本人工作经验5年,2019年10月没准备找过一段时间工作,最终开的薪资都不愿意给,最后有一家工资还可以不过最后要驻场(外包嘛),后面没去就做了份兼职。为了年后找工作就打算年前试水,面试两家一个中小型公司100~500人的A公司,一家大厂几千人的公司B公司。A公司两轮技术面试通过HR面试通过最后老总面试也过了发offer。B公司电商项目3轮技术面试一轮hr面试也过了,准备发offer,问了一下加班情况,Q1 Q2加班会比较多、可能经常9 10点的样子吧,由于本人从家过去要一个小时,长期这样会比较累,所以拒绝了。
A公司面试题:
1.lambda表达式常用的方法有哪些?
sort() filter() map() flatmap() collection() collectionAndThen() collect() orElse() 等
2.feign的日志级别(非log)。
NONE:不打印日志
BASIC:表示只输出请求方法的 URL 和响应的状态码以及执行的时间
HEADERS 将 BASIC 信息和请求头信息输出。
FULL 会输出全部完整的请求信息。
3.4G内存怎么分配年轻代 老年代的内存?
4.分布式事务消息方案。
5.查看日志用什么命令?
tailf -n 500 logfile 查看最后500行日志
查询指定时间范围的日志 sed -n '/yyyy-MM-dd HH:mm:ss/,/yyyy-MM-dd HH:mm:ss/p' logfile
统计wc -l 或者直接用elk
6.线上处理过jvm的问题吗?
7.Spring Aop原理。
Jdk动态代理:针对接口
cglib动态代理:直接作用于类
8.springcloud用了哪些组件。
eureka:注册中心 nacos zookeeper consul也可以
zuul:网关,新版本可以考虑gateway
9.越权怎么处理的。比如A用户登录了,把参数值改了就可以访问B用户的权限了。
10.csrf攻击怎样防止?
11.java agent了解多少?
12.分布式链路追踪怎么做的?
zipkin seluth
13.用过哪些设计模式?
适配器模式:
工厂模式:
策略模式:
构建者模式:
可以看一下: http://c.biancheng.net/design_pattern/
14.service Mesh了解吗?
其余问题都不难回答,有点记不起来了。
B公司面试题:
1.jvm处理过的线上问题说一下?
2.springcloud用过哪些组件?
eureka:注册中心(已不维护,可以考虑阿里巴巴nacos、zookeeper、consul)
feign:模块之间相互通信
ribbon:负载均衡
hystrix:熔断,限流(已不维护,可以考虑sentinel或者resilience4j)
zuul:网关(已不维护,可以考虑gateway)
3.最有成就感的项目及负责的内容?
4.mysql索引结构?
5.mysql创建索引和使用索引的注意事项?
创建:
经常会进行作为条件查询的字段,排序的字段建议加索引;
对于表中业务唯一的字段或者组合字段建立唯一索引;
建组合索引要考虑业务场景,注意顺序;
属性值只有固定几个的不要建索引;
建立索引的字段最好设置非空;
使用:
字符串必须加索引,否则不走索引;
组合索引,要注意范围查询,以免索引失效;
索引字段不要使用函数,否则索引失效
加了索引的字段最好不要把值设置NULL
组合索引要遵循最左前缀原则
模糊查询注意最前面不要使用%,如果属性加了索引,索引会失效
程序中的sql最好在数据库工具中使用explain desc检测一下,尽可能减少不走索引的情况
6.springmvc流程?
