查找:
在一些数据元素中,通过一定的方法找出与给定关键字相同的数据元素的过程
列表查找(线性表查找):
从列表中查找指定的元素
输入:列表、待查找元素
输出:元素下标(未找到元素的时候一般返回None或者-1)
顺序查找(Linear_Search):
def Linear_search(li, val):
for index, v in enumerate(li):
if v == val:
return index
else:
return
n为列表长度,没有循环迭代的过程
时间复杂度:
O(n)
二分查找(Binary_Search):
又叫折半查找,从有序列表的初始候选区li[0:n]开始,通过对待查找的值与候选区中间值的比较,可以使候选区减少一半
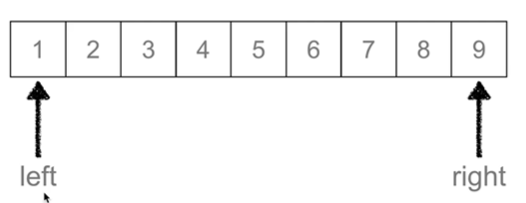
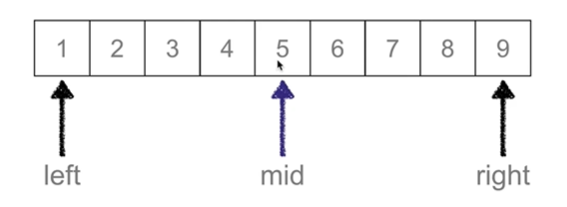
right = mid - 1
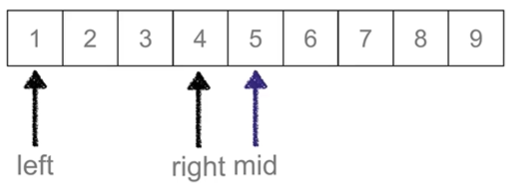
新的mid 就是2
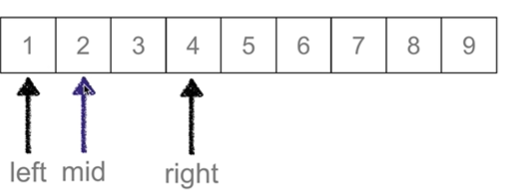
left = mid + 1

def Binary_Search(li, val):
left = 0
right = len(li)-1
while left <= right: # 候选区还有数值
mid = (left + right) // 2
if li[mid] == val:
return mid
elif li[mid] > val: # 查找的值在mid左侧
right = mid - 1 # !!!!!!!!!!!!!!!!!!!!!!!!
else: # li[mid] < val 说明带查找的值在mid的右侧
left = mid + 1
else:
return None
时间复杂度为 O(logn)
排序:

Bubble Sort (冒泡排序)
列表每两个相邻的数,如果前面比后面大,那么交换这两个数。
一趟排序完成后,则无序区减少一个数,有序区增加一个数。(出现最大的数)(n-1趟)
代码关键: 趟、无序区
时间复杂度 : O(n^2)
def bubble_sort(li): for i in range(len(li) - 1): # 第i趟 exchange = False for j in range(len(li) - i - 1): # 为什么要减去i,因为冒泡排序随每i趟而减少循环i次, 这里是无序区的数 @@@@!!!!!!!!!!!!!!!!!!!!!!! if li[j] > li[j+1]: # reversed 就为 降序 li[j], li[j+1] = li[j+1], li[j] # 交换 exchange = True if not exchange: return return li
exchange 是为了防止这样排序 [1,2,3,4,5,6,7,1,9]
Select Sort (选择排序)
一趟排序记录最小的数,放到第一个位置
再一趟排序记录记录列表无序区最小的数,放到第二个位置
def select_sort_simple(li): li_new = [] for i in range(len(li)): for val in range(len(li)): min_val = min(li) # 要遍历 li_new.append(min_val) li.remove(min_val) # 也是要遍历 return li_new
min O(n)
remove O(n)
这个时间复杂度不是1的。
def select_sort(li): for i in range(len(li) - 1): # i是第几趟 min_loc = i for j in range(i, len(li)): # 包前不包后 i 和 i +1 也行 if li[j] < li[min_loc]: # 判定如果小于 min_loc = j # 无序区最小的数 li[i], li[min_loc] = li[min_loc], li[i] print('第%s趟' % i) print(li)
时间复杂
O(n^2)

算法关键:
有序区和无序区
插入排序
初始时手里(有序区)只有一张牌
每次(从无序区摸一张牌,插入到手里已有牌的正确位置)
def insert_sort(li): for i in range(1, 2len(li)): # 摸到牌的下标,开始就是1 tmp = li[i] # tmp摸到的牌的数值 j = i - 1 # 开始手里的牌 的下标 7 while li[j] > tmp and j >= 0: # 找到比他小的牌就退出 7 > 6 J>=0解析 如果摸出来的是最小的数,那么j已经小于0了,所以要退出循环,并且下标为j+1的数为摸到的数,也就是我们刚刚说的数 li[j+1] = li[j] # 往右移 j -= 1 # 往左移动1个单位 li[j+1] = tmp # li = [2, 1, 3, 6, 5, 7, 12, 4] insert_sort(li) print(li)
开始说牛逼三人组了
快速排序:

1、保证左边的比5小,右边的比5大
2、递归完成排序
拆开成mid,left,right
def _quick_sort(li, left, right): if left < right: # 至少两个元素 mid = partition(li, left, right) _quick_sort(li, left, mid-1) _quick_sort(li, mid+1, right)
partition 划分函数
如何划分呢??
1、先把5这个变量存起来,左边就有一个空位,留给比5小的数字,然后将这个数字放到这个位置
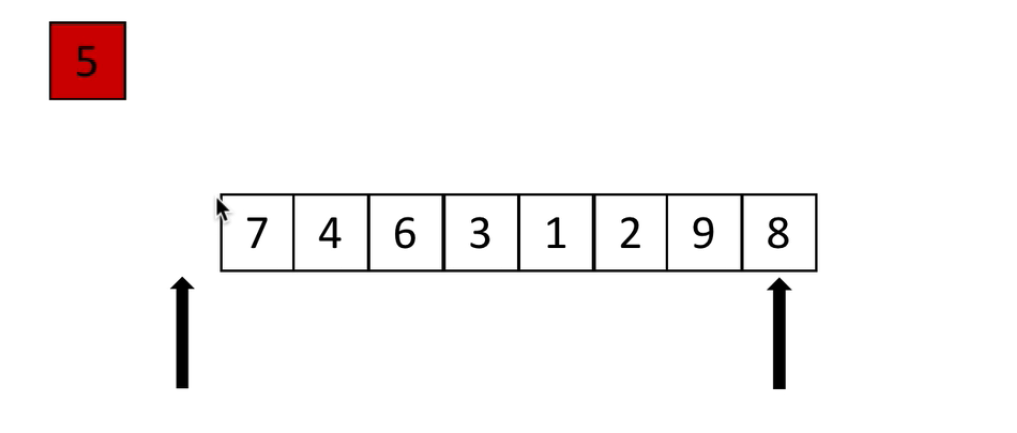
2、从右边开始找,找到2比5小,然后放到第一步5拿走的位置,那么右边就空了一个,那么这个空位是留给比5大的数准备的
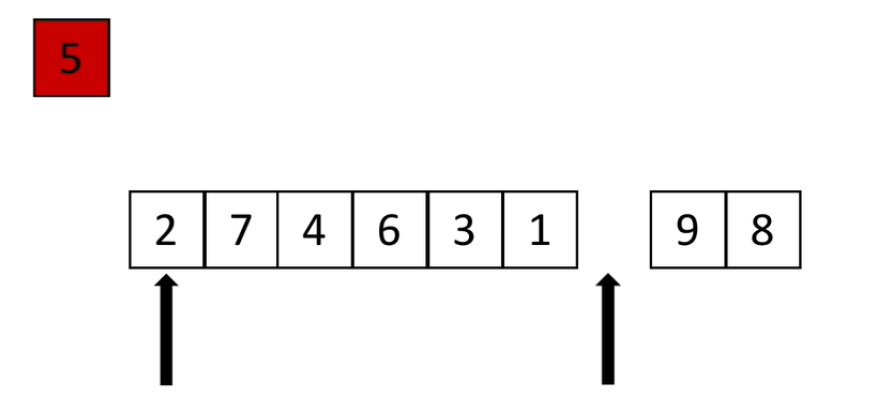
3、继续继续继续下去
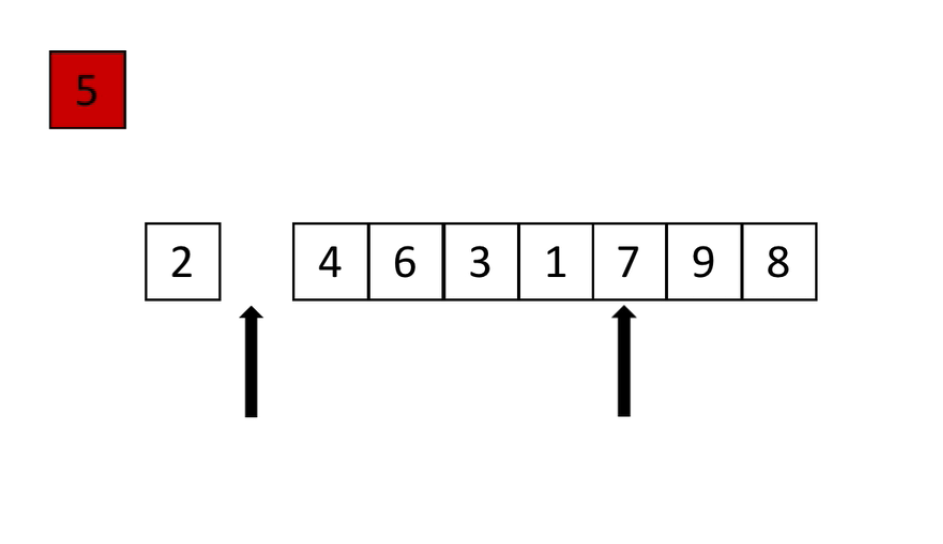
4、重合了,那么这里就是中间了 ![]()
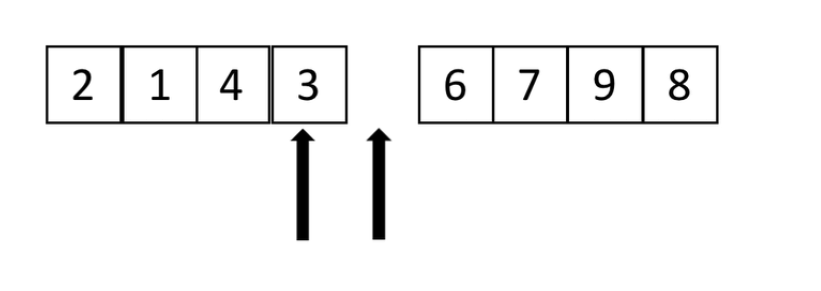
def partition(li, left, right): tmp = li[left] while left < right: while li[right] >= tmp and left < right: # 从右边找比tmp小的数 ,为什么要强调left < right 是因为如果列表里面right数字都比tmp大,那么就会到最前并且跳不出循环 right -= 1 # 往左边走一步 li[left] = li[right] # 把右边的数值写在左边空位上 while left < right and li[left] <= tmp: left += 1 li[right] = li[left] # 把左边的数写道右边空位上 li[left] = tmp # 把tmp归位 return left def _quick_sort(li, left, right): if left < right: # 至少两个元素 mid = partition(li, left, right) _quick_sort(li, left, mid-1) _quick_sort(li, mid+1, right)
快速排序的效率:
快速排序的时间复杂度:
每一层的时间复杂度为O(n)
总共为O(nlogN)
快速排序的问题:
最坏情况
递归
堆排序:
基础知识:
数是一种数据结构。 比如:目录结构
树是一种可以递归定义的数据结构
树是由n个节点组成的集合:
如果n = 0,那就是一颗空树
如果n > 0, 那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合本身又是一棵树
前期概念:
根节点、叶子节点,树的深度、孩子节点、父节点、子树
堆排序前传:
完全二叉树
叶结点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树
满二叉树
一个二叉树,如果每一层的节点数都达到在最大值,则这个二叉树就是满二叉树。

父节点和左孩子节点的编号下标:
2n+1
父节点和右孩子节点的编号下标:
2n+2
堆栈
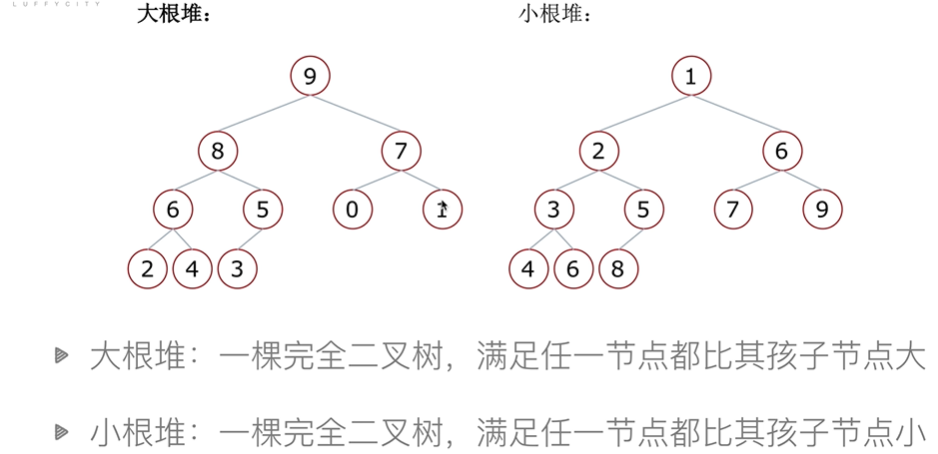
堆排序过程:
简单来说就是农村包围城市

3不断循环,不断拿走堆顶元素,不断将最后一个元素放到堆顶
1、

取9出来,想当于3和9对调位置 ,下一个箭头指的是4了
以此类推
堆的最后一个位置标志为head
挨个出数
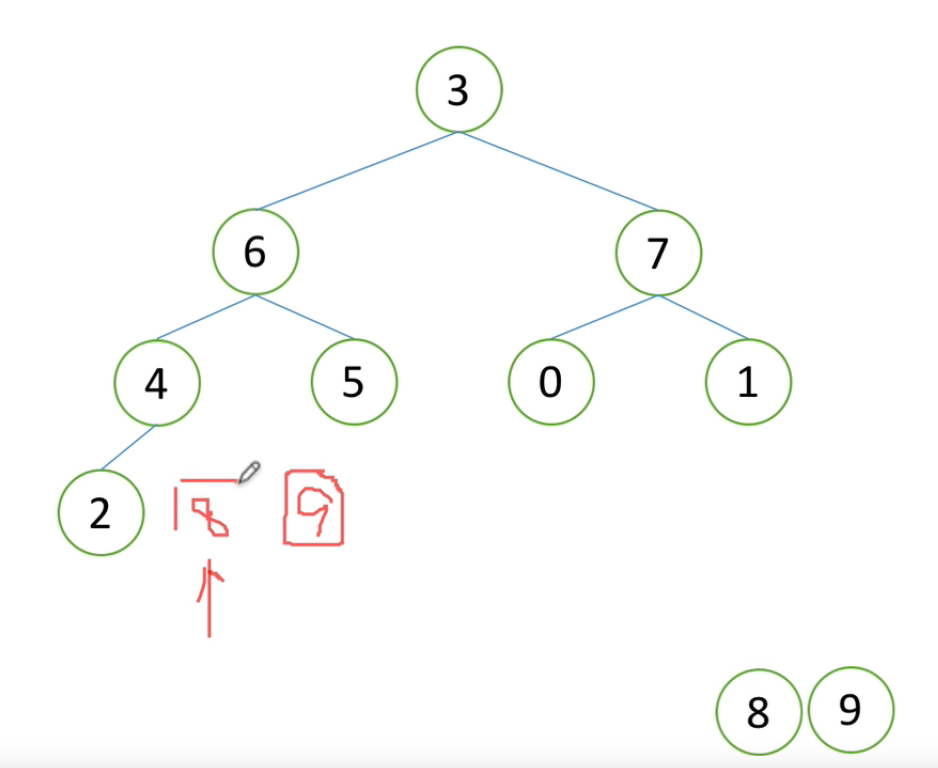
def sift(li, low, high): """ :param li: 列表 :param low: 堆的根节点位置 :param high: 堆的最后一个元素的位置 :return: """ i = low # i是最开始指向的根节点 j = 2 * i + 1 # j开始是左孩子 tmp = li[low] # 把堆顶存起来 # 广东省省长 while j <= high: # 只要j有数 if j + 1 <= high and li[j+1] > li[j]: # 判断右孩子存在且比左孩子大 j = j + 1 # 那么j就要指向右孩子 if li[j] > tmp: # 如果li[j] > tmp 那么 j要上去 li[i] = li[j] # 根节点跟孩子交换 i = j # 这里是重点, 上一层i要移到下一层的i (即时j的位置) j = 2 * i + 1 # j为下一层的孩子 else: # tmp更大了,把tmp放到i的位置上并且不用去找下一层 li[i] = tmp # 把tmp放到某一级上面 break else: li[i] = tmp # 当tmp放到叶子节点上
这个图片就是sift最后else的解析,j已经指向到左下角了,并且j的数值肯定比high大,所以跳出,tmp指向li[i]
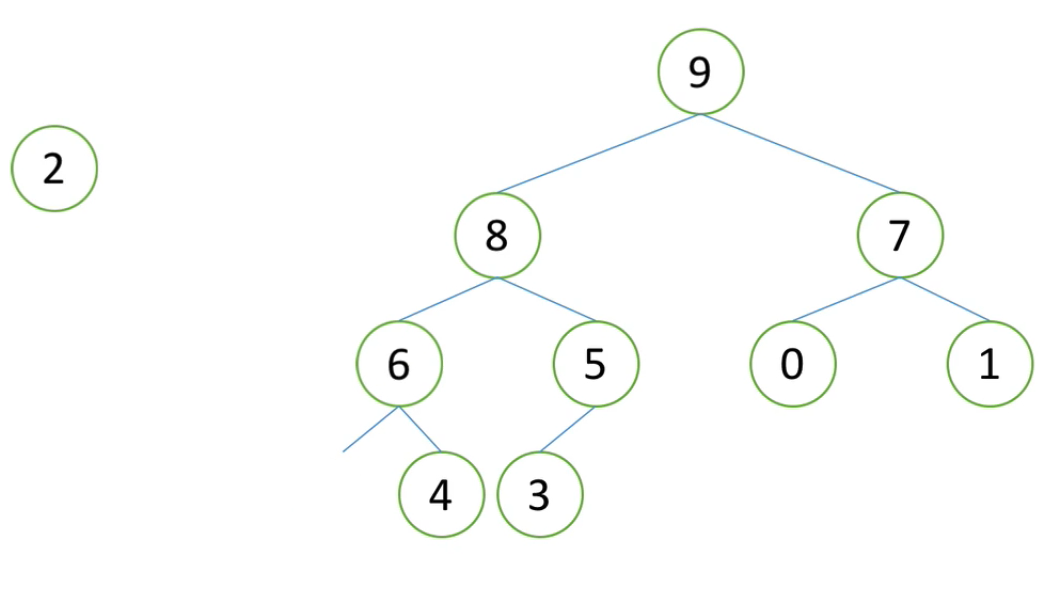
def heap_sort(li): n = len(li) # 获取列表长度 for i in range((n-2)//2, -1, -1): # 从最后开始往前一个一个往前 sift(li, i, n-1) # 为什么是n-1呢,我们的high是拿来判定是否越界 # 建堆完成了 ! for i in range(n-1, -1, -1): # 步长为-1, # i指向当前堆最后一个元素 li[0], li[i] = li[i], li[0] sift(li, 0, i-1) # i-1是新的High
1、先建堆
2、
孩子找父亲,(n-1)/2

如图所示:
5 为n-1,n为列表长度
3 为(n-1-1)//2
堆排序的复杂度:
O(nlog(n))
归并排序:
1、分解:将列表越分越小,直到分成一个元素,左右递归
2、终止条件:一个元素是有序的
3、合并:将两个有序的列表归并,列表越来越大,一个归并合成一次
[1,2,3,4,5,6,7,8,9,10]
如图所示:

NB三人组:时间复杂度都是O(nlogn)
一般情况下,就运行时间来说:
快速排序《 归并排序 《 堆排序
三种排序算法的缺点:
快速排序:极端情况下排序效率低
归并排序:需要额外的内存开销 (不是原地排序)
堆排序: 在快的排序算法中相对较慢 ()

递归是有空间消耗的
希尔排序:
Shell 是一种分组插入排序算法。
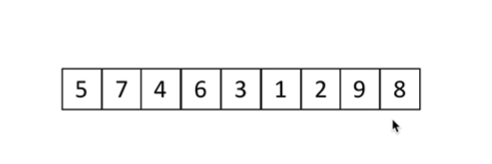
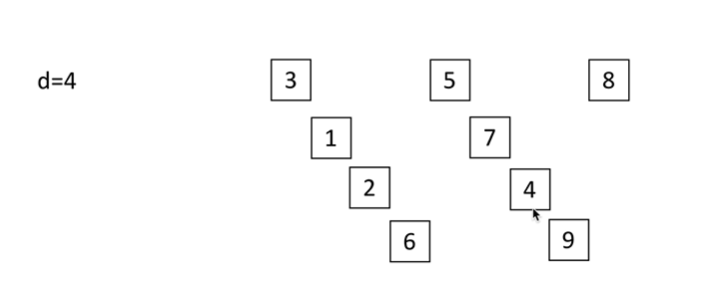
9//2 为4 ,过程在这里分为4个组

插入排序后:
继续分为2组
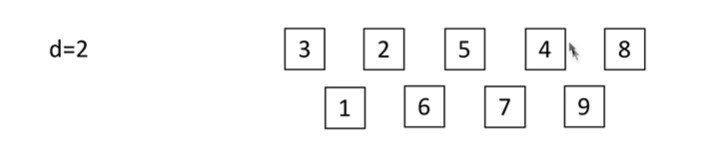
每组再进行插入排序

间隔为4分为一组里面。

最后结束希尔排序
我有问题!!!
如果最后一次可以的话,为什么还要搞前面那两次呢?????并且增加了时间还多了两次
希尔排序每趟并不使某些元素有序,而是是整体数据越来越接近有序;最后一趟排序使得所有数据有序 c
第一趟

第二趟
第三趟

最后一趟

1.31