1、枚举:枚举本质上是一个类,而且是一个特殊类,其内部成员对应的都是本身的一个实例,这就省去了外部实例化的过程,而且也不允许外部进行实例化,因为枚举的构造函数必须为私有的,可以重写,但是访问级别必须为private,就是为了限制外部实例化,常用方法有valueOf("")把字符串转为枚举的静态方法等,如下:


1 public class TestInnerClass { 2 3 @Test 4 public void func() 5 { 6 MyEnum mon = MyEnum.valueOf("Mon");//把字符串直接转为枚举对象的静态方法valueOf 7 //MyEnum mon2 = MyEnum.Mon; //直接调用成员变量也可以获得具体的枚举类实例,默认调用的是无参构造方法 8 9 } 10 11 public enum MyEnum 12 { 13 Mon,Sun(),//成员变量必须写在枚举类的构造方法前面,成员变量默认为静态的,类加载的时候就会把所有成员变量都实例化,Sun成员变量默认写法就是Sun(),一般省去无参() 14 Fri(5);//如果就像实例化时调用其他构造方法,那么必须自己显示指定,如Fri(5) 15 private MyEnum(){//枚举类的构造方法必须为private 16 System.out.println("first....."); 17 } 18 private MyEnum(int i) 19 { 20 System.out.println("second....."); 21 } 22 } 23 }
2、反射:
一份代码编译后会生成.class结尾的二进制文件,这份二进制文件就是字节码文件,当程序运行时会把这份calss文件加载到JVM中,字节码只有一份,JVM会依据此字节码进行实例化对象,在JVM中获取字节码的方式有:类名.class、实例名.getClass(),Class.forName("字节码全路径类名"),Java中预置了8大基本类型字节码以及一个void,是原始基本数据类型,8大基本类型是int,boolean,double等小写形式,其他对象都不是原始数据类型,其和包装类型Integer等属于不同字节码,也就是对应不同的类,但是保证类型中持有对应的基本数据类型属性,属性名为TYPE;数组类型的字节码和普通类型字节码不一样,如String[].class ,区别就是不同类对应不同字节码,如下:
System.out.println(Integer.class == int.class);//false System.out.println(Integer.TYPE == int.class);//true System.out.println(int.class.isPrimitive()); //true,isPrimitive查看是否为原始的基本数据类型 System.out.println(Integer.class.isPrimitive());//false,只有8大基本数据类型,Integer等不是原始基本数据类型
反射获取构造方法:构造函数区分就是通过参数类型和个数来区分的,所以可以通过如下方法获取指定构造函数
Constructor<Jerry> constructor = Jerry.class.getConstructor(String.class);//指定的构造方法参数类型
Jerry newInstance = constructor.newInstance("jerry");//通过获取的构造方法实例化对象的时候必须传入对应类型的参数
//简便方法,直接通过Class对象实例化对象,其内部其实还是调用构造器实例化,而且只是调用无参构造方法,如:
Jerry jerry = Jerry.class.newInstance(); //通过这种方式调用必须保证有无参构造方法,不然会报错
反射操作Field字段,默认只能操作public的字段,如果想操作private的字段,分两步,先使用getDeclaredField方法获取私有字段,然后暴力改变访问级别setAccessible
Jerry jerry = Jerry.class.newInstance();
jerry.setName("jerry");
Field field = Jerry.class.getField("name");//默认只能访问public的字段
Object object = field.get(jerry);//字节码上的字段是没有值的,得依赖具体的实例对象初始化值之后才可以取到值,所以得传入实例对象
System.out.println(object);
访问私有字段:
Jerry jerry = Jerry.class.newInstance();
jerry.setAge(100);
Field field = Jerry.class.getDeclaredField("age");//调用私有的成员变量得用getDeclaredField方法
field.setAccessible(true);//暴力设置访问级别,直接强行访问
System.out.println(field.get(jerry));
获取字段的字节码类型:
Field field = Jerry.class.getDeclaredField("age");//调用私有的成员变量得用getDeclaredField方法
System.out.println(field.getType()==Integer.class);//getType()可以得到字段的字节码类型
给字段设置值:
Jerry jerry = Jerry.class.newInstance();
jerry.setAge(100);
Field field = Jerry.class.getDeclaredField("age");//调用私有的成员变量得用getDeclaredField方法
field.setAccessible(true);//暴力设置访问级别,直接强行访问
System.out.println(field.get(jerry));//设值之前
field.set(jerry, 101);//设值
System.out.println(field.get(jerry));//设值之后
Method方法反射调用:
Jerry jerry = Jerry.class.newInstance();
Method method = Jerry.class.getMethod("say", String.class);//获取字节码上的方法,传入方法名,和方法需要参数类型
String resVal = (String) method.invoke(jerry, "hello world ");//方法调用也得依赖与实例对象,字节码上的方法得关联具体实例方法调用才有具体值和意义,传入参数为实例对象,参数值
System.out.println(resVal);
反射如何调用静态方法呢?只需要将invoke方法的第一个参数设为null即可!
