问题描述:爬取拉勾网python、工作地在北京的相关职业(python,北京),将结果保存。
1.页面分析:
因为拉勾网有反爬虫机制,所以需要设置相应的请求信息,由于职位信息AJAX异步响应在页面,所以直接访问异步请求。

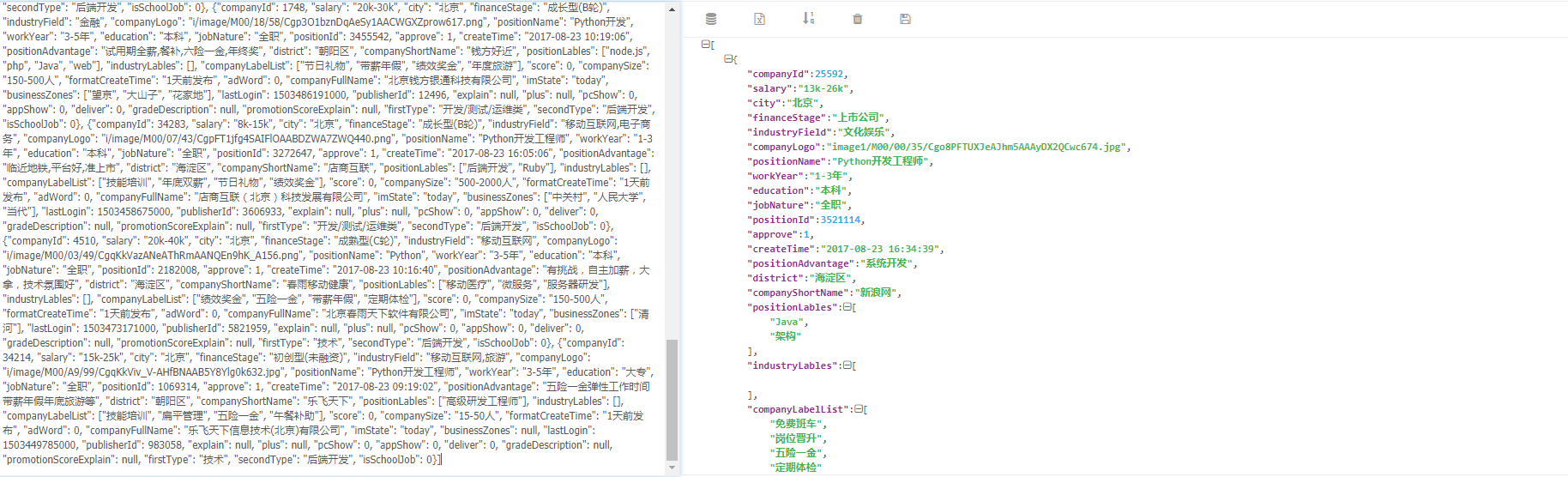
查看响应:
2.代码:
#!/usr/bin/env/python
# coding:utf-8
import sys
import requests
import json
from bs4 import BeautifulSoup as bs
def main():
# 拉勾网有反爬虫机制
# url='https://www.lagou.com/jobs/list_python?px=default&city=%E5%8C%97%E4%BA%AC#filterBox'
# AJAX请求
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0'
# 请求头信息
headers = {
'Cookie': 'SESSIONID=ABAAABAAAIAACBI386BBF2A4AF17A015A35A443275F849E; user_trace_token=20170823222931-7a66d0be-880f-11e7-8e7c-5254005c3644; LGUID=20170823222931-7a66d82d-880f-11e7-8e7c-5254005c3644; X_HTTP_TOKEN=efbd926a2120df44637a9a572dfe0f6e; _putrc=8582F8EBD102AF67; login=true; unick=%E6%8B%89%E5%8B%BE%E7%94%A8%E6%88%B71976; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; TG-TRACK-CODE=search_code; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1503498572; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1503502613; _ga=GA1.2.1002397109.1503498572; _gid=GA1.2.1028357858.1503498572; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_python%3Fpx%3Ddefault%26xl%3D%25E6%259C%25AC%25E7%25A7%2591%26city%3D%25E5%258C%2597%25E4%25BA%25AC; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_python%3Fpx%3Ddefault%26city%3D%25E5%258C%2597%25E4%25BA%25AC; LGSID=20170823233652-e3035a6a-8818-11e7-9fe3-525400f775ce; LGRID=20170823233656-e535491c-8818-11e7-9fe3-525400f775ce; SEARCH_ID=cc7603ed348d42898fdaec6b2dcb5e23; index_location_city=%E5%85%A8%E5%9B%BD',
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?px=default&city=%E5%8C%97%E4%BA%AC',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': None,
'X-Requested-With': 'XMLHttpRequest'
}
for pn in range(1, 31):
# post参数
post_form = {
'kd': 'python'
}
post_form['first'] = 'false'
post_form['pn'] = str(pn)
if pn == 1:
post_form['first'] = 'true'
# 获取页面
result = requests.post(url, headers=headers, data=post_form)
if result.status_code != 200:
print('requet failed!')
