---恢复内容开始---
1.分布式爬虫
1.使用Selenium+Phantoms
登录
最重要的设置是User-Agent(UA),否则无法跳转链接
from selenium.webdriver.common.desired_capabilities(功能) import DesiredCapabilities
User_Agent=(..........................................)
dcap=dict(DesiredCapabilities.PHANTOMJS)
dcap=["phantomjs.page.settings.UserAgent"]=user_agent
driver=webdriver.phantomJS(desired_capabilities=dcap)
使用用户名与密码
<input id="loginname"
type="text"
class="W_input"maxlength="128"
autocomplete="off"
action-data="text=邮箱/会员账号/手机号”
action-type="text_copy"
name="username"
node-type="username"tabindex="1"
为了与微博内容交互,需要使用JavaScript
相关JavaScript代码:
document.getElementByID(‘loginname’).value=‘abc’
document.getElementByName(‘password’)[0].value='abc'
通过Selenium提供的send_keys来传递value
driver.find_element_by_id(‘loginname’).send_keys(username)
driver.find_element_by_name(‘password’).send_keys(password)
2.微博web图分析
关注列表、粉丝列表、作为漫游weibo的外链
获取微博外链
driver.find_element_by_xpath(‘//a[@class="t_link S_txt1"]’)
打开关注列表页
driver.find_element_by_xpath(‘//a[@class="t_link S_txt1"]’).get_attribute('href')
获取所有关注的微博号的地址:
driver.find_element_by_xpath(‘//*[contains(@class,'follow_item']//a[@class=" S_txt1"]’)
3.获取微博用户信息
提取用户的基本信息
链接:用正则表达式把用户的链接参数都去掉
微博昵称及头像
关注、粉丝及微博数量
过滤质量差的用户。对于微博数量少于阈值,或者关注数量超过粉丝数N倍以上的,判定为僵尸粉或广告微博,直接跳过
提取下一页,可以继续查找更多的user
微博信息抽取
微博名:driver.find_element_by_tag_name(‘h1’) #element ,元素
所有的Feed:driver.find_element_by_class_name(‘WB_detil’)
feed={ }
微博图片信息
