- 在map和reduce阶段进行排序时,比较的是k2。v2是不参与排序比较的。如果要想让v2也进行排序,需要把k2和v2组装成新的类,作为k2,才能参与比较。
例子:

二次排序:在第一列有序得到前提下第二列進行排序。
思路:先找<k3,v3>在找<k2,v2>之後的mapreduce就容易寫了
方法1:让输出的第一列作为k3,第二列作为v3 关键:输出的v3需要参与排序,此种方式无法实现二次排序
方法2:让1,2列只作为k3,而v3为空。(
方法3:有可能让k3为空,v3为第二列吗? 答案是不能的,假设k3为空,一般情况下k2也为空,则v2中存放的数据进入后每一组都会放入一个value中,目前没有遇到)
因此,只能选择方法二进行二次排序。
根据前面知识,关键思路:排序和分组是按照k2进行排序和分组的情形需铭记。
第一部分:分部代码
自定义排序:
1 private static class TwoInt implements WritableComparable<TwoInt>{ 2 3 public int t1; 4 public int t2; 5 public void write(DataOutput out) throws IOException { 6 out.writeInt(t1); 7 out.writeInt(t2); 8 } 9 10 public void set(int t1, int t2) { 11 this.t1=t1; 12 this.t2=t2; 13 } 14 15 public void readFields(DataInput in) throws IOException { 16 this.t1=in.readInt(); 17 this.t2=in.readInt(); 18 } 19 20 21 public int compareTo(TwoInt o) { 22 if (this.t1 ==o.t1) { //當第一列相等的時候,第二列升序排列 23 return this.t2 -o.t2; 24 } 25 return this.t1-o.t1;//當第一列不相等的時候,按第一列升序排列 26 } 27 28 }
自定义Mapper类
1 private static class MyMapper extends Mapper<LongWritable, Text, TwoInt, NullWritable>{ 2 TwoInt K2 = new TwoInt(); 3 @Override 4 protected void map(LongWritable key, Text value, 5 Mapper<LongWritable, Text, TwoInt, NullWritable>.Context context) 6 throws IOException, InterruptedException { 7 String[] splited = value.toString().split(" "); 8 K2.set(Integer.parseInt(splited[0]),Integer.parseInt(splited[1])); 9 context.write(K2, NullWritable.get()); 10 } 11 }
自定义Reduce类
1 //按照k2進行排序,分組,此數據分爲6組,在調用Reduce 2 private static class MyReducer extends Reducer<TwoInt, NullWritable, TwoInt, NullWritable>{ 3 @Override 4 protected void reduce(TwoInt k2, Iterable<NullWritable> v2s, 5 Reducer<TwoInt, NullWritable, TwoInt, NullWritable>.Context context) 6 throws IOException, InterruptedException { 7 context.write(k2, NullWritable.get()); 8 } 9 }
捆绑Map和Reduce在一起
1 public static void main(String[] args) throws Exception { 2 Job job = Job.getInstance(new Configuration(), SecondarySortTest.class.getSimpleName()); 3 job.setJarByClass(SecondarySortTest.class); 4 //1.自定义输入路径 5 FileInputFormat.setInputPaths(job, new Path(args[0])); 6 //2.自定义mapper 7 //job.setInputFormatClass(TextInputFormat.class); 8 job.setMapperClass(MyMapper.class); 9 //job.setMapOutputKeyClass(Text.class); 10 //job.setMapOutputValueClass(TrafficWritable.class); 11 12 //3.自定义reduce 13 job.setReducerClass(MyReducer.class); 14 job.setOutputKeyClass(TwoInt.class); 15 job.setOutputValueClass(NullWritable.class); 16 //4.自定义输出路径 17 FileOutputFormat.setOutputPath(job, new Path(args[1])); 18 //job.setOutputFormatClass(TextOutputFormat.class);//对输出的数据格式化并写入磁盘 19 20 job.waitForCompletion(true); 21 }
由此,可以完成二次排序的完整代码如下:


1 package Mapreduce; 2 3 import java.io.DataInput; 4 import java.io.DataOutput; 5 import java.io.IOException; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.LongWritable; 10 import org.apache.hadoop.io.NullWritable; 11 import org.apache.hadoop.io.Text; 12 import org.apache.hadoop.io.WritableComparable; 13 import org.apache.hadoop.mapreduce.Job; 14 import org.apache.hadoop.mapreduce.Mapper; 15 import org.apache.hadoop.mapreduce.Reducer; 16 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 17 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 18 19 public class SecondarySortTest { 20 public static void main(String[] args) throws Exception { 21 Job job = Job.getInstance(new Configuration(), SecondarySortTest.class.getSimpleName()); 22 job.setJarByClass(SecondarySortTest.class); 23 //1.自定义输入路径 24 FileInputFormat.setInputPaths(job, new Path(args[0])); 25 //2.自定义mapper 26 //job.setInputFormatClass(TextInputFormat.class); 27 job.setMapperClass(MyMapper.class); 28 //job.setMapOutputKeyClass(Text.class); 29 //job.setMapOutputValueClass(TrafficWritable.class); 30 31 //3.自定义reduce 32 job.setReducerClass(MyReducer.class); 33 job.setOutputKeyClass(TwoInt.class); 34 job.setOutputValueClass(NullWritable.class); 35 //4.自定义输出路径 36 FileOutputFormat.setOutputPath(job, new Path(args[1])); 37 //job.setOutputFormatClass(TextOutputFormat.class);//对输出的数据格式化并写入磁盘 38 39 job.waitForCompletion(true); 40 } 41 private static class MyMapper extends Mapper<LongWritable, Text, TwoInt, NullWritable>{ 42 TwoInt K2 = new TwoInt(); 43 @Override 44 protected void map(LongWritable key, Text value, 45 Mapper<LongWritable, Text, TwoInt, NullWritable>.Context context) 46 throws IOException, InterruptedException { 47 String[] splited = value.toString().split(" "); 48 K2.set(Integer.parseInt(splited[0]),Integer.parseInt(splited[1])); 49 context.write(K2, NullWritable.get()); 50 } 51 } 52 //按照k2進行排序,分組,此數據分爲6組,在調用Reduce 53 private static class MyReducer extends Reducer<TwoInt, NullWritable, TwoInt, NullWritable>{ 54 @Override 55 protected void reduce(TwoInt k2, Iterable<NullWritable> v2s, 56 Reducer<TwoInt, NullWritable, TwoInt, NullWritable>.Context context) 57 throws IOException, InterruptedException { 58 context.write(k2, NullWritable.get()); 59 } 60 } 61 62 private static class TwoInt implements WritableComparable<TwoInt>{ 63 public int t1; 64 public int t2; 65 public void write(DataOutput out) throws IOException { 66 out.writeInt(t1); 67 out.writeInt(t2); 68 } 69 public void set(int t1, int t2) { 70 this.t1=t1; 71 this.t2=t2; 72 } 73 public void readFields(DataInput in) throws IOException { 74 this.t1=in.readInt(); 75 this.t2=in.readInt(); 76 } 77 public int compareTo(TwoInt o) { 78 if (this.t1 ==o.t1) { //當第一列相等的時候,第二列升序排列 79 return this.t2 -o.t2; 80 } 81 return this.t1-o.t1;//當第一列不相等的時候,按第一列升序排列 82 } 83 @Override 84 public String toString() { 85 return t1+" "+t2; 86 } 87 } 88 }
第二部分:测试代码
(1)准备环境,准备测试数据

[root@neusoft-master filecontent]# vi twoint
3 3
3 2
3 1
2 2
2 1
1 1
(2)创建文件夹,并将文件上传到HDFS中
[root@neusoft-master filecontent]# hadoop dfs -mkdir /neusoft/

[root@neusoft-master filecontent]# hadoop dfs -put twoint /neusoft/

(3)执行jar包,查看中间过程
[root@neusoft-master filecontent]# hadoop jar SecondarySortTest.jar /neusoft/twoint /out8
(4)查看结果
[root@neusoft-master filecontent]# hadoop dfs -ls /out8
[root@neusoft-master filecontent]# hadoop dfs -text /out8/part-r-00000
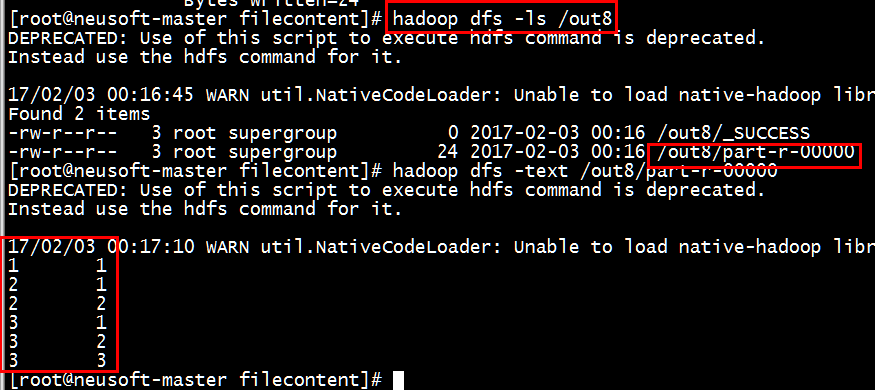
结果正确。
- 如果输出有错误的话,或者输出不是数字(有时候是对象),需要查看是否重写了tostring()方法
注意:如果需求变更为第一列的升序和第二列的降序,只需更改第3行
1 public int compareTo(TwoInt o) { 2 if (this.t1 ==o.t1) { //當第一列相等的時候,第二列降序排列 3 return o.t2-this.t2;
4 } 5 return this.t1-o.t1;//當第一列不相等的時候,按第一列升序排列 6 }
总结:value不能参与排序,如果想参加排序需要放在key中,作为一个新的key进行排序。