sys.exit()
# print(result.content.decode('utf-8'))
file = 'position/positions_page' + str(pn) + '.json'
try:
result_json = result.json()
# print(type(result_json))
positions = result_json['content']['positionResult']['result']
line = json.dumps(positions, ensure_ascii=False)
with open(file, 'w', encoding='utf8') as file:
file.write(line)
print('save ',file ,' successfully!')
except Exception as e:
print('save ', file, ' failed!')
if __name__ == '__main__':
main()
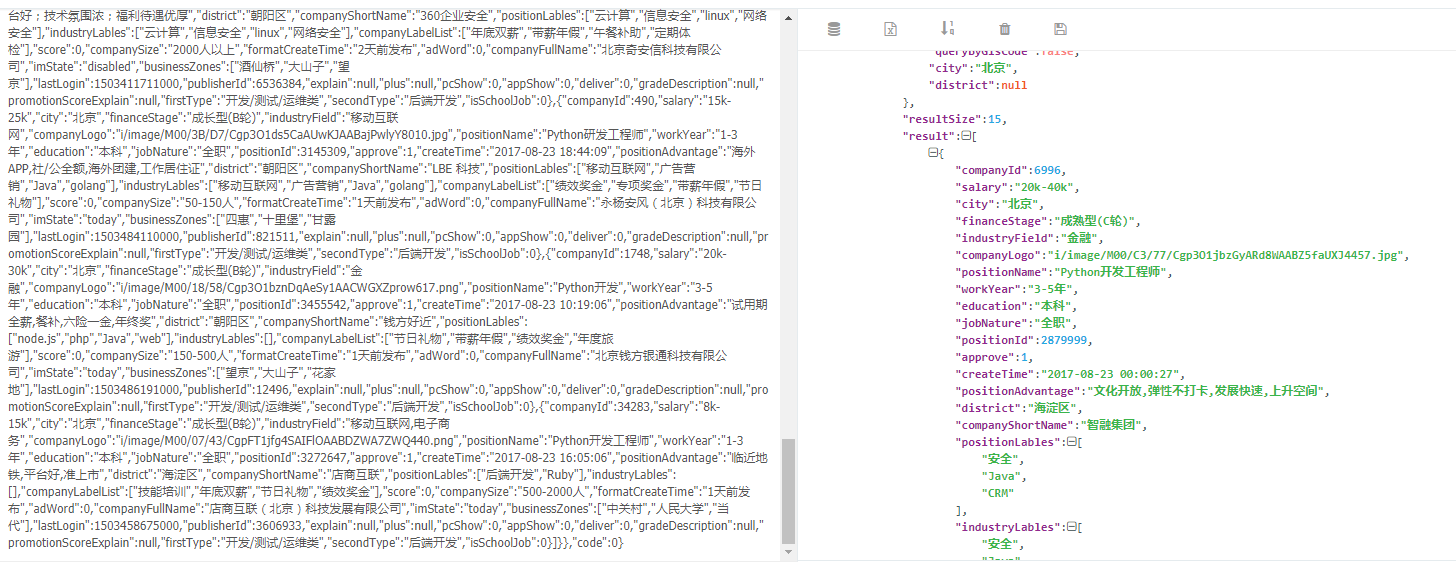
3.运行结果:
将结果以json格式保存到文件中:


格式化显示: