在单台机器或者单个进程中,如果要调用某个函数,只需要通过函数指针,传入相关参数,即可调用成功并获得结果。但如果是在分布式系统中,某个进程想要调用远程机器上的其它进程提供的方法(服务),就需要采用RPC的方式了。
那么Client端发出方法调用,如何才能让Server端知道到底是调用的哪个方法,参数是如何跨机器传输的呢?这里有三点非常重要:Call ID映射,序列化,网络传输。Call ID的思想是,让Client端和Server端分别维持同一个Map,该Map保存着函数和ID的映射关系, 当Client 端需要调用远程方法时,就查一下这个表,找出相应的Call ID,然后把它传给Server端,Server端也通过查表,来确定Client需要调用的函数,然后执行相应的函数。而参数传递需要通过网络(TCP),以二进制流的形式传输到服务端,服务端接受之后将其反序列化成自己能读取的格式,当函数执行完成之后,生成的结果又会序列化成二进制流,传递给Client端供反序列化。
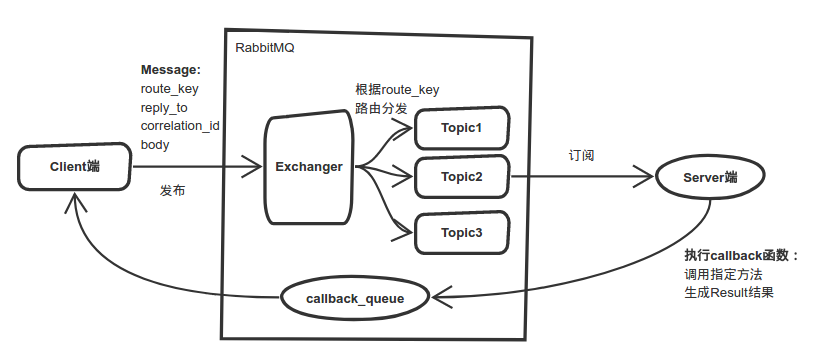
RPC也可以通过RabbitMQ消息中间件实现:Client端发送消息到RabbitMQ中,该消息包含了body(函数参数),reply_to(Server端处理完消息后,将生成的结果发送到RabbitMQ的reply_to队列中),correlation_id(如何才能知道Result属于哪一个Client呢?通过该ID进行match),routing_key(指明该消息发送到哪个Topic队列中,即到底调用哪个远程函数);Server端订阅该Topic,当该Topic队列中有消息时,就立即处理(通过回调函数,调用指定的某个方法,并将生成的结果发送回reply_to队列)。