Class<?> threadClazz = Class.forName("java.lang.Math");
Method method = threadClazz.getMethod("abs", long.class);
System.out.println(method.invoke(null, -10000l));
反射调用方法时,由于JDK的可变参数是1.5才推出来的,先前传递多个参数都是采用数组形式传递,这样1.5为了兼容之前版本,还支持传递数组作为一组参数,但是如果整合调用的方法本身就是需要一个数组类型的参数,那么这时JDK运行时还是会把参数数组拆开,这样就会造成参数类型不匹配,这时如果需要传递数组类型参数,得在数组外面再套一层Object数组,如下:

通过当前类 得到父类的字节码,调用getSuperclass:
Jerry jerry = Jerry.class.newInstance(); System.out.println(jerry.getClass().getSuperclass().getName());//getSuperclass得到父类字节码
反射操作数组,框架中经常有用到
1 public static void main(String[] args) throws Exception, SecurityException { 2 3 Object obj="jerry"; 4 reflectObj(obj);//传的不是数组,直接打印 jerry 5 Object obj2=new String[]{"a","b","c"}; 6 reflectObj(obj2);//传的是数组,循环打印结果 7 } 8 9 private static void reflectObj(Object obj) { 10 Class clazz = obj.getClass(); 11 if(clazz.isArray())//如果传过来的对象是数组 12 { 13 int length = Array.getLength(obj);//Array是属于java.lang.reflect.Array包下的操作数组的反射类,getLength反射获取到数组长度 14 for (int i = 0; i < length; i++) { 15 System.out.println(Array.get(obj, i));//反射打印数组的各个索引下的数据 16 } 17 } 18 else 19 { 20 System.out.println(obj); 21 } 22 23 }
3、hashCode()和eqauls()的作用,一般这两个方法无需自己手写,在eclipse中按快捷键直接选择生成就行,如:
1 @Override 2 public int hashCode() { 3 final int prime = 31; 4 int result = 1; 5 result = prime * result + ((age == null) ? 0 : age.hashCode()); 6 result = prime * result + ((name == null) ? 0 : name.hashCode()); 7 return result; 8 } 9 10 @Override 11 public boolean equals(Object obj) { 12 if (this == obj) 13 return true; 14 if (obj == null) 15 return false; 16 if (getClass() != obj.getClass()) 17 return false; 18 Jerry other = (Jerry) obj; 19 if (age == null) { 20 if (other.age != null) 21 return false; 22 } else if (!age.equals(other.age)) 23 return false; 24 if (name == null) { 25 if (other.name != null) 26 return false; 27 } else if (!name.equals(other.name)) 28 return false; 29 return true; 30 }
