要求:
1、题目、url、作者、相对时间以及评论数量
2、存入mongoDB
3、模拟Chrome下拉异步加载新闻
4、相对时间的转换(1分钟前。。。。。)
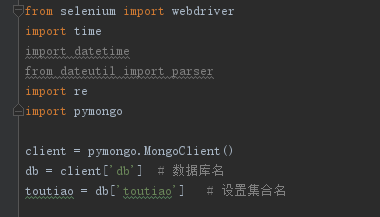
连接mongoDB,设置数据库名和集合名
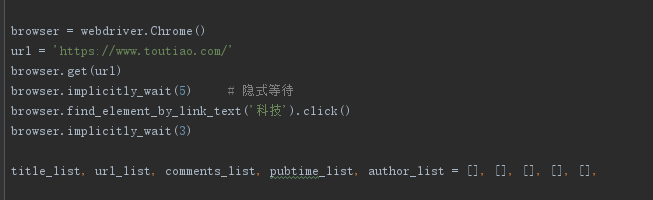
实例化Chrome,隐式等待5秒,点击科技新闻
execue_script 加载js命令运行,两个循环往下拉下去(这里设定了2000条信息)
、
时间转换,我这里比较简单用了正则匹配数字再利用时间戳去量化时间点

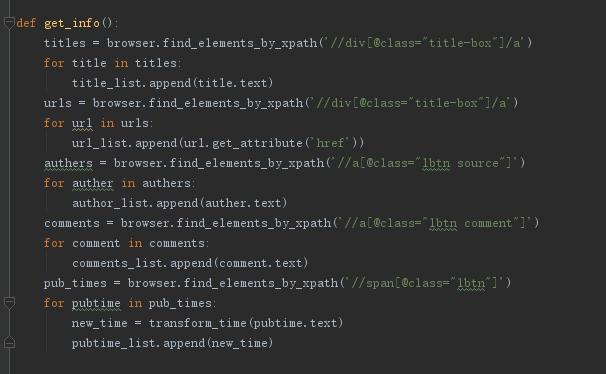
简简单单的获取字段,这里需要注意的是href的提取,以及时间的转化函数
简简单单将信息存入mongodb里面

最后上代码
from selenium import webdriver
import time
import datetime
from dateutil import parser
import re
import pymongo
client = pymongo.MongoClient()
db = client['db'] # 数据库名
toutiao = db['toutiao'] # 设置集合名
browser = webdriver.Chrome()
url = 'https://www.toutiao.com/'
browser.get(url)
browser.implicitly_wait(5) # 隐式等待
browser.find_element_by_link_text('科技').click()
browser.implicitly_wait(3)
title_list, url_list, comments_list, pubtime_list, author_list = [], [], [], [], [],
# 获取科技页面题目,url,作者, 评论数量, 相对时间
def get_page():
time.sleep(3)
while len(title_list) < 2000:
for i in range(50): # 3.要下拉滚动条,搜索解决
js = "var q=document.documentElement.scrollTop={}".format(i * 200) # javascript语句
browser.execute_script(js)
time.sleep(1)
get_info()
else:
browser.close()
def transform_time(t):
if u'刚刚' in t:
c = time.time()
c = time.strftime('%Y年%m月%d日%H时%M分%S秒', time.localtime(c))
return c
min = re.findall('d+', t)[0]
if u'分钟前' in t:
c = time.time() - int(min) * 60 # 量化时间
elif u'小时前' in t:
c = time.time() - int(min)*60*60
elif u'天前' in t:
c = time.time() - int(min)*60*60*24
else:
return None
c = time.strftime('%Y年%m月%d日%H时%M分%S秒', time.localtime(c))
return c
def get_info():
titles = browser.find_elements_by_xpath('//div[@class="title-box"]/a')
for title in titles:
title_list.append(title.text)
urls = browser.find_elements_by_xpath('//div[@class="title-box"]/a')
for url in urls:
url_list.append(url.get_attribute('href'))
authers = browser.find_elements_by_xpath('//a[@class="lbtn source"]')
for auther in authers:
author_list.append(auther.text)
comments = browser.find_elements_by_xpath('//a[@class="lbtn comment"]')
for comment in comments:
comments_list.append(comment.text)
pub_times = browser.find_elements_by_xpath('//span[@class="lbtn"]')
for pubtime in pub_times:
new_time = transform_time(pubtime.text)
pubtime_list.append(new_time)
def save_info():
infos = zip(title_list, url_list, author_list, comments_list, pubtime_list)
for info in infos:
# dateStr = info[4]
# myDatetime = parser.parse(dateStr)
data = {
'标题': info[0],
'url': info[1],
'来源': info[2],
'评论': info[3],
'时间': info[4],
}
result = db['toutiao'].insert_one(data)
print(data)
print('done')
def main():
get_page()
save_info()
if __name__ == '__main__':
main()