Hive是一种用于执行离线计算的数据仓库工具,基于Hadoop的HDFS与MR实现。
Hive偏重于数据的分析和处理,使用映射关系将结构化的数据映射为表的结构。
例如:基于数据(1,zhangsan,123456,男)对应生成(id+uname+pwd+sex)的映射
Hive能够实现非Java用户对HDFS数据的MR操作。
数据仓库
-
分为OLAP联机分析处理,OLTP联机事务处理
-
通过对以往数据的分析,对现有和未来业务提供数据支持
-
对数据处理分为:
OLAP联机事务处理,负责数据事务处理,关系型数据库的主要应用
OLAP联机分析处理,负责数据分析处理,数仓的主要应用
-
数仓中的数据模型包括:
星型模式(单一中心节点)
雪花模型(一个中心节点多个分支节点)
星系模型(多中心节点)
-
数仓基本用于执行对数据的查找和统计,一般不会删除数据或修改数据
Hive架构
-
client
客户端包括三种方式
命令行模式——直接通过HQL(Hive Sql)执行操作
JDBC/ODBC模式——通过java代码操作,需借助ThriftServer将代码转为HQL
WebUI——通过web端输入HQL,远程执行任务
-
MetaStore
-
元数据存储器,用于存储Hive建表语句,也就是描述Hive与数据的映射关系的数据
-
元数据包括:表,表的列、分区、属性、表的属性,表的数据所在目录
-
元数据会存放在关系型数据库中(mysql)
-
-
Driver
-
解析器——将hql解析为语法树
-
编译器——将语法树转换为逻辑执行计划
-
优化器——重写逻辑执行计划实现优化
-
执行器——将逻辑执行计划转换为物理执行计划(MR-JOB)
-
-
基于Hadoop-Yarn+Mapredce+Hdfs执行物理执行计划
Hive搭建
-
前提:mysql与Hadoop安装完成
-
在mysql中添加一个库用于存放Hive的映射
create database hive_single;
-
将安装包解压到指定位置
tar -zxvf apache-hive-1.2.1-bin.tar.gz
cp -r apache-hive-1.2.1-bin /opt/sxt/
mv apache-hive-1.2.1-bin hive-1.2.1
-
修改配置文件
cp hive-default.xml.template hive-site.xml
删除原始内容中configuration标签下的内容(3891行)填入如下内容
<!--hive数据在hdfs中的路径-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive_single</value>
</property>
<!--是否本地单机模式-->
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<!--mysql连接,需要指定数据库名,例如hive_single-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_single?createDatabaseIfNotExist=true</value>
</property>
<!--mysql驱动、用户名、密码,注意这个是liunx中安装的mysql-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property> -
拷贝mysql的jar包到lib目录(mysql-connector-java-5.1.32-bin.jar)
-
解决Hadoop与Hive的jar版本差异(将jline文件替换)
cd /opt/sxt/hadoop-2.6.5/share/hadoop/yarn/lib/
rm -rf jline-0.9.94.jar
cp /opt/sxt/hive-1.2.1/lib/jline-2.12.jar ./
-
配置PATH
vim /etc/profile
export HIVE_HOME=/opt/sxt/hive-1.2.1 export PATH=$HIVE_HOME/bin:$PATH(注意加上其他软件的路径)
source /etc/profile
-
Hive启动命令:hive
查看库命令show databases;
创建库create database myhive;
使用库use myhive;
创建表create table user;
-
保存快照
Hive-SQL
-
HQL语句结尾要加分号;
-
进入命令行 hive
-
清空页面 !clear;
-
DDL用于执行数据库组件的定义(创建修改删除)
DDL需要注意库,表字段命名的规范
DDL官方文档https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
数据类型
基本类型
-
整型
int(4byte) tinyint(1bety) smallint(2byte)bigint(8byte)
-
浮点型
double(8byte) float(4byte)
-
字符型
string char(定长) varchar(不定长)
-
boolean型
true/false (1位)
-
时间型
timestamp时间戳 date日期
类型转换
-
自动
整型隐式转为范围大的整型
所有整型,float,string可以隐式转为double
int,tinyint,smallint能转为double
double不能转型为其他数据类型
-
强制
例如:cast('1' as int)
-
表设计时须设置合适的数据类型避免类型转型
引用/复合类型
由基本类型构成,复合类型可以相互嵌套
-
Array
-
存放相同类型的数据
-
以索引排序,索引从0开始
-
获取数据的格式为:user[0]