re.findall('/([^/]+$',image.get_attribute('src'))
微博的图片,只需要保存图片名
http://存储域名/分辨率/文件名
滚频与翻页
每次滚动后检查是否已经出现
微博下一页的class
page next S_txt1 S_line1
driver.find_element_by_xpath(‘//a[@class="page next S_txt1 S_line1"]’).click()
翻页命令:
driver.execute_script(‘window。scrollTo(0,document.body.scrollHeight)’) #execute ,执行
滚屏与翻页
每次滚动后,检查是否已经出现了“下一页”的按钮,如果是则可以停止翻页,否则检查是否出现了“网络超时”的链接,是的话,点击这个链接重新加载
滚屏
for i in range(0,10):
driver.execute_script(‘window.srollTo(0,document.body.scrollHeight)’)
html=driver.page_source
tr=etree.HTML(html)
next_page_url=tr.xpath('//a[contains(@class,'page next")]')
if ien(next_page_url)>0:
return next_page_url[0].get_attribute('href')
if ien(re.findall('点击重新载入‘,html))>0:
driver.find_element_by_link_text(‘点击重新加载’).click( )
微博抓取框架:
web1:Crawler(爬行者) web2:User Info
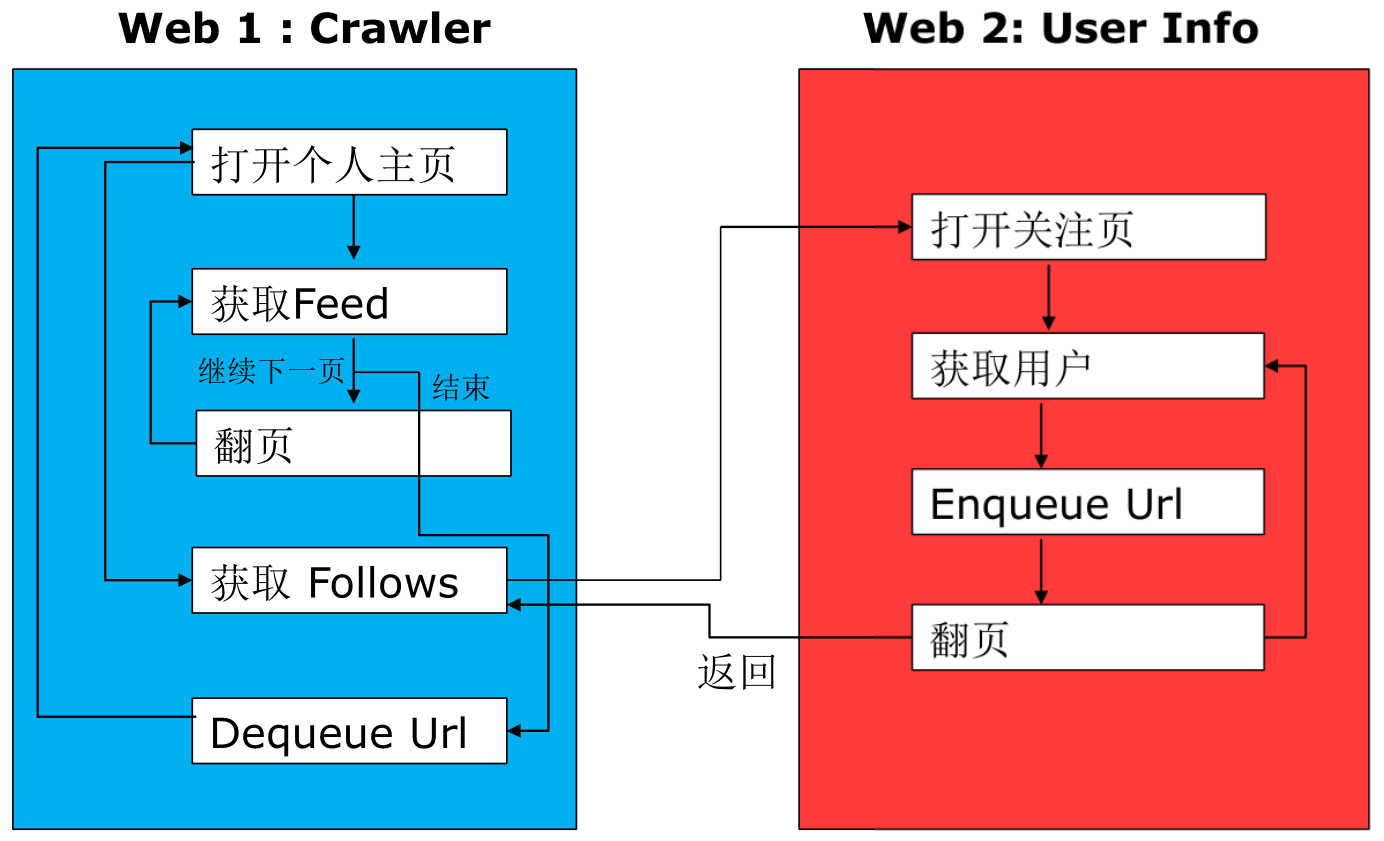
微博接口分析:
微博域名:http://m.weibo.cn
这是微博的首页网页版,能看到结构非常简单,能直接拿到Feed流,可以尝试从移动端来分析微博的数据API接口
个人首页:
包含一些未知参数列表uid、luicode、ifid、featurecode
个人feed流:
AJAX请求

type:通过uid方式查询
value:user id
containerid:容器的id号=107603+uid
个人feed流翻页
向下滚动,获得更多feed流,观察新的请求
type:通过uid方式查询
value:user id
containerid:容器的id号=107603+uid
page:当前请求的页码
点击打开个人关注页
3个接口
关注列表:followersrecomm_-_126632
推介列表:followers_-_1266321801&lui
粉丝列表:fans_-_1266321801&luicode
---恢复内容结束---
1.分布式爬虫
1.使用Selenium+Phantoms
登录
最重要的设置是User-Agent(UA),否则无法跳转链接
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities #capabilities,功能
User_Agent=(..........................................)
