一.函数
日常生活中,要完成一件复杂的功能,我们总是习惯把“大功能”分解为多个“小功能”以实现。在编程的世界里,“功能”可称呼为“函数”,因此“函数”其实就是一段实现了某种功能的代码,并且可以供其它代码调用。
假设我们在编程过程中需要计算圆形的面积。如果我们不是用函数,每次需要计算原型面积的时候都需要这样
1 r1 = 12 2 r2 = 3.4 3 r3 = 3.1 4 s1 = 3.14 * r1 * r1 5 s2 = 3.14 * r2 * r2 6 s3 = 3.14 * r3 * r3
这样如果计算次数比较少还可以,如果需要计算的次数非常多,就比较麻烦了。另外如果我们要改动一下公式,比如π的值我们要改成3.141592657,有多少计算的地方就需要改多少遍,麻烦不说,还容易出错,遗漏等。函数就可以有效的解决以上的问题。
1、函数的定义及调用
定义一个函数要使用def关键字,依次写出函数名、括号、括号中的参数和冒号:,然后用缩进的代码块写函数体,函数体内可以调用return语句返回结果,以求原型面积为例我们可以这么定义一个函数
1 def circle_area(r): 2 return 3.14 * r *r
这样如果调用这个函数的时候我们只要这样,就可以了。
circle_area(5)
这样如果我们要改动π的值只需要改动一下函数就可以了。
另外函数名作为函数的名称,也可以像变量一样进行赋值操作、甚至作为参数进行传递,例如我们也可以把求圆形面积的函数赋值给f,然后通过f(4)这样去调用函数,意思是一样的。
1 f = circle_area 2 f(5)
2、函数的参数
1)位置参数
这是最常见的定义方式,一个函数可以定义任意个参数,每个参数间用逗号分割,例如:
1 def Fun(arg1, arg2): 2 print(arg1, arg2)
用这种方式定义的函数在调用的的时候也必须在函数名后的小括号里提供个数相等的值(实际参数),而且顺序必须相同,也就是说在这种调用中,形参和实参的个数必须一致,而且必须一一对应,也就是说第一个形参对应这第一个实参。例如:
>>> f = Fun
>>> f('abc',123)
#输出结果
abc 123
#如果形参和实参的数量不一致就会出现类似如下错误
>>> f('abc')
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: Fun() missing 1 required positional argument: 'arg2'
也可以通过如下方式传递参数,而不必考虑顺序问题,但数量无论如何必须一致。
>>> f(arg1="aa",arg2=123)
aa 123
>>> f(arg1="aa",arg=123)
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: Fun() got an unexpected keyword argument 'arg'
2)默认参数
我们可以给某个参数指定一个默认值,当调用得时候,如果没有指定那个参数,那个参数的值就等于默认值
>>> def Fun2(arg1,arg2='Jason'): ... print(arg1,arg2) ... >>> f = Fun2 >>> f(1) 1 Jason
>>> f('aa',456)
aa 456
3)可变参数
顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个、甚至于0个
>>> def Fun3(*args):
... print(args)
...
>>> Fun3('a',2,5,100)
('a', 2, 5, 100)
说明:可以看到我们传递了三个参数都被Python转化为元祖,保存到args中了,这样我们就可以通过索引对参数记性调用,或者通过for in进行遍历
4)关键字参数
可变参数在调用过程中会组装成元祖,元祖只能通过索引进行调用,有时候不是很方便,所以Python可以通过关键字索引将传入的参数组装成字典。
>>> def Fun4(**kwargs):
... print(kwargs, type(kwargs))
...
>>> f = Fun4
>>> f(k1 = 'name', k2 = 'age')
{'k2': 'age', 'k1': 'name'} <class 'dict'>
关键字参数允许传入0个或任意个参数名的参数,0个的话就是一个空字典
3、参数组合
在Python中定义函数,可以用必选参数(位置参数)、默认参数、可变参数、关键字参数这几种参数进行组合使用,但是顺序必须是,必选参数、默认参数、可变参数、关键字参数。
>>> def Fun5(arg1, arg2 = 123, *args, **kwargs):
... print('arg1:',arg1)
... print('arg2:',arg2)
... print('args',args)
... print('kwargs',kwargs)
...
>>> f = Fun5
>>> f('Jason''ss',44,'err',k1 = 234, k2 = 'abc')
arg1: Jasonss
arg2: 44
args ('err',)
kwargs {'k2': 'abc', 'k1': 234}
4、lambda匿名函数
在Python中,提供了对匿名函数的支持,所谓匿名函数就是功能非常简单只需要一行代码就可以实现的,比如之前我们我们之前说的求圆形面积的函数,用匿名函数就可以这样定义。
>>> f = lambda r: 3.14 * r * r >>> print(f(5)) 78.5
说明:r相当于匿名函数的参数,当然也可以有多个参数,不用在写return,表达式就是返回的结果。
使用匿名函数有个好处,疑问函数没有名字,不用担心函数名冲突,此外匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量调用该函数。
lambda表达式
学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即:
# 普通条件语句
if1==1:
name ='wupeiqi'
else:
name ='alex'
# 三元运算
name ='wupeiqi'if1==1else'alex'
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
# ###################### 普通函数 ######################
# 定义函数(普通方式)
deffunc(arg):
returnarg +1
# 执行函数
result =func(123)
# ###################### lambda ######################
# 定义函数(lambda表达式)
my_lambda =lambdaarg : arg +1
# 执行函数
result =my_lambda(123)
lambda存在意义就是对简单函数的简洁表示
5、关于函数的return语句
1)函数可以没有return语句,默认没有return语句返回的就None
2)return语句有点类似循环的break,当函数执行到return语句的时候将不会继续执行下去,直接跳出函数的执行,例如
>> def Fun6():
... print('start')
... return None
... print('end')
...
>>> f = Fun6
>>> f
<function Fun6 at 0x1033ec7b8>
>>> print(Fun6())
start
None
>>> print(f())
start
None
说明:可以看到return语句后面的print('end')根本没有执行。
3)return可以返回多个值,接受的接收的可以使用两个变量接受,也可以一个变量接收
>>> def Fun7():
... return 'abc', 123
...
>>> r1,r2 = Fun7()
>>> print('result1',r1)
result1 abc
>>> print('result2',r2)
result2 123
>>> res = Fun7()
>>> print('res:', res)
res: ('abc', 123)
说明:可以返回多个值就是返回一个元祖,使用两个变量接收的时候回将元祖的元素与变量一一对应赋给多个变量,用一个变量接收的时候就接收了
6、关于可变参数和关键字参数的传递的小技巧
我们已经知道可变参数和关键字参数分别将传递的参数组装成元祖和字典,那么我们同样可以直接将元祖、列表和字典直接传递给函数作为参数,传递的时候列表和元祖要变量名要在前面加一个*,字典要在之前加两个**,否则函数还是会把把它们当成一个普通的参数传递进行处理
>>> def Fun8(*args, **kwargs):
... print(args)
... print(kwargs)
...
>>> list = ['a',123,6,'bb']
>>> dict = {'name':'Jason','age':'20'}
>>> f = Fun8
>>> f(list,dict)
(['a', 123, 6, 'bb'], {'name': 'Jason', 'age': '20'})
{}# 可以看到两个参数都被可变参数接收了,关键字参数啥也没有
>>> f(*list, **dict) ('a', 123, 6, 'bb') {'name': 'Jason', 'age': '20'}
7、内置函数(Built-in Functions)

Python 内置许多参数,下面抽取一些主要的函数学习
1.abs()【绝对值】
>>> abs(-20) 20 >>> abs(10) 10 >>> a = -5 >>> a.__abs__() 5
2.all()集合中的元素都为真的时候为真,若为空串返回为True
>>> li = [0,'Jason'] >>> print(all(li)) False >>> li = [] >>> print(all(li)) True
3.any()集合中的元素有一个为真的时候为真若为空串返回为False
>>> list = [] >>> li = [0,'Jason'] >>> print(any(li)) True >>> print(any(list)) False
4.chr()返回整数对应的ASCII字符
>>> print(chr(65)) A
5.ord()返回字符对应的ASC码数字编号
>>> print(ord('A'))
65
6.bin(x)将整数x转换为二进制字符串
>>> print(bin(33)) 0b100001
7.bool(x)返回x的布尔值
>>> print(bool(0))
False
>>> print(bool(-1))
True
>>> print(bool(123))
True
8.dir()不带参数时,返回当前范围内的变量、方法和定义的类型列表,带参数时,返回参数的属性、方法列表。
>>> dir() ['Fun', 'Fun2', 'Fun3', 'Fun4', 'Fun5', 'Fun6', 'Fun7', 'Fun8', '__builtins__', 'a', 'dict', 'f', 'li', 'list', 'r1', 'r2', 'res', 'sys'] >>> dir(list) ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
9.divmod()分别取商和余数.
