StandardAnalyzer 是单词分词器:
String msg = "我喜欢你,我的祖国!china 中国,I love you!中华人民共和国";
分词后的结果:[我],[喜],[欢],[你],[我],[的],[祖],[国],[china],[中],[国],[i],[love],[you],[中],[华],[人],[民],[共],[和],[国]
IKAnalyzer 是中文分词器:
分词后的结果:[我],[喜欢],[你],[我],[的],[祖国],[china],[中国],[i],[love],[you],[中华人民共和国]
package com.shrio.lucene; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.apache.lucene.util.Version; import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.IOException; import java.io.StringReader; /** * Created by luojie on 2018/4/24. */ public class ChineseAnalyerDemo { /**standardAnalyer分析器 ,Lucene内置中文分析器*/ public void standardAnalyer(String msg){ StandardAnalyzer analyzer = new StandardAnalyzer(Version.LUCENE_4_10_4); this.getTokens(analyzer, msg); } /**IK Analyzer分析器*/ public void iKanalyer(String msg){ IKAnalyzer analyzer = new IKAnalyzer(true);//当为true时,分词器进行最大词长切分 //IKAnalyzer analyzer = new IKAnalyzer(); this.getTokens(analyzer, msg); } private void getTokens(Analyzer analyzer, String msg) { try { TokenStream tokenStream=analyzer.tokenStream("content", new StringReader(msg)); tokenStream.reset(); this.printTokens(analyzer.getClass().getSimpleName(),tokenStream); tokenStream.end(); } catch (IOException e) { e.printStackTrace(); } } private void printTokens(String analyzerType,TokenStream tokenStream){ CharTermAttribute ta = tokenStream.addAttribute(CharTermAttribute.class); StringBuffer result =new StringBuffer(); try { while(tokenStream.incrementToken()){ if(result.length()>0){ result.append(","); } result.append("["+ta.toString()+"]"); } } catch (IOException e) { e.printStackTrace(); } System.out.println(analyzerType+"->"+result.toString()); } }
package com.shrio.lucene; import org.junit.Before; import org.junit.Test; /** * Created by luojie on 2018/4/24. */ public class TestChineseAnalyizer { private ChineseAnalyerDemo demo = null; private String msg = "我喜欢你,我的祖国!china 中国,I love you!中华人民共和国"; //private String msg = "I love you, China!B2C"; @Before public void setUp() throws Exception { demo=new ChineseAnalyerDemo(); } @Test public void testStandardAnalyer(){ demo.standardAnalyer(msg); demo.iKanalyer(msg); } @Test public void testIkAnalyzer(){ demo.iKanalyer(msg); } }
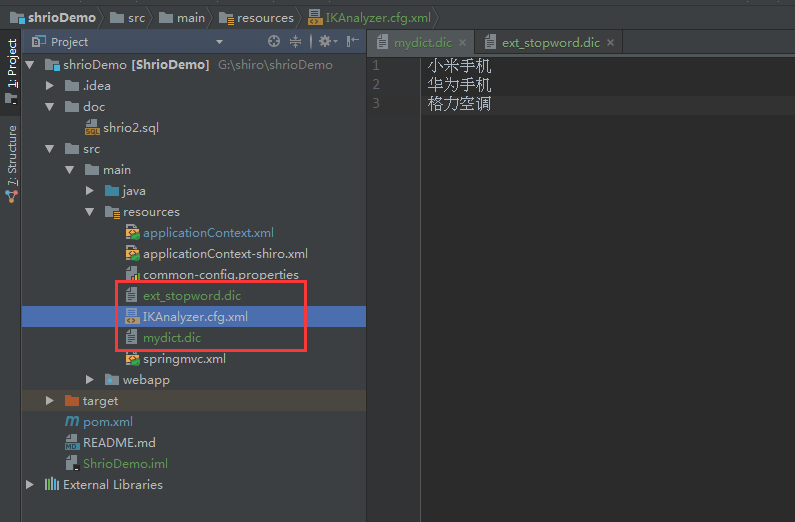
IKAnalyzer 独立使用 配置扩展词典
IKAnalyzer.cfg.xml必须在src根目录下
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!-- 用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">mydict.dic</entry>
<!-- 用户可以在这里配置自己的扩展停用词字典 -->
<entry key="ext_stopwords">ext_stopword.dic</entry>
</properties>