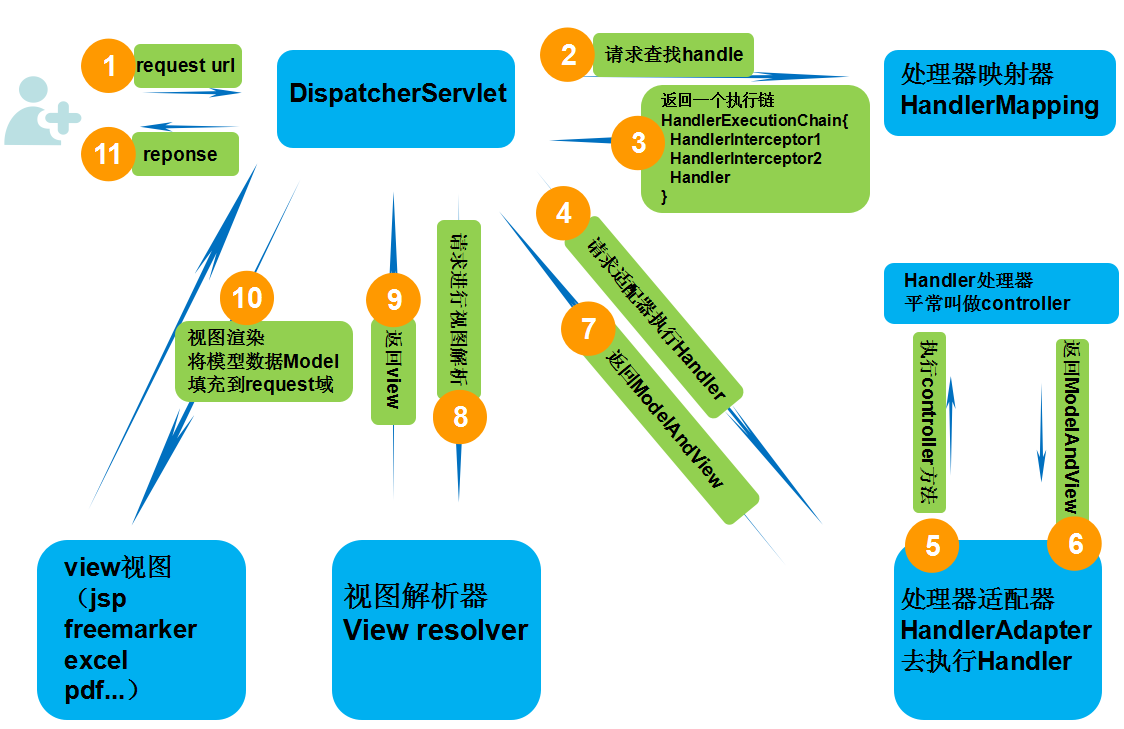
具体步骤:
第一步:发起请求到前端控制器(DispatcherServlet)
第二步:前端控制器请求HandlerMapping查找 Handler (可以根据xml配置、注解进行查找)
第三步:处理器映射器HandlerMapping向前端控制器返回Handler,HandlerMapping会把请求映射为HandlerExecutionChain对象(包含一个Handler处理器(页面控制器)对象,多个HandlerInterceptor拦截器对象),通过这种策略模式,很容易添加新的映射策略
第四步:前端控制器调用处理器适配器去执行Handler
第五步:处理器适配器HandlerAdapter将会根据适配的结果去执行Handler
第六步:Handler执行完成给适配器返回ModelAndView
第七步:处理器适配器向前端控制器返回ModelAndView (ModelAndView是springmvc框架的一个底层对象,包括 Model和view)
第八步:前端控制器请求视图解析器去进行视图解析 (根据逻辑视图名解析成真正的视图(jsp)),通过这种策略很容易更换其他视图技术,只需要更改视图解析器即可
第九步:视图解析器向前端控制器返回View
第十步:前端控制器进行视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充到request域)
第十一步:前端控制器向用户响应结果
来源:https://www.cnblogs.com/leskang/p/6101368.html
7.redis有哪些淘汰策略?
volatile-lru
allKeys-lru
volatile-ttl
volatile-random
allKeys-random
volatile-lfu
allKeys-lfu
noeviction 不淘汰策略,超过最大内存,返回错误信息
8.分布式事务解决方案?
rocketMQ保证最终一致
lcn、seata等事务框架
参考:http://springcloud.cn/view/374
9.线程池的创建使用哪种方式?
根据阿里开发手册,建议手动使用new ThreadPoolExecutor()创建,当然如果系统不是很大用Executors工厂类也是可以的
10.ThreadPoolExcutor的各个参数解释一下?
ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize:在线程池空闲时也保持的线程数,除非被set方法重置了
maximumPoolSize:线程池允许的最多线程数,可以通过set方法改变
keepAliveTime:线程数超过corePoolSize时,这是超出空闲线程的最大时间
将等待新的任务才终止
unit:时间单位
workQueue:工作队列
threadFactory:创建线程 参考Executors.DefaultThreadFactory
handler:AbortPolicy(默认策略) DiscardPolicy DiscardOldestPolicy CallerRunsPolicy
参考:ThreadPoolExecutor类的注释
11.常用哪些队列?
LinkedBlockingQueue:默认容量Integer.MAX_VALUE
DelayQueue:延迟队列,用于调度线程池
ArrayBlockingQueue:基于数组的有界队列,顺序FIFO,必须指定容量
LinkedBlockingDeque:基于链表的双端队列
SynchronousQueue:同步队列,里面没有容量
12.怎样在不加锁的情况下在一个队列中插入和查询数据保证准确性。
这个得考虑使用类似乐观锁的字段去标识了
13.写一个100%死锁的例子。
A类的方法调用B类的同步方法,B类中的同步方法调用A类中的同步方法,但这种并不一定保证100%死锁,后面找个例子
14.怎样防止超卖?
这里要考虑使用redis的decrby的原子操作 ,当数量减到负数时直接返回买完了,另外如果有取消订单的要incrby添加回去
15.怎样扣减库存?
同14
16.springboot-starter自定义步骤。(简历写了看过部分springboot源码)
- a.创建 Starter 项目;
-
b.项目创建完后定义 Starter 需要的配置(Properties)类,比如数据-库的连接信息;
-
c.编写自动配置类,自动配置类就是获取配置,根据配置来自动装配 Bean;
-
d.编写 spring.factories 文件加载自动配置类,Spring 启动的时候会扫描 spring.factories 文件,指定文件中配置的类;
-
e.编写配置提示文件 spring-configuration-metadata.json(不是必须的),在添加配置的时候,我们想要知道具体的配置项是什么作用,可以通过编写提示文件来提示;
-
f.最后就是使用,在项目中引入自定义 Starter 的 Maven 依赖,增加配置值后即可使用。
你可以参考mybatis-spring-boot-starter的定义,我自己写的简单的demo:
17.springboot怎样加载tomcat。(简历写了看过springboot加载tomcat的流程)
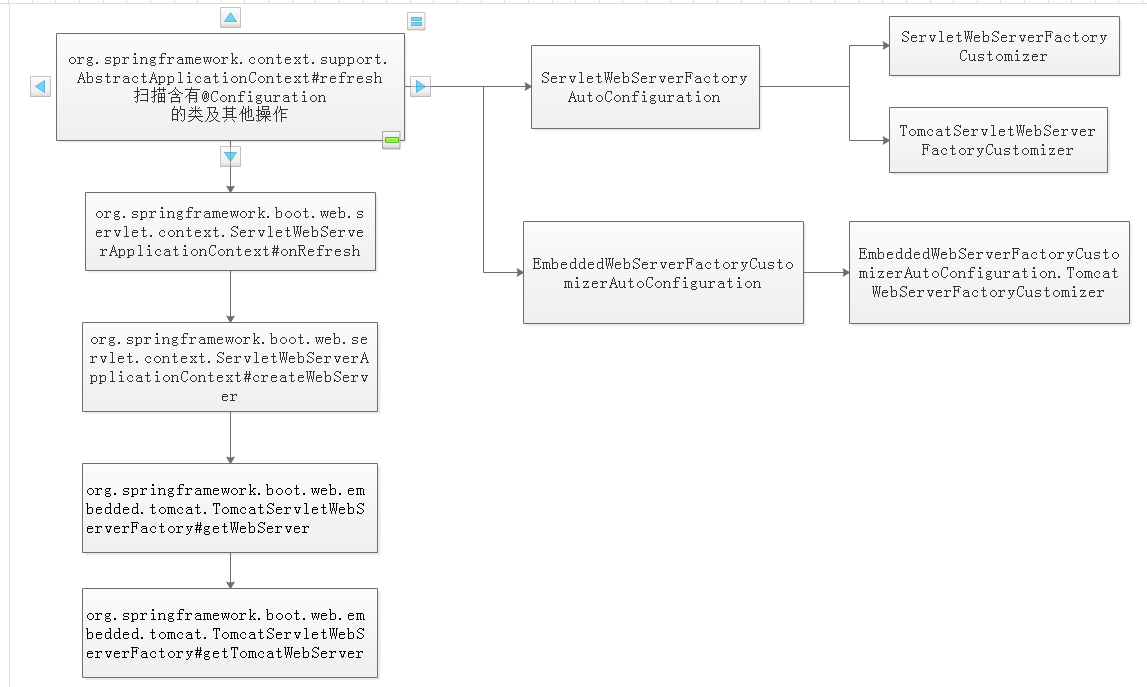
主要是spring-boot-starter-web中有tomcat相关的加载,@Configuration注解过了,如果你同时加入jetty其他服务器的jar包会报错,自己看源码
18.让你设计一个mybatis类似的框架你怎样设计?
19.mybatis的处理数据的流程。(简历写了看过mybatis源码)
20.redis缓存穿透、击穿、雪崩是什么,解决方案是什么?
缓存穿透:查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
解决方案:有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存雪崩:在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件
缓存击穿:对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案:尽量少的线程构建缓存(甚至是一个) + 数据一致性 + 较少的潜在危险
参考:https://www.cnblogs.com/raichen/p/7750165.html
https://juejin.im/post/5dbef8306fb9a0203f6fa3e2
21.zuul1、zuul2有什么区别?跟gateway比有什么区别?
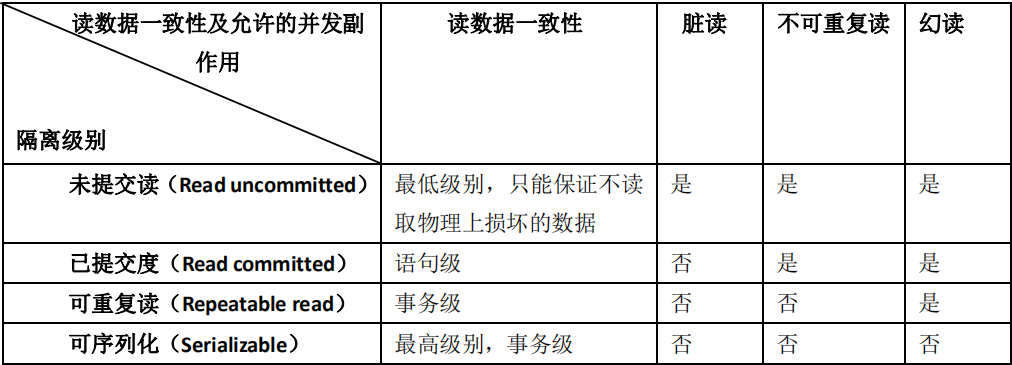
22.mysql的隔离级别。
23.mysql分库分表怎么设计的,用过哪些分库分表中间件?
mycat
atlas
sharding-sphere
24.springAop说一下原理。
Spring AOP面向切面变成主要是基于动态代理实现,一个是jdk的动态代理,基于接口,一个是cglib动态代理,可以作用到类级别
25.ConcurrentHashMap的结构,怎样保证线程安全?
jdk1.7 及之前采用分段锁segment+链表+数组实现,锁使用Lock
jdk1.8开始采用了node+链表+数组实现,其中锁使用的synchronize,性能提升了,主要是synchronize后面的性能提升了
26. class文件加载流程及自定义加载器的实现。

自定义类加载器主要实现ClassLoader
建议看看深入理解Java虚拟机这本书
27.怎样设计一个秒杀系统?
28.在一个直播系统中,主播按完按钮之后,有500w个100 50 20 0的钻石会被用户抽到,随着数量的减少需要调整概率保证公平性,尽量让用户都能抢到,设计一个高可用、可扩展的系统怎么设计?
29.mybatis分页怎么做的,有用哪些插件,是否使用过mybatis的拦截器,你在什么场景下用的拦截器?
30.hystrix的原理。
31.常用的垃圾收集器有哪些?
serial收集器:新生代收集器,单线程
parnew收集器:新生代收集器,serial的多线程版本
parallel scavenge:跟parnew差不多,主要增加吞吐量
serial old:老年代收集器,单线程
parallel old:parallel scavenge的老年代版本
cms:
g1(java8及之后)
zgc(java11之后)
32.知道CAS的原理吗?ABA的问题知道吗,说一下?
CAS(V,A,B) 1:V表示内存中的地址 2:A表示预期值 3:B表示要修改的新值
CAS的原理就是预期值A与内存中的值相比较,如果相同则将内存中的值改变成新值B。这样比较有两类:
第一类:如果操作的是基本变量,则比较的是 值 是否相等。
第二类:如果操作的是对象的引用,则比较的是对象在 内存的地址 是否相等。
参考: https://blog.csdn.net/u011277123/article/details/90699619
33.https与http有什么区别?
34.mq消息丢失和重复消息怎么解决的?
面试题收集了本人看过的比较好的博客和最近整理的面试题及部分答案。欢迎有兴趣的朋友一起整理,方便自己和找工作的朋友。欢迎加群:513650703共同探讨问题。