>>> divmod(34,3) (11, 1)
10.enumerate()返回一个可枚举的对象,该对象的next()方法将返回一个tuple
>>> test = ['abc','ss','dd'] >>> for k,v in enumerate(test): ... print(k,v) ... 0 abc 1 ss 2 dd
11.eval()将字符串str当成有效的表达式来求值并返回计算结果。
>>> number = '[[3,4],[5,6],[7,9],]'
>>> a = eval(number)
>>> print(a)
[[3, 4], [5, 6], [7, 9]]
12.filter(function, iterable)函数可以对序列做过滤处理
def glhs(num):
if num>5 and num<60:
return num
seq = [1,23,4,3,5,3,44,78,99,57]
result = filter(glhs,seq)
print(list(result))
#[23, 44, 57]
13.hex(x)将整数x转换为16进制字符串。
>>> hex(21) '0x15'
14.id()返回对象的内存地址
>>> id(22) 4297538560
15.len()返回对象的长度
>>> name = 'Jason' >>> len(name) 5
16.map遍历序列,对序列中每个元素进行操作,最终获取新的序列。
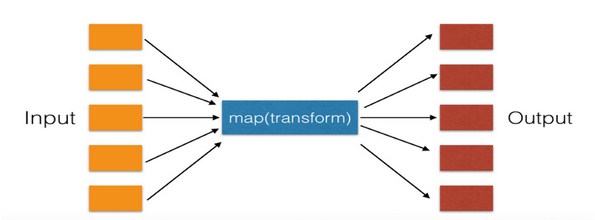
例:
>>> li = [21,33,44] >>> li_1 = map(lambda a: a + 100, li) >>> print(li_1) <map object at 0x10341a3c8> >>> sl = [3,4,5] >>> li2 = map(lambda a, b: a + b, li, sl)
17.oct()八进制转换
>>> oct(10) '0o12'
18.range()产生一个序列,默认从0开始
>>> range(18) range(0, 18)
19.reversed()反转
>>> re = list(range(10)) >>> re [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> re_1 = reversed(re) >>> re_1 <list_reverseiterator object at 0x103432940> >>> print(list(re_1)) [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
20.round()四舍五入
>>> round(4,6) 4 >>> round(5,6) 5
21.sorted()队集合排序
>>> re_1 = [2,3,6,8,2,3,5,1] >>> sorted(re_1) [1, 2, 2, 3, 3, 5, 6, 8]
22.sum()对集合求和
>>> re_1 = [2,3,6,8,2,3,5,1] >>> type(re_1) <class 'list'> >>> sum(re_1) 30
23.type()返回该object的类型
>>> re_1 = [2,3,6,8,2,3,5,1] >>> sorted(re_1) [1, 2, 2, 3, 3, 5, 6, 8] >>> type(re_1) <class 'list'> >>> sum(re_1) 30
24.vars()返回对象的变量,若无参数与dict()方法类似。
>>> vars()
{'sys': <module 'sys' (built-in)>, 're_1': [2, 3, 6, 8, 2, 3, 5, 1], '__builtins__': {'Exception': <class 'Exception'>, 'DeprecationWarning': <class 'DeprecationWarning'>, 'ArithmeticError': <class 'ArithmeticError'>, 'UnicodeWarning': <class 'UnicodeWarning'>, 'TimeoutError': <class 'TimeoutError'>, 'BaseException': <class 'BaseException'>, '_': None, 'min': <built-in function min>, 'ConnectionResetError': <class 'ConnectionResetError'>, 'ImportWarning': <class 'ImportWarning'>, 'setattr': <built-in function setattr>, 'type': <class 'type'>, 'float': <class 'float'>, 'exit': Use exit() or Ctrl-D (i.e. EOF) to exit, 'ImportError': <class 'ImportError'>, 'enumerate': <class 'enumerate'>, 'IndentationError': <class 'IndentationError'>, 'OverflowError': <class 'OverflowError'>, 'NotADirectoryError': <class 'NotADirectoryError'>, 'bool': <class 'bool'>, 'None': None, 'SystemError': <class 'SystemError'>, 'abs': <built-in function abs>, 'Ellipsis': Ellipsis, 'NameError': <class 'NameError'>, 'classmethod': <class 'classmethod'>, 'set': <class 'set'>, 'RecursionError': <class 'RecursionError'>, '__spec__': ModuleSpec(name='builtins', loader=<class '_frozen_importlib.BuiltinImporter'>), 'RuntimeWarning': <class 'RuntimeWarning'>, 'AttributeError': <class 'AttributeError'>, 'list': <class 'list'>, 'IOError': <class 'OSError'>, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, 'EnvironmentError': <class 'OSError'>, 'range': <class 'range'>, 'UnicodeDecodeError': <class 'UnicodeDecodeError'>, 'KeyError': <class 'KeyError'>, 'dict': <class 'dict'>, 'IndexError': <class 'IndexError'>, 'bytearray': <class 'bytearray'>, 'globals': <built-in function globals>, 'hasattr': <built-in function hasattr>, 'SyntaxError': <class 'SyntaxError'>, 'EOFError': <class 'EOFError'>, 'next': <built-in function next>, 'ZeroDivisionError': <class 'ZeroDivisionError'>, 'all': <built-in function all>, 'FileNotFoundError': <class 'FileNotFoundError'>, 'frozenset': <class 'frozenset'>, 'NotImplementedError': <class 'NotImplementedError'>, 'print': <built-in function print>, 'RuntimeError': <class 'RuntimeError'>, 'NotImplemented': NotImplemented, 'map': <class 'map'>, 'UnicodeError': <class 'UnicodeError'>, 'filter': <class 'filter'>, 'StopAsyncIteration': <class 'StopAsyncIteration'>, 'quit': Use quit() or Ctrl-D (i.e. EOF) to exit, 'IsADirectoryError': <class 'IsADirectoryError'>, 'exec': <built-in function exec>, 'super': <class 'super'>, 'any': <built-in function any>, 'eval': <built-in function eval>, 'staticmethod': <class 'staticmethod'>, 'ReferenceError': <class 'ReferenceError'>, 'len': <built-in function len>, 'license': Type license() to see the full license text, 'KeyboardInterrupt': <class 'KeyboardInterrupt'>, 'input': <built-in function input>, 'slice': <class 'slice'>, 'ascii': <built-in function ascii>, 'hex': <built-in function hex>, 'True': True, '__build_class__': <built-in function __build_class__>, 'ConnectionRefusedError': <class 'ConnectionRefusedError'>, 'ConnectionAbortedError': <class 'ConnectionAbortedError'>, 'FloatingPointError': <class 'FloatingPointError'>, 'issubclass': <built-in function issubclass>, 'BrokenPipeError': <class 'BrokenPipeError'>, 'isinstance': <built-in function isinstance>, 'vars': <built-in function vars>, 'FileExistsError': <class 'FileExistsError'>, 'complex': <class 'complex'>, 'open': <built-in function open>, 'reversed': <class 'reversed'>, 'PendingDeprecationWarning': <class 'PendingDeprecationWarning'>, 'PermissionError': <class 