-
-
Map
-
存储任意数量的键值对,适用属性的数量和类型均不确定的情况
-
通过key取值,map['key1']
-
key不能相同,相同的key会相互覆盖
-
-
Struct
-
结构体,内部的属性与属性的类型固定
-
通过属性获取值:info.name(获取info结构体中name的属性)
-
DDL库操作
-
创建数据库
create database sxt;
create database if not exists sxt;
create database sxt location '/hive_single/sxt_path' 指定数据库在hdfs的路径(路径名与数据库名可不同,创建时不会将原路径数据清除)
-
删除数据库
-
drop database if exists sxt cascade;
删除库,并将库所在文件夹删除
-
drop database sxt ;
删除空库
-
-
使用数据库
use sxt ;
-
查看数据库
show databases;查看所有数据库名
show databases like 's*'; 匹配查找数据库
desc database sxt;查看库内的表
-
修改数据库(了解)
无法修改数据库名和数据库所在路径。只能修改其他数据
alter database sxt set dbproperties('createtime'='20170830');
DDL表创建
-
external 是否是外部表,不加该关键字则默认内部表
-
定义每一列
所有列在括号内,相互通过逗号分隔
(col_name data_type [COMMENT col_comment], ...)
-
普通列: name string
-
数组: books array< string>
-
map: score map<string,int>
-
struct: info struct< name:String,age:int>
-
-
COMMENT col_comment 列注释
-
COMMENT table_comment 表注释
-
分区
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
-
分桶
[CLUSTERED BY (col_name, col_name, ...) ]
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
-
每一行的数据切分方式
ROW FORMAT row_format
-
字段分隔,array分隔,结构体与map的K-V分隔符,行分隔符
-
注意顺序不能改变
-
默认行以 分隔,可以省略
ROW FORMAT delimited
fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by ' '; -
-
数据存储格式
STORED AS file_format 用于数据压缩等情况
-
数据文件的地址
LOCATION hdfs_path
内部表和外部表均能指定表HDFS路径,LOCATION 是一个文件夹
location '/hive_single/sxt';
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
(col_name data_type [COMMENT col_comment], ...)
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) ]
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
实例:
文本格式:
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
json格式:
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}
create table person(
name string,
friends array<String>,
children map<String,int>,
address struct<street:string,city:string>
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '
'
外部表与内部表
表默认为内部表,使用external则为外部表
表创建时都不会将已有文件夹中的数据清除。
内部表
-
内部表处理独享的数据,适用于单次处理的数据,不适合于其他工具共享数据
-
删除表时表路径中的原始数据也会删除,若指定location的内部表会将location的一级目录删除
外部表
-
定义表可定义location路径,实现和其他表共享数据文件
-
删除外部表时只删除元数据信息,location目录下的数据将被保留
create external table person(name string)
location '/myhive/sxt';
内外表切换
-
alter table sxt set tblproperties('EXTERNAL'='TRUE'); 内转外
-
alter table sxt set tblproperties('EXTERNAL'='FALSE'); 外转内
表删除与清空
-
表删除(外部表不清除原始数据)
drop table [if exsits] t_user;
-
清空表数据,直接截断
truncate table_name;
-
查看表结构
desc table_name ;
表修改(了解)
-
改表名
alter table t_oldName rename to t_newName;
内部表会将对应文件目录名修改,若指定了location则将location原目录移动到默认路径下
外部表不会影响location地址的数据,不指定location也不会对默认路径进行修改
-
更新列
alter table table_name change [column] col_oldName col_newName column_type [column col_comment] [FIRST|AFTER column_name];
-
增加替换列
alter table table_name add|replace columns(col_name data_type [备注], ...);
数据载入
load载入
load data [local] inpath '/root/path' [overwrite] into table table_name
-
local,表示路径为linux路径,否则默认为HDFS路径
-
overwrite,表示覆盖载入,将表文件中原有的数据覆盖,否则默认为追加
-
load 加载不执行MR操作
-
local文件将被复制到HDFS的表目录中,HDFS文件则剪切到表目录。
insert载入
insert会启动MR操作,一般用于将原表的查询结果插入到新表中。
overwrite(覆盖) 和 into(追加),可以相互替换
单表插入
-
insert overwrite table t2 select xxx from t1;(将表1的xxx字段插入表2中)
多表插入
-
from t1
insert overwrite table t2 select xxx1
insert overwrite table t3 select xxx2; (将表1的xxx字段插入表2中)
单记录插入(一般不这么做)
-
insert into t1 values ('id','5'),('name','zhangwuji');
表数据导入导出
计算导出
通过insert将查询结果保存为数据文件,执行了MR操作且只保存数据文件
insert overwrite local directory '/root/data_out'
row format delimited fields terminated by '-'
select * from mytable;
加入local表示导出到本地 linux的文件路径中,不加location则表示导出到HDFS的文件路径中
row format部分表示输出数据的间隔方式,与表定义类似
直接导出
-
导出,将表数据及表结构指定hdfs路径下,在该路径下保存元数据文件与数据文件夹。
export table t_name to '/hdfs_path'
-
导入,将文件夹导入到命名空间,直接在命名空间下生成导出的表及数据
import from '/hdfs_path'
恢复后的文件夹名与表名相同,表自生属性也被保留(外部表属性,内部字段等)
分区
为了减少全表扫描查询的问题,根据指定字段的值,对数据进行分区存储(分多个文件夹存储)
定义分区表
--定义分区表时,可以指定多个分区属性
create table t_name(id int,name string)
partitioned by (addr string , work string)
row format delimited fields terminated by ',';
分区层级分为:单分区和多分区
-
单分区:只有一种分区。按照单一属性值分区
-
多分区,包含存在父子关系的多种分区。先依据父级属性分区,再依据子级属性分区
分区操作
-
添加分区 alter table t_name add partition(column='xxx');
-
删除分区 alter table t_name drop partition(column='xxx');
-
查询分区 show partitions t_name;
静态分区
数据载入
load data [local] inpath '/path' into table 't_name' partition (column1='xxx',column2='yyy');
静态载入的数据,会复制到对应的分组文件夹下,若无则自动创建文件夹。
数据只能载入到一个文件夹中,且查询时hive直接从文件夹中取数据,不再对分组字段处理。若文件中存在分组字段实际数据与分组数据不匹配,也将该字段值视为指定的分组数据。
动态分区
-
开启动态分区指定如下
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
-
开启动态分区后再创建主分区表
create table table1( id int, name string ) partitioned by (novel string,sect string) row format delimited fields terminated by ',' ;
-
创建外部临时表,临时表的字段与主分区表字段相同,临时表的location指向数据源
create external table table2 ( id int, name string, novel string, sect string ) row format delimited fields terminated by ',' location '/path' ;
-
使用insert语句通过临时表将数据载入主表,期间执行的MR操作
insert overwriter table table1 partition(novel,sect) select id,name,novel,sect from table2;
分桶
根据指定的列,对列值hash计算,根据结果将数据存入对应桶,能够将数据有效散列到桶中。分桶需要执行MR,桶的数量与reduce相同,计算结果输出到对应的桶文件中。
效果:使得桶中的数据较为均匀,便于统计计算。相同的key必然在一个桶中,降低表连接的数量。
数据插入:依赖于insert方式的数据插入。
-
指定列需要满足:经常被查询,自身散列较好
-
分桶可以在分区的基础上执行
-
分桶的数据需要具备较多的公约数,便于查询(12的公约数:1,2,3,4,6)
分桶建表语句
create table table01( id int ,name string,age int) clustered by (name) sorted by (age) into 6 buckets ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; --说明 按照name属性分桶,桶内通过age实现排序
分桶表的取样SQL
tablesample(bucket x out of y on 分桶列 )
-
第二个参数表示将桶分为多少组,其为分桶数的公约数
-
第一个参数表示每个组中取几个桶进行计算
-
参数1不大于参数2
select * from table01 tablesample(bucket 1 out of 3 on name );
复杂映射建表
通过正则将列与复杂数据进行映射,能够匹配复杂文本
--基本格式
create table table_name(column type,...) row fromat serde 'org.apache.hadoop.hive.serde2.RegexSerDe' with serdeproperties("input.regex" ="正则")
正则中每个括号内的部分对应前面定义的列
例子如下:
原始文件格式: 192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 - 192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304 - 192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
--建表语句 create table t_log( host string, identity1 string, identity2 string, time string, request string, referer string, agent string,) row fromat serde 'org.apache.hadoop.hive.serde2.RegexSerDe' with serdeproperties( "input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \[(.*)\] "(.*)" (-|[0-9]*) (-|[0-9]*)" )
映射说明: 括号内的内容匹配每个列,对应关系如下 host 192.168.57.4 identity1 - identity2 - time 29/Feb/2016:18:14:35 +0800 request GET referer /bg-upper.png HTTP/1.1 agent 304
DQL语句
-
SQL 语言大小写不敏感。
-
SQL 可以写在一行或者多行
-
关键字不能被缩写也不能分行
-
各子句一般要分行写,注意tab键会导致命令异常
Hive SQL的使用和数据库SQL基本上是一样的
主要语法
-
表连接支持99语法
-
排序
sorted by 对deduce数据的数据进行排序
order by 对全部数据进行排序
-
分页
limit x 展示前x行记录,与排序组合实现展示最大(小)值
limit x,y 展示x-y行记录
-
组函数
max min avg sum count 组函数一般与group by组合使用
-
选择函数
nvl(obj,default) 单行选择函数
相当于obj==null?default:obj,若obj为空则取默认值,否则取自身的值
非关系型数据库DQL
split(column,'-') 将字段分隔为数组,以某个字符串作为间隔
explode(split(column,'-)) 将分割的数组展开,但不能直接与普通列同时使用
lateral view explode(split(column,'-)) typeTable as xxx 将列展开成表,再与普通列出现在一行
--数据 nezha js,gx,qq,dm meirenyu gx,kh,aq xingjidazhan kh,js huoyingrenzhe dm,qj,yq,aq --表 create table t_movie( name string,type string) row format delimited fields terminated by ' '; --查询 select name,xxx from t_movie lateral view explode(split(type,',')) tempTable as xxx;
内置函数
内置运算符
-
关系运算符
A = B;A is null;A like B
返回boolean
-
算数运算法
+,-,*,/,%,|,^,~
适用于数值计算
-
逻辑运算符
and,or,not,&&,|,!
适用于布尔值运算
-
复杂函数
-
定义
-
map(k1,v1,k2,v2...)
-
struct(v1,v2,v3...)
-
array(v1,v2,v3)
-
-
操作
-
A[n] 数组A的第n个元素,从0开始
-
M['key'] 数组M中key对应的值
-
S.x 结构体S中的x属性值
-
-
内置函数
-
数字函数
数值计算相关函数,包括取值,随机,转进制,绝对值...
-
字符串函数
长度,分割split,连接,大小写,去空格...
