工作中常用线程池的(通过Executors)创建方法分为以下四种:
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
查看源码可知,他们底层都是用ThreadPoolExecutor实现的:
ThreadPoolExecutor线程池-->继承AbstractExecutorService类-->实现ExecutorService接口-->继承Executor类
面试中也经常会问线程池的参数问题:
常用的五个参数: new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
corePoolSize:核心池的大小。创建线程池后,默认池中没有线程,有任务的时候才会去创建(当池中线程数目达到corePoolSize后会把到达的任务放到缓存队列中);
如果调用prestartAllCoreThreads()或者prestartCoreThread()方法,才会在没有任务的时候就预先创建corePoolSize个线程或者一个线程。
maximumPoolSize:线程池中最大线程数
keepAliveTime:线程没有执行任务时,最多保持多久会终止。默认当线程数量超过corePoolSize时,keepAliveTime起作用,如果调用了allowCoreThreadTimeOut(fasle)时,不管线程数量多少,keepAliveTime都会起作用
unit:keepAliveTime的单位(TimeUnit.DAYS/HOURS/MINUTES/SECONDS/MILLISECONDS/MICROSECONDS/NANOSECONDS)
workQueue:一个阻塞队列,用来存储等待执行的任务,常用的有LinkedBlockingQueue和SynchronousQueue,ArrayBlockingQueue和PriorityBlockingQueue使用较少
public class ThreadPoolDemo { public static class MyTask implements Runnable { public void run() { System.out.println(System.currentTimeMillis() + ":Thread ID:" + Thread.currentThread().getId()); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main(String[] args) { // 当线程池中线程的数目大于5时,便将任务放入任务缓存队列里面,当任务缓存队列满了之后,便创建新的线程。 // 如果上面程序中,将for循环中改成执行20个任务,就会抛出任务拒绝异常了。 // ThreadPoolExecutor exec = new ThreadPoolExecutor(5, 10, 200, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(5)); // ArrayBlockingQueue(有界阻塞队列--必须指定大小)和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue(无界阻塞队列)和Synchronous。线程池的排队策略与WorkQueue有关。 ThreadPoolExecutor exec = new ThreadPoolExecutor(5, 10, 200, TimeUnit.MILLISECONDS, new LinkedBlockingDeque<Runnable>()); // 创建一个可根据实际情况调整线程数量线程池 for (int i = 0; i < 15; i++) { MyTask myTask = new MyTask(); exec.submit(myTask); System.err.println("线程池中线程数目:" + exec.getPoolSize() + ",队列中等待执行的任务数:" + exec.getQueue().size() + ",已执行完别的任务数:" + exec.getCompletedTaskCount()); } exec.shutdown(); } }
使用new ArrayBlockingQueue<>(5),开启15个线程,输出如下:
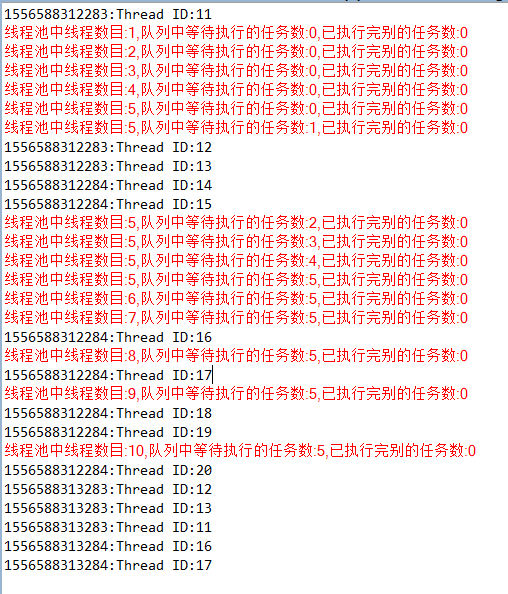
使用new ArrayBlockingQueue<>(5),开启20个线程,输出如下:
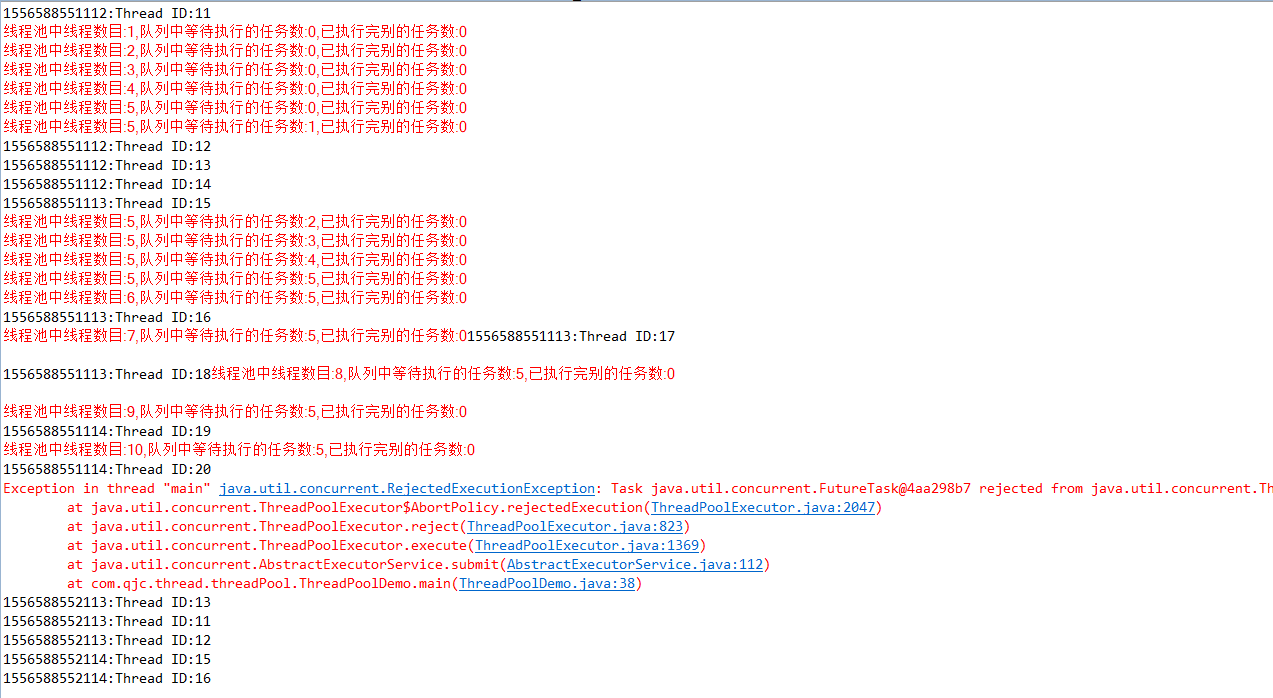
使用new LinkedBlockingDeque<>(),开启20个线程,输出如下:
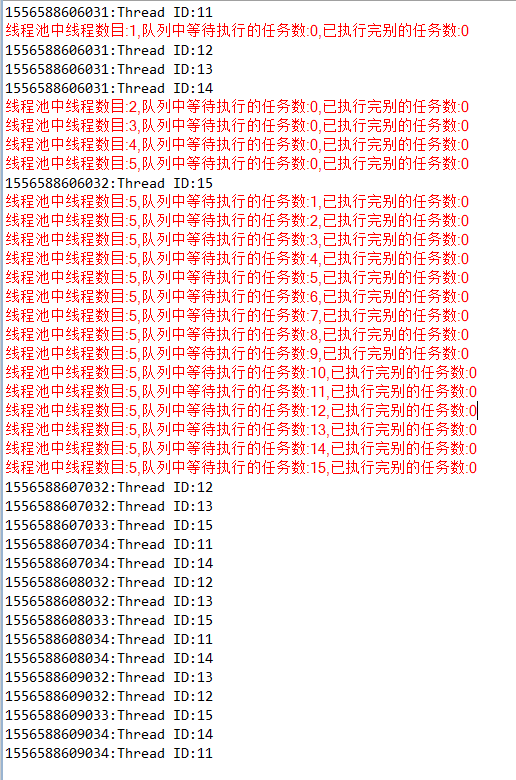
newFixedThreadPool和newCachedThreadPool有什么区别?
newFixedThreadPool该方法返回一个固定数量的线程池,当一个新任务提交时,线程池中若有空闲线程,则立即执行;
若没有,则新的任务会被暂存到一个任务队列中,待有空闲线程时再进行处理。
newCachedThreadPool该方法返回一个可根据实际情况调整线程数量的线程池。当一个新任务提交时,若有空闲的线程
可以复用则优先使用可服用的线程;若没有,则创建新的线程来处理任务。当任何一个线程处理完当前任务后都将返回到线程池中以备复用。
为什么不用newCachedThreadPool?
newCachedThreadPool的maximumPoolSize 最大值Integer.MAX_VALUE,一般来说机器都没有这么大内存供他使用,比如
在JDK1.5以后一个线程的堆栈大小为1M及-Xss1024k如果一下有10000个线程10000*1M=约10G的内存空间供给线程使用,这个是不现实的。