作用是:这两个方法都是搭配使用,作用主要是用来据此判断要存放对象在内存中地址值的哈希码,根据哈希码可以快速找到具体位置,这个是HashSet以及HashMap集合查询效率高的原因,hashCode()判断存放地址,equals判断存放地址上的对象和当前对象是否是同一个对象,如果是同一个就过滤掉,有了hashCode就可以快速定位到具体地址,找到该元素,可以提高查询速度,不然得一个个遍历地址查找,然后再用equals判断两对象是否相等,要想是hashCode生效,必须数据是存放在实现了hashCode的集合中,这样才能与hashCode集合算出的内存地址一一对应上,才能精确存放,不然普通集合如ArrayList根本没实现哈希算法,你把要存放的对象算出个hashCode有个毛用,算出来也不知道存哪里,所以得配合具体集合才能生效,所以在存放集合后,不要修改生成hashCode的字段值,不然会造成hashCode变化,这样就会找不到先前存放进集合的对象了,就好像人还在酒店先前房间,但是这时给你的门牌号变了,你根据变化后的门牌号再去找先前的房间肯定找不到,如下操作就会导致出现这种结果:


当hashCode算出的值相同,但是对象equals比较却是两个不同对象,这时就是hashCode值冲突,会造成两个不同对象存放在同一个位置,这时后来的对象与先前对象组成链表,HashMap内部采用的就是这种单链表形式避免hashCode冲突的,其实还有另一张形式避免hashCode冲突,就是一看这个位置已经被占了,此时就算hashCode相同,也让其再去找槽位进行存放
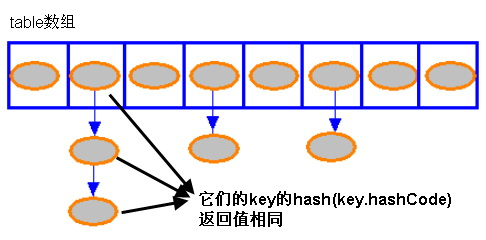
Hashmap里面的bucket出现了单链表的形式,散列表要解决的一个问题就是散列值的冲突问题,通常是两种方法:链表法和开放地址法。链表法就是将相同hash值的对象组织成一个链表放在hash值对应的槽位;开放地址法是通过一个探测算法,当某个槽位已经被占据的情况下继续查找下一个可以使用的槽位。java.util.HashMap采用的链表法的方式,链表是单向链表。
HashMap里面没有出现hash冲突时,没有形成单链表时,hashmap查找元素很快,get()方法能够直接定位到元素,但是出现单链表后,单个bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
当创建 HashMap 时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。
4、克隆
java里面的克隆分浅克隆和深克隆,浅克隆就是引用类型只复制一个引用拷贝,任何一方修改都会导致引用对象发生改变,深克隆就是引用类型各自独立,是持有另一份引用对象,要实现浅克隆只要实现Cloneable接口,重写clone方法就行,jvm会调用本地C代码实现拷贝,调用的时候直接Sheep sheep2 = sheep1.clone();就行,如果想实现深克隆那么简单的方法可以仍然实现Cloneable接口,重写clone方法的时候在方法内部自己new一份新的引用对象给拷贝对象,但这种方式如果有多个引用对象就会很繁琐,所以还有一种快捷的方式实现深克隆,就是采用对象序列化和反序列化,只要对象实现Serializable接口就行,无需实现Cloneable接口,深拷贝序列化代码如下:
1 public static void main(String[] args) throws Exception { 2 Sheep sheep1 = new Sheep("a"); 3 4 DateFormat dateFormat1 = new SimpleDateFormat("yyyy-MM-dd"); 5 Date myDate1 = dateFormat1.parse("2009-06-01"); 6 sheep1.setBirthday(myDate1); 7 8 System.out.println(sheep1); 9 System.out.println("================="); 10 11 ByteArrayOutputStream bos=new ByteArrayOutputStream(); 12 ObjectOutputStream oos=new ObjectOutputStream(bos);//先反序列化对象到字节数组流中 