-
collection函数
size(数组/map) 获取长度
-
转型函数
cast(值 as 目标类型)
-
日期函数
与字符串转换,日期的计算相关
-
条件函数
if(boolean,value1,value2)
内置聚合函数UDAF
-
count,sum,avg,min,max;
-
求方差,差值等;
-
collect_set(col)返回无重复的数据
内置表生成函数UDTF
explode(array) 拆分数组
自定义函数
由于内置函数不满足我们的需要,需要自定义函数。(自定义代码实现对指定的数据进行运算,返回所需的结果,中间可以使用java的类库实现复杂操作)
-
UDF(User-Defined-Function) 一进一出
-
UDAF(User- Defined Aggregation Funcation) 聚集函数,多进一出
-
UDTF(User-Defined Table-Generating Functions) 一进多出(了解)
注意:在IDE工具中导入hive依赖jar包 (D:BigData课件及软件第6阶段:Hadoop 离线体系:Hive软件apache-hive-1.2.1-binlib)
以下函数均使用临时函数命令
UDF函数
-
创建项目,导入hive的jar包,创建java类继承org.apache.hadoop.hive.ql.exec.UDF
-
实现public String evaluate(Object value...)方法,该方法为重载方法,可以传入任意类型数据
-
将项目打成jar文件上传至linux系统
-
hive客户端中,清空以前的同名文件,将上传的文件添加到hive函数库中
delete jar /root/xxx.jar
add jar /root/xxx.jar
-
给自定义函数建名称,指定到对应的自定义java类
create temporary function xxx as 'com.jay.Xxx'
-
使用函数
select xxx(empno),xxx(emane) from t_emp;
-
销毁函数
drop temporary function xxx;
自定义函数代码
package com.jay;
import org.apache.hadoop.hive.ql.exec.UDF;
//自定义UDF函数
public class Myudf extends UDF{
//单个参数处理
public String evaluate(String value){
return value+"xxx";}
//多参数处理
public String evaluate(String value1,int value2 ){
return value1+"-"+value2;}
}
UDAF函数
-
创建项目,导入hive的jar包,创建java类继承org.apache.hadoop.hive.ql.exec.UDAF
-
创建静态内部类,实现org.apache.hadoop.hive.ql.exec.UDAFEvaluator
-
重写init方法,该方法至执行一次
-
boolean iterate(Object) 迭代器
-
Object terminatePartial() 临时结果输出
-
boolean merge(Object) 执行合并操作
-
Object terminate() 最终结果输出
调用说明(根据需求调用以上方法)
map过程调用iterate与terminatePartial;
combiner(map合并)调用merge和terminatePartial
reduce调用merge与terminate
-
-
其他步骤与HDF相同,调用UDAF会执行MR
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
public class Myudaf extends UDAF{
public static class aaa implements UDAFEvaluator{
//定义一个中间量,执行所需业务
private int sum;
@Override
public void init() {
System.out.print("初始化,只执行一次");
}
//迭代处理原始数据
public boolean iterate(String value) {
if (value != null)
sum += value.length();
return true;
}
//临时输出
public int terminatePartial() {
return sum;}
//合并
public boolean merge(int tmpSum) {
sum += tmpSum;
return true;}
//最终输出
public String terminate() {
return "sum:" + sum;}
}
}
hive优化
在优化中主要关注
Map的数量,reduce数量,文件数量,切片大小
hive中修改配置属性语句为:set xxx=值;
理解HSQL的执行
表连接
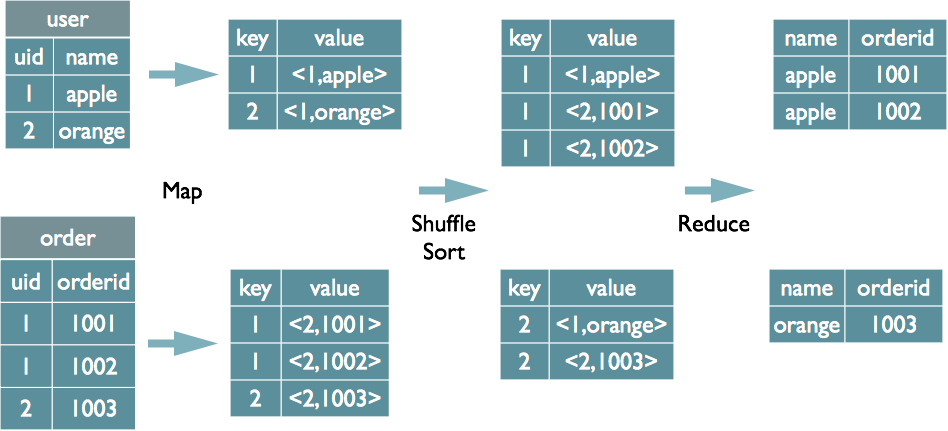
select u.name, o.orderid from order o join user u on o.uid = u.uid
注:uid作为key进行MR
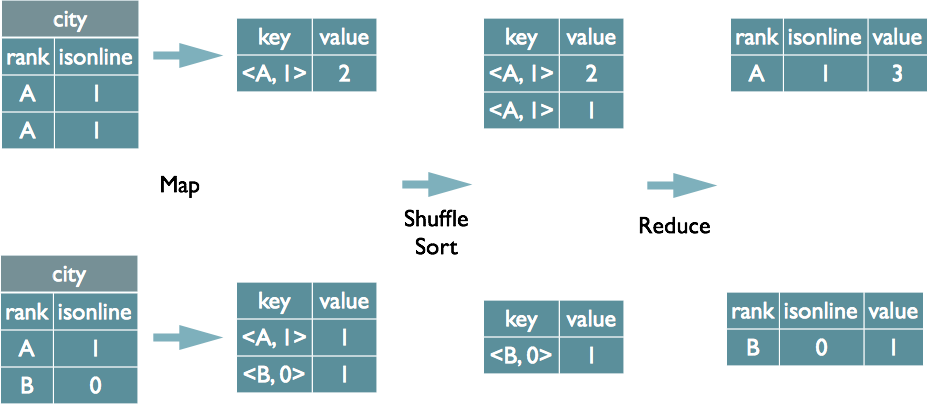
表分组及分组函数
select rank, isonline, count (*) from city group by rank , isonline
注:将rank -isonline作为key
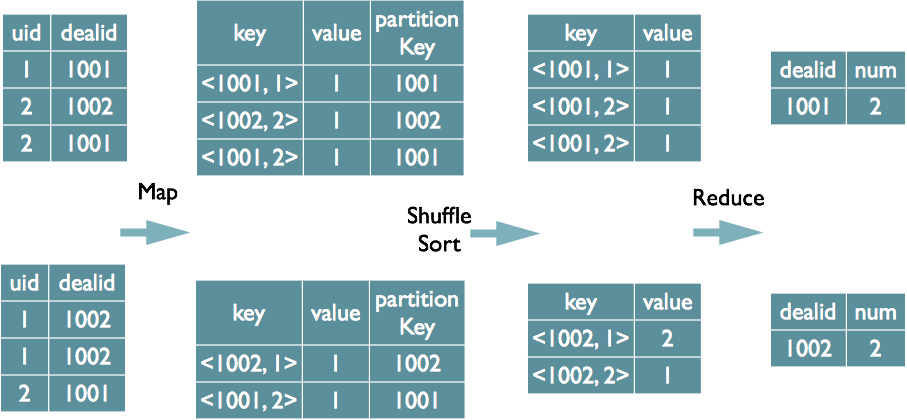
表分组去重
select dealid, count(distinct uid) num from order group by dealid
注:根据dealid执行map之后的分区,根据分区的dealid+去重的uid执行reduce的分组
表多重去重
select dealid, count(distinct uid), count(distinct date) from order group by dealid
方式1:只能在reduce中去重
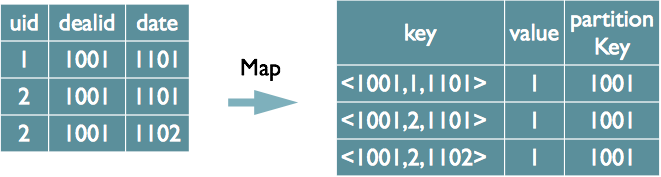
方式2:实现在map中去重
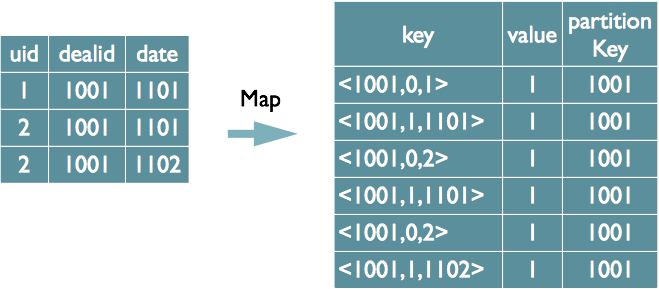
Map表连接优化
-
指定大表和小表。减少了全表连接的数量
-
