为它与read-uncommitted的区别就是脏读是先事务a先更新,然后事务b读取,其次事务a再回滚或者事务a根本就没有提交(committed),事务b又读取,这就造成了结果不同,
read-committed是事务b先读取,然后事务a再更新并且提交,其次事务b又读取就会发现与第一次(就是事务a没更新前)的结果不一样。
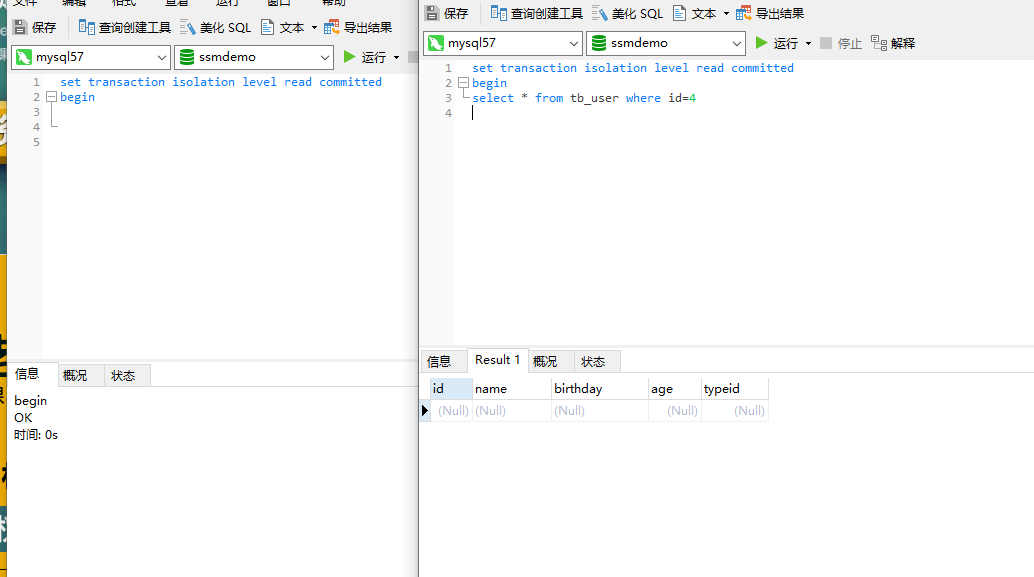
Repeatable Read:可重复读,事务b读取一条数据发现为空,在这个时候事务a对这条数据进行了增加并且提交,然后事务b对之前的空数据进行修改发现竟然可以成功(怕是出现了幻觉),然后再次读取这条数据发现这条数据出现了(见鬼了....),这就是可重复读.
事务b查询id为4的数据,发现为空(肯定为空因为里面没有这条记录,可以看我最开始的表结构里面的数据↑)
此时事务a进行一条插入操作并且提交
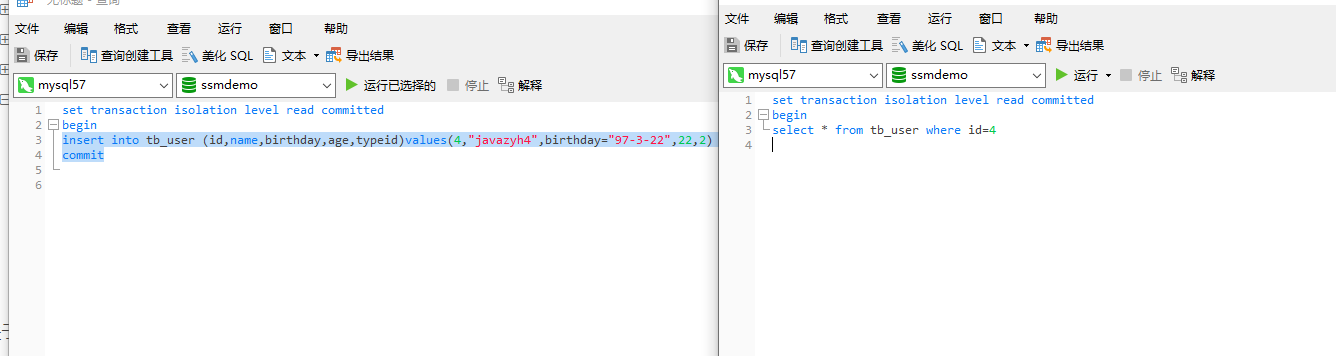
此时数据库中便有了id为4的数据。birthday为空的原因是类型不对(请忽略这个细节啊啊啊...)
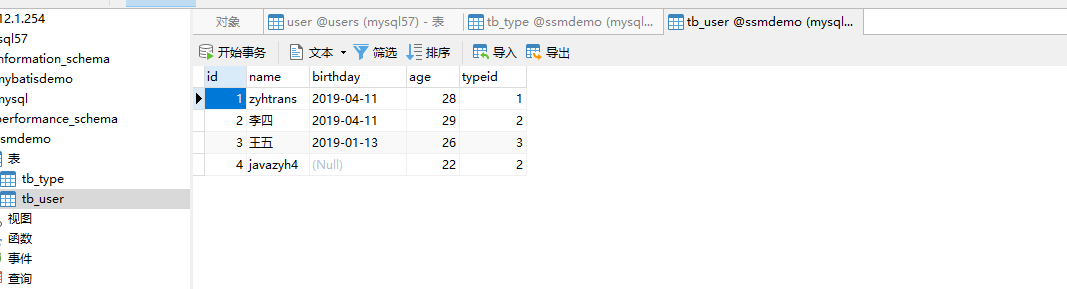
此时事务b执行update语句修改发现可以成功,再次查询发现竟然有这条数据(可能是有幻觉)
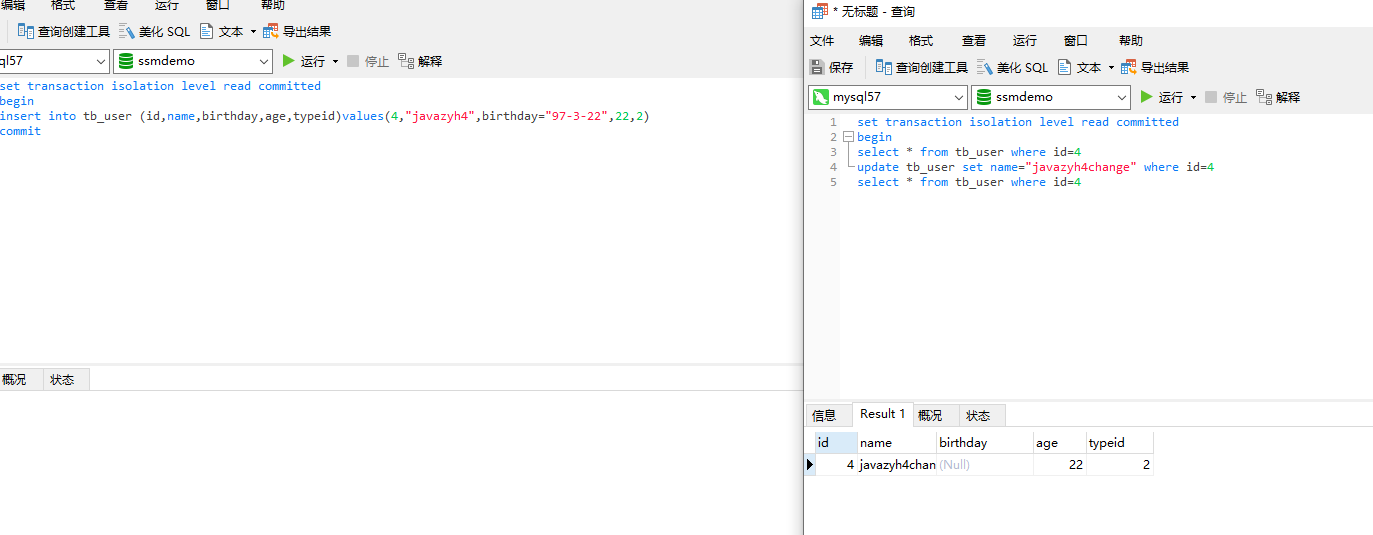
这就是Repeatable Read可重复读,会出现幻读的情况。
Seralizable:串行化,所有事务都有顺序的执行,是最严格的事务隔离机制,但是由于事务是串行执行会造成效率下降,一般不用。
在mysql中如果使用的innoDB引擎,默认的事务隔离级别就是RepeatableRead。
强烈推荐sql基础不好的或者没有看懂去这:https://www.liaoxuefeng.com/wiki/001508284671805d39d23243d884b8b99f440bfae87b0f4000/001540475016682b81322ee2a484261a7527f3bb1b4a3dc000