dcap=dict(DesiredCapabilities.PHANTOMJS)
dcap=["phantomjs.page.settings.UserAgent"]=user_agent
driver=webdriver.phantomJS(desired_capabilities=dcap)
使用用户名与密码
<input id="loginname"
type="text"
class="W_input"maxlength="128"
autocomplete="off"
action-data="text=邮箱/会员账号/手机号”
action-type="text_copy"
name="username"
node-type="username"tabindex="1"
为了与微博内容交互,需要使用JavaScript
相关JavaScript代码:
document.getElementByID(‘loginname’).value=‘abc’
document.getElementByName(‘password’)[0].value='abc'
通过Selenium提供的send_keys来传递value
driver.find_element_by_id(‘loginname’).send_keys(username)
driver.find_element_by_name(‘password’).send_keys(password)
2.微博web图分析
关注列表、粉丝列表、作为漫游weibo的外链
获取微博外链
driver.find_element_by_xpath(‘//a[@class="t_link S_txt1"]’)
打开关注列表页
driver.find_element_by_xpath(‘//a[@class="t_link S_txt1"]’).get_attribute('href')
获取所有关注的微博号的地址:
driver.find_element_by_xpath(‘//*[contains(@class,'follow_item']//a[@class=" S_txt1"]’)
3.获取微博用户信息
提取用户的基本信息
链接:用正则表达式把用户的链接参数都去掉
微博昵称及头像
关注、粉丝及微博数量
过滤质量差的用户。对于微博数量少于阈值,或者关注数量超过粉丝数N倍以上的,判定为僵尸粉或广告微博,直接跳过
提取下一页,可以继续查找更多的user
微博信息抽取
微博名:driver.find_element_by_tag_name(‘h1’)
所有的Feed:driver.find_element_by_class_name(‘WB_detil’)
feed={ }
微博图片信息
re.findall('/([^/]+$',image.get_attribute('src'))
微博的图片,只需要保存图片名
http://存储域名/分辨率/文件名
滚频与翻页
每次滚动后检查是否已经出现
微博下一页的class
page next S_txt1 S_line1
driver.find_element_by_xpath(‘//a[@class="page next S_txt1 S_line1"]’).click()
翻页命令:
driver.execute_script(‘window。scrollTo(0,document.body.scrollHeight)’)
滚屏与翻页
每次滚动后,检查是否已经出现了“下一页”的按钮,如果是则可以停止翻页,否则检查是否出现了“网络超时”的链接,是的话,点击这个链接重新加载
滚屏
for i in range(0,10):
driver.execute_script(‘window.srollTo(0,document.body.scrollHeight)’)
html=driver.page_source
tr=etree.HTML(html)
next_page_url=tr.xpath('//a[contains(@class,'page next")]') #contains,包含
if ien(next_page_url)>0:
return next_page_url[0].get_attribute('href')
if ien(re.findall('点击重新载入‘,html))>0:
driver.find_element_by_link_text(‘点击重新加载’).click( )
微博抓取框架:
web1:Crawler web2:User Info
微博接口分析:
微博域名:http://m.weibo.cn
这是微博的首页网页版,能看到结构非常简单,能直接拿到Feed流,可以尝试从移动端来分析微博的数据API接口
个人首页:
包含一些未知参数列表uid、luicode、ifid、featurecode
个人feed流:
AJAX请求
type:通过uid方式查询
value:user id
containerid:容器的id号=107603+uid
个人feed流翻页
向下滚动,获得更多feed流,观察新的请求
type:通过uid方式查询
value:user id
containerid:容器的id号=107603+uid
page:当前请求的页码
点击打开个人关注页
3个接口
关注列表:followersrecomm_-_126632
推介列表:followers_-_1266321801&lui
粉丝列表:fans_-_1266321801&luicode