13 oos.writeObject(sheep1); 14 byte[] outArray = bos.toByteArray(); 15 16 17 ByteArrayInputStream bis=new ByteArrayInputStream(outArray); 18 ObjectInputStream ois=new ObjectInputStream(bis); //从字节数组流中读取到对象 19 Sheep sheep2=(Sheep) ois.readObject(); //拷贝了一份新对象 20 21 22 myDate1.setTime(dateFormat1.parse("2019-06-01").getTime()); 23 sheep1.setBirthday(myDate1);//这时就算修改先前对象的引用对象值,新对象也不会发生变化 24 25 System.out.println(sheep2); 26 27 }
5、读取属性文件:
属性文件是以properties结尾的文本文件,其是一个键值对形式,只不过是特殊的键值对,键和值都只能是字符串,读取属性文件可以通过如下方式实现:
方式一(不推荐):
1 Properties properties=new Properties(); 2 FileInputStream inStream=new FileInputStream("aa.properties"); 3 //这种写法有个弊端就是相对工程路径,需要放置在与工程目录同级目录下才能找到,不然就会报错,或者使用绝对路径,所以实际项目中不这么干 4 properties.load(inStream); 5 inStream.close(); 6 String myname = properties.getProperty("myname"); 7 System.out.println(myname);
方式二,使用类加载器(推荐),但是仅限于读取,写操作不支持,不过配置文件一般都是用于读取:
1 //InputStream inputStream = MyReflect.class.getClassLoader().getResourceAsStream("com/cb/test/myReflect/aa.properties");//从编译后的classes文件夹下查找 2 InputStream inputStream = MyReflect.class.getResourceAsStream("aa.properties");//getResourceAsStream是一个简便方法内部仍然调用的是getClassLoader,但是其使用的是相对当前类的路径加载,所以不需要从calsses下开始写路径 3 //如果想从classes下开始加载,那么可以写完整项目路径,从根目录下找/com/cb/test/myReflect/aa.properties,前面加/ 4 Properties properties=new Properties(); 5 properties.load(inputStream); 6 inputStream.close(); 7 String myname = properties.getProperty("myname"); 8 System.out.println(myname);
6、内省
内省也就是反射的简化版,主要是用来操作javabean的属性和方法的,一般属性对应有getXxx和setXxx方法,其命名规则是把字段名首字母大写加上get和set,通过内省机制老操作javabean的方式主要有如下几种:

1 public static void main(String[] args) throws Exception { 2 3 Jerry jerry=new Jerry("tom"); 4 String propertyName="name"; 5 PropertyDescriptor propertyDescriptor=new PropertyDescriptor(propertyName, Jerry.class);//PropertyDescriptor方法参数:操作哪个属性,操作哪个类 6 //通过内省操作属性,不需要传入完整的getXxx()方法名,达到简便操作效果 7 Method readMethod = propertyDescriptor.getReadMethod();//得到getXxx()方法 8 String resVal = (String) readMethod.invoke(jerry);//调用get方法获取属性值 9 System.out.println(resVal); 10 11 Method writeMethod = propertyDescriptor.getWriteMethod();//得到setXxx()方法 12 writeMethod.invoke(jerry, "jerry");//set方法无返回值 13 14 System.out.println(jerry.getName());//再调用一次set改变后的值 15 }
一般内省机制,平常很少用得到,基本都是直接调用Javabean的get,set方法来操作属性值,内省机制主要在框架中用的多,因为框架没法知道具体的Javabean名,只能通过内省来操作所有Javabean,比较常用的第三方工具有BeanUtils,复杂点操作Javabean的内省方式可以通过获取整个Javabean信息然后进行遍历,Introspector上的静态方法getBeanInfo可以获取到beanInfo信息,不过不用自己用原生方式操作Javabean内省,一般借助第三方工具,如beanUtils,可以用这个工具实现两个对象的属性值拷贝,常用的是把一个对象属性值拷贝到新对象中操作新对象,而不动源对象
1 public static void main(String[] args) throws Exception { 2 //这种遍历的方式,就完全只适合框架开发了,会遍历出所有方法 3 Jerry jerry=new Jerry("tom"); 4 BeanInfo beanInfo = Introspector.getBeanInfo(Jerry.class); 5 MethodDescriptor[] methodDescriptors = beanInfo.getMethodDescriptors();//只能得到所有属性方法,然后遍历 6 for (MethodDescriptor methodDescriptor : methodDescriptors) {//会遍历出所有方法,包括基类的所有方法和属性,如tostring,hashCode等方法也会遍历出来,所以得具体过滤 7 if(methodDescriptor.getName().equals("getName"))//过滤出具体方法 8 { 9 Method method = methodDescriptor.getMethod(); 10 Object resval = method.invoke(jerry); 11 System.out.println(resval); 12 } 13 } 14 }
7、注解
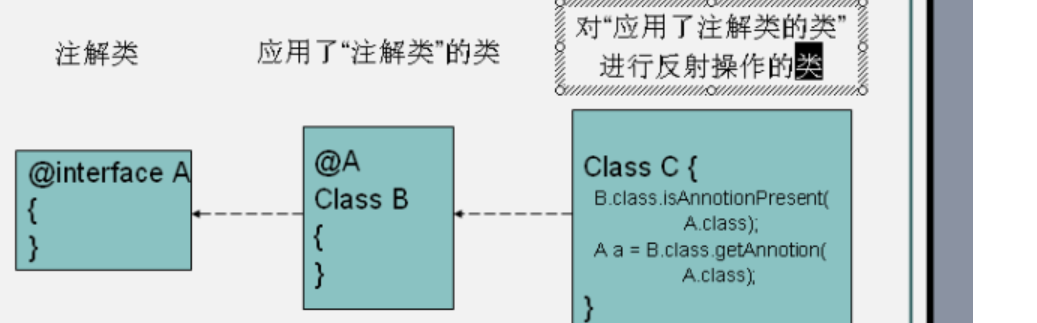
注解其实也就是一种特殊的类,自己定义注解和定义普通接口差不多,只不过需要加上@,JDK中默认提供了一些常用注解,如@SuppressWarnings,@Override等,注解和xml配置的效果一样,其原理也就是通过注解能拿到和在xml中配置的元信息一样的信息,这些信息被定义在注解类中,在这些注解类中定义有各种属性,在使用时需要为属性赋值,通过反射解析注解中的属性值,拿到元数据信息,然后就可以实现自己的业务逻辑,这个spring,struts等既可以通过xml配置,也可以通过注解实现,其原理就是这样的,反正都是拿到元数据信息,最终根据这些元数据信息去new对象或做其他业务操作,注解和xml只是传递这些元数据信息的不同方式而已,使用步骤图解如下:先定义注解,再使用注解,最后框架反射解析注解
注解的生命周期可以由自己通过JDK的注解指定,默认的生命周期范围是一个枚举值,其有3种取值范围,其指定也是通过JDK的一种注解@Retention()来指定,其取值范围有3个,RetentionPolicy.SOURCE,RetentionPolicy.CLASS,RetentionPolicy.RUNTIME,分别为RetentionPolicy.SOURCE阶段只停留在源文件上,javac编译时会会用到,如@override重写检查,会在编译时进行检查,检查不通过会编译报错,检查通过后生成的class文件中会把此注解擦除;RetentionPolicy.CLASS会把注解保留到编译后的class中,会在类加载器加载前进行检查,检查通过后不会放入JVM字节码文件中,会在JVM字节码中擦除此注解;RetentionPolicy.RUNTIME会保留到JVM字节码文件中,会在程序调用时进行注解检查,此时如拿到一下元数据配置信息,可以在此步获取,这是最长的一步生命周期。具体自定义的注解需要在哪个阶段发生作用,就得定义不同生命周期范围的注解。
注解的开发步骤如下:
1)、新建一个注解类:在eclipse中可以在新建中选择other选择annotation进行新建,生成的关键字的@interface,注解属性返回值支持8大基本类型,calss类型,枚举类型,其他不支持
2)、使用注解
3)、框架反射解析注解
1 @Target({ElementType.METHOD,ElementType.TYPE}) //@Target注解说明JerryAnnotation这个自定义注解使用范围,是使用在类上,还是使用在方法上,其内部接收一个ElementType的枚举 2 @Retention(RetentionPolicy.RUNTIME)//此步说明把注解留到运行时,不然默认会编译后进行注解擦除 3 public @interface JerryAnnotation { 4 //在注解接口中定义方法,也叫属性,可以在注解使用中传递值用,类似与Javabean中的get/set方法的合体 5 String color() default "blue" ; //定义默认属性值,如果使用时没有输入,那么就使用默认值 6 String value(); //如果使用时,注解中只用到一个属性,而此属性正好是value,那么可以省去value前缀,直接写属性值,但是有多个属性时,不能省去value名 7 int[] arrInt(); //定义一个数组类型属性,使用时用{}包裹数组值 8 Lamp lamp(); //定义枚举类型属性 9 10 } 11 //========================================= 12 //通过注解传递元数据信息 13 @JerryAnnotation(value="tom",arrInt={1,2,3},lamp=Lamp.GREEN) 14 public class AnnotationUse { 15 //此步是模拟使用自定义好的注解类,如spring的Contrller中使用的注解 16 } 17 //========================================= 18 //此步模拟框架最终运行业务类是,根据判断是否加有注解来获取相应元数据信息进行下一步处理 19 public static void main(String[] args) { 20 21 //反射检查业务类上是否有@JerryAnnotation这个注解 22 if(AnnotationUse.class.isAnnotationPresent(JerryAnnotation.class))//走到此步的注解,其生命周期是runtime级别的 23 { 24 //如果有@JerryAnnotation这个注解,进入if内部,进行注解中元数据获取 25 JerryAnnotation jerryAnnotation = AnnotationUse.class.getAnnotation(JerryAnnotation.class);//从使用注解的类上反射获取到具体注解的实例 26 String color = jerryAnnotation.color();//从注解中获取到元数据信息 27 String value = jerryAnnotation.value(); //获取value属性值 28 int[] arrInt = jerryAnnotation.arrInt();//获取数组属性 29 Lamp lamp = jerryAnnotation.lamp();//获取枚举属性 30 31 } 32 else 33 { 34 //读取xml配置信息 35 } 36 37 }
8、泛型:
泛型主要作用就是在编译期进行类型检查,方便集合和类的操作,但是其泛型参数的生命周期也仅先于编译期,编译通过后生成的class文件中已经把泛型参数擦除,如果直接通过反射来操作泛型集合,那么由于calss文件中这时已经擦除泛型检查,而反射是操作jvm中的字节码,所以更加没有泛型约束了,可以插入任何Object类型值,如:
1 public static void main(String[] args) throws Exception{ 2 3 ArrayList<Integer> list=new ArrayList<Integer>(); 4 list.add(1);//整数泛型集合编译期检查只能存放整数 5 //list.add("abc"); //直接插入字符串abc,由于有泛型检查,插入不成功 6 list.getClass().getMethod("add", Object.class).invoke(list, "abc");//通过反射插入了字符串,越过了泛型检查,所以说泛型检查生命周期只在编译期 7 for (Object obj : list) { 8 System.out.println(obj);//打印出字符串 abc 9 } 10 11 }
泛型通配符?表示任意类型,比如如下方法func(ArrayList<Object>)泛型检查的参数类型为Object就只能接收Object的泛型参数类型
1 public static void main(String[] args) throws Exception{ 2 3 ArrayList<Integer> list=new ArrayList<Integer>(); 4 list.add(1);//整数泛型集合编译期检查只能存放整数 5 func(list); //传入参数类型报错 6 //实际传入的集合泛型参数为Integer,如果从类的继承来说Object可以接收Integer,但是这种关系不适合泛型参数,泛型参数只做检查, 7 //不关心他们的继承关系,既然不一样,那就不让存放 8 } 9 10 void func(ArrayList<Object> list)//方法定义的参数为Object 11 { 12 13 }
如果想要泛型参数接收任意类型,这时就得用通配符?,把方法修改一下就可以存入任意类型的泛型参数了
1 public static void main(String[] args) throws Exception{ 2 3 ArrayList<Integer> list=new ArrayList<Integer>(); 4 list.add(1);//整数泛型集合编译期检查只能存放整数 5 func(list); //传入成功 6 7 } 8 9 static void func(ArrayList<?> list)//方法定义的参数为Object 10 { 11 12 }
但是通配符的范围毕竟太宽泛了,连个具体范围也不知道,如果这时想知道接收参数的大致范围,那么这时得确定泛型参数的上限和下限,采用extends表示接收的参数是泛型参数限定类型或其子类,而super表示表示接收参数是限定类型或此类型的父类,既然是当前类型父类,那么通用父类Object类型也接收

下限例子:
1 public static void main(String[] args) throws Exception{ 2 3 ArrayList<Integer> list=new ArrayList<Integer>(); 4 list.add(1);//整数泛型集合编译期检查只能存放整数 5 func(list);// 6 //======================= 7 ArrayList<Object> list2=new ArrayList<Object>(); 8 list2.add("abc"); 9 func(list2); //由于Object是Integer的父类,故可以接收此中泛型类型的集合 10 } 11 12 static void func(ArrayList<? super Integer> list) //接收泛型参数集合为Integer或Integer的父类 13 { 14 //内部由于是一个泛型范围,所以无法确定外部传入的具体类型,故方法内部无法调用需要具体泛型类型的add等方法, 15 //但是可以操作与泛型参数类型无关的方法,如size(),for遍历等 16 }
上限例子:
1 public static void main(String[] args) throws Exception{ 2 3 ArrayList<Integer> list=new ArrayList<Integer>(); 4 list.add(1);// 5 func(list);// 6 //======================= 7 ArrayList<Double> list2=new ArrayList<Double>(); 8 list2.add(3.4d); 9 func(list2);//Double是Number的子类,故可以接收此类型集合 10 11 } 12 13 static void func(ArrayList<? extends Number> list) //接收泛型参数集合为Number或Number的子类 14 { 15 //集合类型参数只限定集合类型,至于集合内部的数据操作,只能在外部操作,内部无法具体兼容各种类型,但是可以调用非泛型方法 16 }
泛型方法必须在方法上加上<T>表示是一个泛型方法,泛型方法没办法限制参数类型,只能进行参数类型推断,所以不太好控,一般依靠使用者依法传入,或代码进行修正,但是类上的泛型,由于在new的时候就指定了泛型参数类型,所以起到了类型限制作用,但是泛型方法没法做到,但是可以加通配符限制范围
1 public class GenericClass<T> {//类上的泛型有限制作用 2 3 public T update(T t) 4 { 5 return t; //这不是泛型方法,只是根据类上泛型限制的具体参数类型,在类实例化时会进行确定 6 } 7 8 public <K,E> void add(K k,E e,T t) 9 { 10 //泛型方法,必须在方法上显示指定泛型方法参数类型,用尖括号包裹用到的泛型,但是其无法进行类型限制,只能进行类型推断 11 //如果参数上显示指定了尖括号,那么就代表泛型方法,就算其参数和类泛型参数重名,也并不受类上泛型限制,两者是重名的独立参数类型,叫啥名无所谓, 12 //不过为了不引起混淆,最好定义自己的名称,如果需要类上泛型限制,那就不要加到尖括号中,直接使用类上的就行 13 } 14 } 15 16 //===================================== 17 18 public static void main(String[] args) throws Exception{ 19 20 GenericClass<String> g=new GenericClass<String>();//实例化类是,指定了泛型参数类型为字符串 21 22 g.add("ccc","2","33");//这是泛型方法使用,由于没法进行参数类型限制, 23 //所以第一,第二两个参数只能根据传过来的具体参数类型来进行推断,第三个参数由于使用了类上的泛型参数限制,所以只能传字符串 24 g.update("1");//这个是普通方法调用,由于类上限制了,也只能传字符串 25 26 }
由于泛型类上泛型参数是在实例化时指定的,所以类中的静态方法不能使用泛型类上的泛型参数类型,因为加载时机不一样,所以只能自己指定泛型类型,改为泛型方法方式
9、类加载器:
java程序是通过把JDK加载仅虚拟机变成二进制字节码来运行,负责把JDK和目标项目jar加载仅虚拟机的就是类加载器,java虚拟机默认提供3个类加载器,其中有一个不是java程序写的,是底层C++写的一个二进制加载器,在JVM启动时就会运行此加载器,这就是BootStrap类加载器,其负责加载其他类加载器ExtClassLoader和AppClassLoader,3个类加载器组成父子继承树状结构,如下,java也提供了类自定义类加载器的接口,只需要自己实现ClassLoader抽象接口实现自定义加载器,挂载到JVM的类加载器上,如tomcat就实现了很多类加载器并挂载到JVM中,在tomcat启动时就会让jvm也加载其需要的jar包:
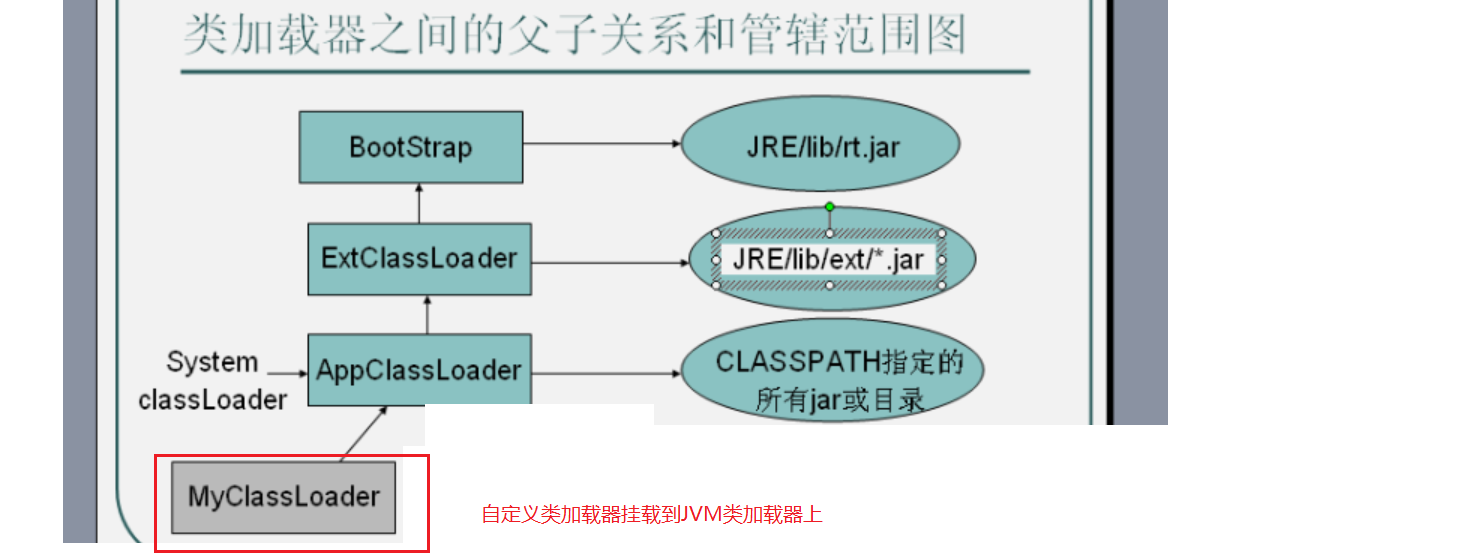
类加载器加载过程是先从当前线程类加载器出发进行加载,但是自己先不加载,而是继续往上寻找看是否有继承父类,如果有父类加载器,那么就让父类加载器去加载,依次往上委托父类加载,如果最顶层父类没有加载到,那么就用下一级类加载器加载,也就是最先干活的永远是祖宗,最后才是小辈,这种加载机制可以避免重复加载,而且对于JDK的加载也必须用顶层加载进来让下面人使用