数据仓库主要特点:
面向主题:从不同业务系统抽取同一主题数据
集成的:通过对独立异构的数据最终归纳到一个主题下需要一系列的转换(ETL)
非易失的:只能追加不能更改
时变的:随时间不断变化(存储一段时间的数据,定时删除过时的数据,添加新的数据)
Hive利用hdfs存储数据,利用mapreduce查询分析数据
Hive优化:看作mapreduce处理
1. 排序优化:sort by 效率高于order by,因为order by是全局排序,sort by可以设置mapred.reduce.tasks,多个task并行排序
2. 分区:使用静态分区,每个分区对应hdfs上的一个目录,减少job和task数量
3. 使用表连接,解决group by数据倾斜问题
4. 设置hive.groupby.skewindata=true,那么hive会自动负载均衡,小文件合成大文件
5. 使用自定义函数UDF,写一个UDF函数,在建表的时候制定好分区
6. Reduce数据在代码中介于节点数*reduceTask的最大数量的0.95倍到1.75倍
7. 配置文件中,打开在 map 端的合并
8. 在库表设计的时候,尽量考虑rowkey 和 columnfamily的特性
分区作用:防止数据倾斜
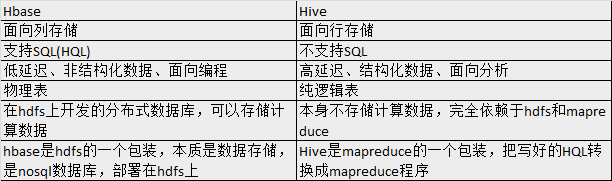
Hive与Hbase区别:
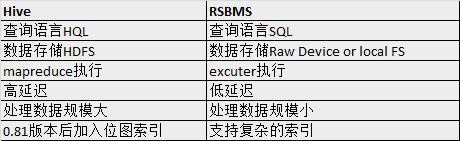
Hive和关系型数据库区别:
内部表和外部表的区别:
创建:外部表需指定location
加载数据文件:内部表会将数据移动到数据仓库指向的路径,使用load data [local] inpath 'dir/data.txt' into table table_name;才能加载数据到表中,而外部表只需将数据文件上传至外部表统一路径即可自动加载数据
删除表:内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据
Hive 有哪些方式保存元数据,各有哪些优缺点。
1. 存储于 derby数据库,此方法只能开启一个hive客户端,不推荐使用
2. 存储于mysql数据库中,可以多客户端连接,推荐使用。
Hive 的 join 有几种方式:
1. 在reduce端进行join(最常用)
2. 在 map 端进行 join,使用场景:一张表十分小、一张表很大。
3. SemiJoin,semijoin 就是左边连接是 reducejoin 的一种变种,在 map 端过滤掉一些数据,在网络传输过程中,只传输参与连接的数据,减少了 shuffle的网络传输量,其他和 reduce的思想是一样的。