'PermissionError'>, 'bin': <built-in function bin>, 'ConnectionError': <class 'ConnectionError'>, 'SyntaxWarning': <class 'SyntaxWarning'>, 'UnboundLocalError': <class 'UnboundLocalError'>, 'dir': <built-in function dir>, 'repr': <built-in function repr>, 'StopIteration': <class 'StopIteration'>, 'bytes': <class 'bytes'>, 'UnicodeTranslateError': <class 'UnicodeTranslateError'>, 'execfile': <function execfile at 0x103253b70>, 'sum': <built-in function sum>, 'OSError': <class 'OSError'>, 'MemoryError': <class 'MemoryError'>, 'divmod': <built-in function divmod>, 'BlockingIOError': <class 'BlockingIOError'>, 'ResourceWarning': <class 'ResourceWarning'>, 'compile': <built-in function compile>, 'Warning': <class 'Warning'>, 'SystemExit': <class 'SystemExit'>, 'getattr': <built-in function getattr>, 'hash': <built-in function hash>, 'ProcessLookupError': <class 'ProcessLookupError'>, 'id': <built-in function id>, 'AssertionError': <class 'AssertionError'>, 'callable': <built-in function callable>, 'locals': <built-in function locals>, 'round': <built-in function round>, 'max': <built-in function max>, 'help': Type help() for interactive help, or help(object) for help about object., 'zip': <class 'zip'>, 'credits': Thanks to CWI, CNRI, BeOpen.com, Zope Corporation and a cast of thousands
for supporting Python development. See www.python.org for more information., 'UserWarning': <class 'UserWarning'>, 'pow': <built-in function pow>, 'runfile': <function runfile at 0x1032c9d90>, '__name__': 'builtins', 'iter': <built-in function iter>, 'tuple': <class 'tuple'>, 'str': <class 'str'>, 'LookupError': <class 'LookupError'>, 'TabError': <class 'TabError'>, '__debug__': True, 'ValueError': <class 'ValueError'>, 'oct': <built-in function oct>, 'False': False, 'TypeError': <class 'TypeError'>, 'BufferError': <class 'BufferError'>, '__package__': '', 'FutureWarning': <class 'FutureWarning'>, 'object': <class 'object'>, '__doc__': "Built-in functions, exceptions, and other objects.
Noteworthy: None is the `nil' object; Ellipsis represents `...' in slices.", 'sorted': <built-in function sorted>, 'memoryview': <class 'memoryview'>, 'chr': <built-in function chr>, 'property': <class 'property'>, 'ord': <built-in function ord>, 'format': <built-in function format>, 'InterruptedError': <class 'InterruptedError'>, 'delattr': <built-in function delattr>, 'UnicodeEncodeError': <class 'UnicodeEncodeError'>, 'BytesWarning': <class 'BytesWarning'>, 'copyright': Copyright (c) 2001-2015 Python Software Foundation.
All Rights Reserved.
25.zip()zip函数接受任意多个(包括0个和1个)序列作为参数,返回一个tuple列表。
26.reduce对于序列内所有元素进行累计操作
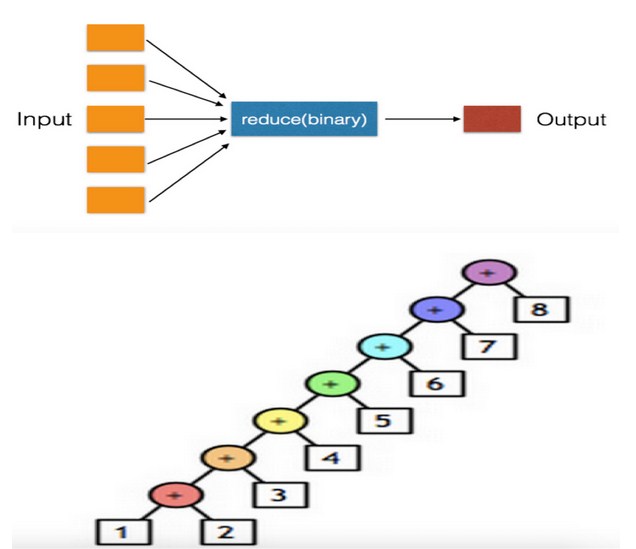
>>> li = [11,22,33] >>> result = reduce(lambda arg1, arg2: arg1 + arg2, li)
# reduce的第一个参数,函数必须要有两个参数# reduce的第二个参数,要循环的序列# reduce的第三个参数,初始值#map(函数, 可迭代对象(可以for循环的东西))
def f2(a):
return a + 100
result = map(f2, li)
print(list(result))
#[111, 122, 133, 144, 155]
li = [11,22,33,44,55]
result = map(lambda a:a +100,li)
print(list(result))
# [111, 122, 133, 144, 155]
#map #将函数返回元素添加到结果中
#filter :函数返回True,将元素添加到结果中
filter(函数,可迭代对象)
def f2(a):
if a>22:
return True
li = [11, 22, 33, 44, 55]
#filter内部,循环第二个参数
#result = []
# for item in 第二个参数:
# r = 第一个参数(item)
# if r:
# result(item)
# return result
ret = filter(f2, li)
print(list(ret))
#[33, 44, 55]
def f1(args):
result = []
for item in args:
if item > 22:
result.append(item)
return result
li = [11,22,33,44,55]
ret = f1(li)
print(ret)
#[33, 44, 55]
lambda自带return
f1 = lambda a: a > 30
ret = f1(40)
print(ret)
#True
li = [11,22,33,44,55]
ret = filter(lambda a: a>33,li)
print(list(ret))
#[44, 55]
def glhs(num):
if num>5 and num<60:
return num
seq = [1,23,4,3,5,3,44,78,99,57]
result = filter(glhs,seq)
print(list(result))
#[23, 44, 57]
>>> li = [11,22,33,44] >>> def f1(arg): ... arg.append(55) ... >>> li = f1(li) >>> print(li) None
##默认return None,参数传递引用 >>> f1(li) Traceback (most recent call last): File "<input>", line 1, in <module> File "<input>", line 2, in f1 AttributeError: 'NoneType' object has no attribute 'append' >>> li = [11,22,33,44] >>> f1(li) >>> print(li) [11, 22, 33, 44, 55]
28.isinstance()函数
r = isinstance(s,list) print(r) #True
29.compile,eval,exec
#compile 编译
#exec 编译成和python一样的东西
s = "print(234)" #将字符串编译成python代码 r = compile(s, "<string>", "exec") #执行,exec执行Python代码和字符串 exec(r) #234
#eval 编译成表达式
s = "8*8" #执行,eval只能执行表达式,有返回值 ret = eval(s) print(ret) # #64
30.bytes函数
>>> s = '老男人' >>> bytes(s,encoding='utf-8') b'xe8x80x81xe7x94xb7xe4xbaxba'
##生成随机验证码(random模块)
import random
li =[]
for i in range(6):
r = random.randrange(0,5)#随机生成0,4之间的数字
if r == 2 or r == 4:#随机生成数字等于2或者4时,追加数字,此位置实现任意位置出现数字的验证码
num = random.randrange(0,10)
li.append(str(num))
else:
temp = random.randrange(65,91)
c = chr(temp)
li.append(c)
print(li)
['Y', 'U', 'R', 'F', 'F', 'F']
result = "".join(li)
print(result)
##随机生成数字和字母组合的验证码
['P', 'D', '4', 'R', 'R', 'S']
PD4RRS
['6', '5', 'U', 'Y', '9', '5']
65UY95
6.open函数(该函数用于文件处理)
1.操作文件步骤:
打开文件
操作文件
关闭文件
2.打开文件模式:
1.file = open("test.txt",w) 直接打开一个文件,如果文件不存在则创建文件
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
关于open 模式:
1 w 以写方式打开, 2 a 以追加模式打开 (从 EOF 开始, 必要时创建新文件) 3 r+ 以读写模式打开 4 w+ 以读写模式打开 (参见 w ) 5 a+ 以读写模式打开 (参见 a ) 6 rb 以二进制读模式打开 7 wb 以二进制写模式打开 (参见 w ) 8 ab 以二进制追加模式打开 (参见 a ) 9 rb+ 以二进制读写模式打开 (参见 r+ ) 10 wb+ 以二进制读写模式打开 (参见 w+ ) 11 ab+ 以二进制读写模式打开 (参见 a+ ) 12 U" 表示在读取时,可以将 自动转换成 (与 r 或 r+ 模式同使用) 13 rU 14 rU+
3.文件操作
1.关闭文件
2.file.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError
2.返回一个长整型的”文件标签“


fp.fileno()
3.读取指定字节数据
fp.read([size]) #size为读取的长度,以byte为单位
4.读一行
1 fp.read([size]) #size为读取的长度,以byte为单位
5.文件每一行作为一个list的一个成员,并返回这个list。
1 fp.readlines([size]) #其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
6.写入
1 fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符
7.全部写入
1 fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
8.把缓冲区的内容写入硬盘
1 fp.flush()
9.判断文件是否为设备文件
fp.isatty() #文件是否是一个终端设备文件(unix系统中的)
10.获取指针位置
fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点
11.指定文件中指针位置
fp.seek(offset[,whence])
#将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
12.返回下一行
fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
13.文件裁成规定的大小
fp.truncate([size]) #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
14.指针是否可操作
seekable() 指针是否可操作
15.是否可写
writable()
4.with函数管理文件
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r') as f: ...
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open('log1') as obj1, open('log2') as obj2: pass
操作文件
# read() # 无参数,读全部;有参数, # b,按字节 # 无b,按字符 # tell() 获取当前指针位置(字节) # seek(1) 指针跳转到指定位置(字节) # write() 写数据,b,字节;无b,字符 # close # fileno # flush 强刷 # readline 仅读取一行 # truncate 截断,指针为后的清空 # for循环文件对象 f = open(xxx) # for line in f: # print(line)
三,装饰器
##装饰器
#@ + 函数名
#功能:
#1.自动执行outer函数并且将其下面的函数f1当作参数传递
#2.将outer函数的返回值,重复赋值给f1
def outer(func):
def inner(*args,**kwargs):
print("before")
r = func(*args,**kwargs)
print("after")
return r
return inner
2、装饰器的调用
@outer def f1(args): print('aa') print(args) return "返回AAA" @outer def f2(a1,a2): print('bb') print(a1,a2) return "返回BBB" @outer def f3(): print('100') return "返回CCC" # def f1(): # print('123') # # def f2(func): # func() # # f2(f1) ##123 a = f1("fuck") print(a) b = f2("sb","qq") print(b) c = f3() print(c) ##执行结果 before aa fuck after 返回AAA before bb sb qq after 返回BBB before 100 after 返回CCC
多层装饰器
1 User_INFO = {} 2 3 def check_login(func): 4 def inner(*args,**kwargs): 5 if User_INFO.get('is_login',None): 6 ret = func(*args, **kwargs) 7 return ret 8 else: 9 print('请登录') 10 11 return inner 12 13 def check_admin(func): 14 def inner(*args,**kwargs): 15 if User_INFO.get('user_type',None) == 2: 16 ret = func(*args,**kwargs) 17 return ret 18 else: 19 print("无权限查看") 20 return inner 21 @check_login 22 @check_admin 23 def index(): 24 print("login success") 25 @check_login 26 def login(): 27 User_INFO['is_login'] = 'True' 28 print("普通用户登录") 29 30 def search(): 31 print("") 32 def main(): 33 while True: 34 inp = input("1.登录2.查看3.后台登录") 35 if inp == '1': 36 User_INFO['is_login'] = True 37 login() 38 elif inp == '2': 39 search() 40 elif inp == '3': 41 User_INFO['user_type'] = 2 42 index() 43 44 main()
3、装饰器原理
f1 = outer(f1)