执行过程:小表节点先执行map,结果载入到hashtable中,各大表节点启动map并将小表执行结果载入内存,在各大表节点执行map合并,再将数据写出到reduce处理。
-
select * from a join b join c; 控制a<b<c,使得hive将a视为b和c的小表,再将b视为c的小表
避免MR执行
-
select与where默认不会导致MR启动
select * from t_emp where id = 8
-
若select中不需要分区和组函数,可以使用hdfs默认的filter进行数据过滤
hive-site.xml中配置如下信息,属性为more时上述情况默认不启动MR
hive.fetch.task.conversion= more不启动/minimal启动
-
insert语句必然执行MR操作
map的数量
-
map任务数量过多,节点容易oom(内存溢出)
map任务数量过少,任务节点少,处理速度慢
-
map数量与切片数量关联,需要根据具体文件大小和内存设置map数
-
通过调整切片大小,可以控制切出的切片数量,进而控制map数量
mapred.min.split.size 最小切片大小默认1B
mapred.max.split.size 最大切片大小默认256MB
上述值用B单位的数字进行设置
reduce数量
数量影响
-
reduce过多产生大量小文件,影响hdfs性能,增加NameNode的负担
-
reduce过少,单节点压力大容易oom
系统分配reduce方式,基于以下两个参数设置
-
hive.exec.reducers.bytes.per.reducer 每个reduce处理的数据量,默认1G
-
hive.exec.reducers.max 最大reduce数,默认999
-
set mapred.reduce.tasks直接设置reduce个数
系统也会依据桶的数量分配reduce数,使得数据能够存入分桶文件中
只有开启一个reduce的情况
-
分组函数没有设置分区
select pt,count(1) from t_data where pt = ‘2012-07’ [group by pt];
-
使用 order by 排序
order by 会导致整表排序,只能由一个reduce处理
sorted by则只是对每个reduce结果排序
行式存储与列式存储
行式数据库:块内存储多行数据,一行中有多个不同的数据类型,查询时需要依次进行解析全表数据
列式数据库:块内存列的数据,数据按列进行压缩,由于列属性相同,压缩与解析的格式相同,数据按列处理(列查询效率高)
1,admin,123456 2,zhangsan,123456 3,lisi,123456 //行式压缩 1,admin,123456;2,zhangsan,123456;3,lisi,123456 //列式压缩 1,2 admin,zhangsan 123456,123456 3,lisi,123456 select id ,name from table; 适用于列存储,使用较多 select * from table where id = 2; 适用于行存储,大数据中使用较少
其他优化
-
根据查询高频词创建分区表,减少查询时数据扫描的范围
-
减少使用去重distinct,避免产生数据倾斜
-
JVM重用可以使得JVM实例在同一个job中时候使用N次,减少内存开销
-