字符串匹配KMP算法
KMP 算法是 D.E.Knuth、J,H,Morris 和 V.R.Pratt 三位神人共同提出的,称之为 Knuth-Morria-Pratt 算法,简称 KMP 算法。该算法相对于 Brute-Force(暴力)算法有比较大的改进,主要是消除了主串指针的回溯,从而使算法效率有了某种程度的提高。
一、问题描述
给定一个主串S及一个模式串P,判断模式串是否为主串的子串;若是,返回匹配的第一个元素的位置(序号从1开始),否则返回0;如S=“abcd”,P=“bcd”,则返回2;S=“abcd”,P=“acb”,返回0。
二、KMP算法
上面说道 KMP 算法主要是通过消除主串指针的回溯来提高匹配的效率的,那么,它是则呢样来消除回溯的呢?就是因为它提取并运用了加速匹配的信息!
朴素算法中,P的第j位失配,默认的把P串后移一位。
但在前一轮的比较中,我们已经知道了P的前(j-1)位与S中间对应的某(j-1)个元素已经匹配成功了。这就意味着,在一轮的尝试匹配中,我们get到了主串的部分内容,我们能否利用这些内容,让P多移几位(我认为这就是KMP算法最根本的东西),减少遍历的趟数呢?答案是肯定的。再看下面改进后的动图:
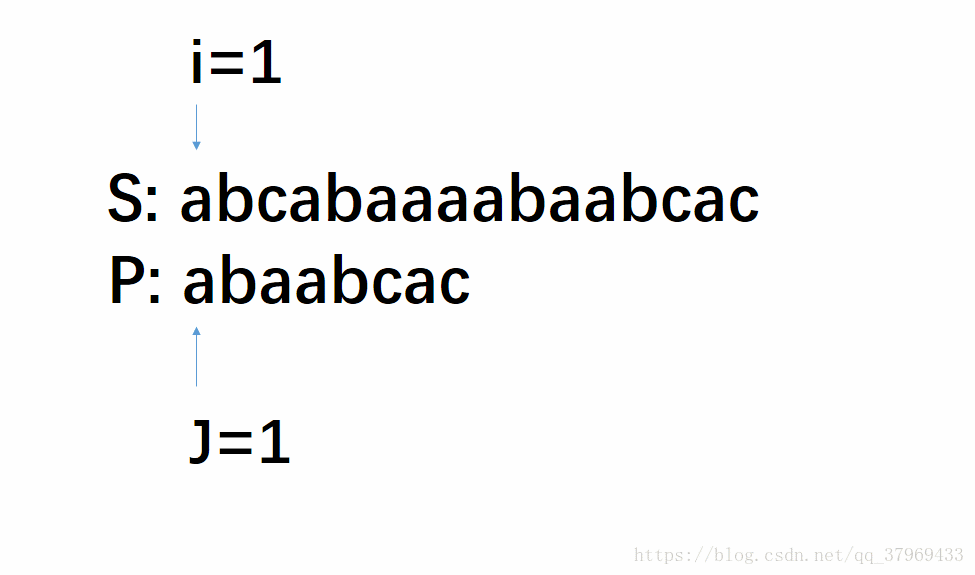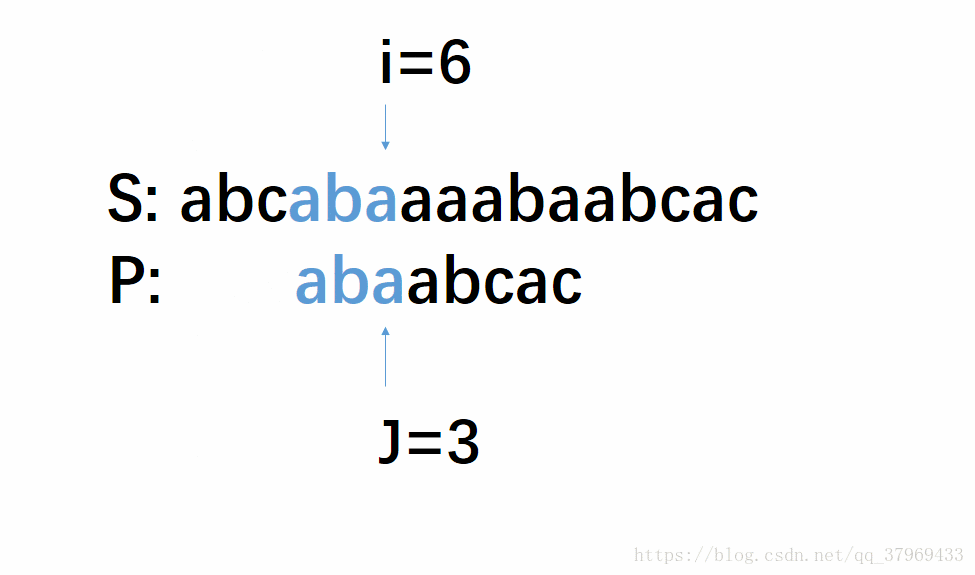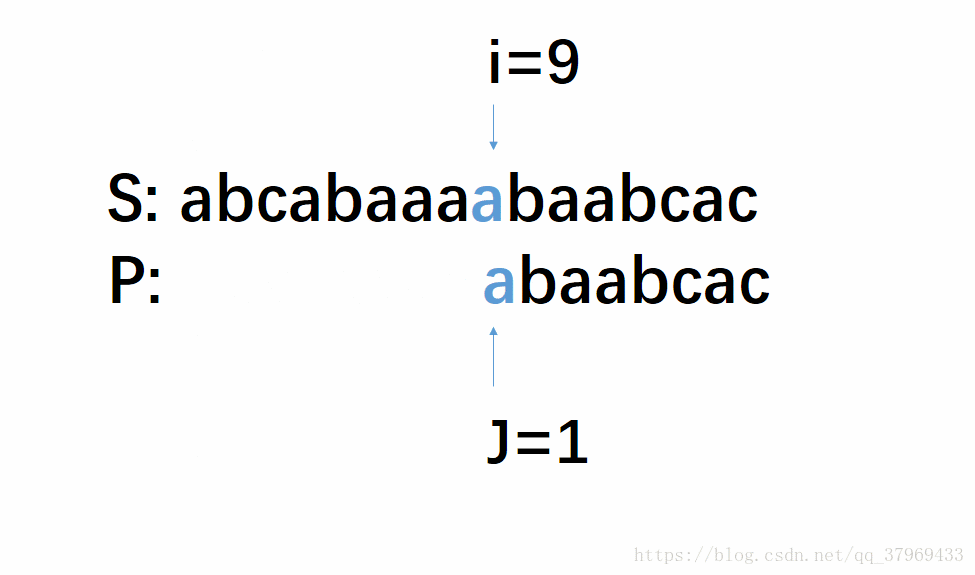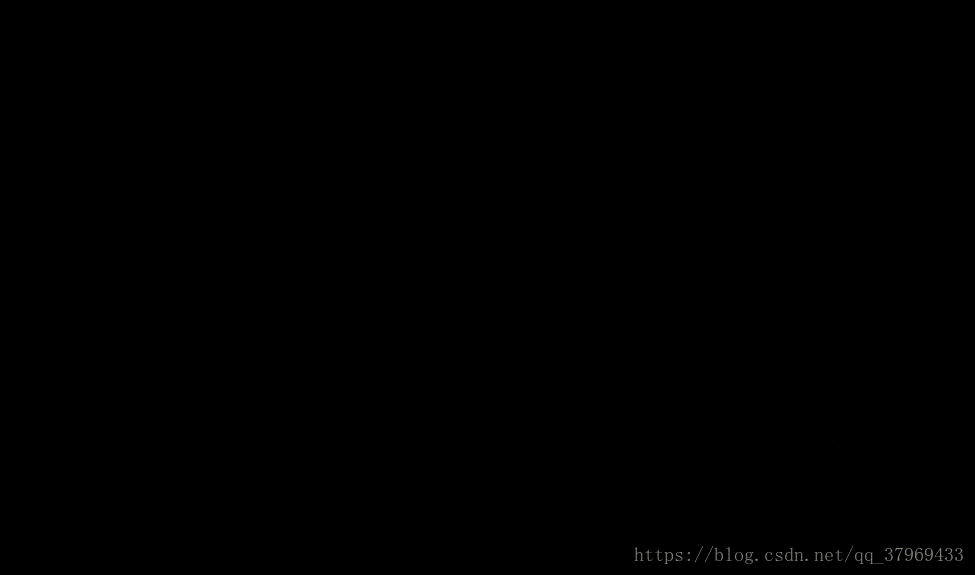
这个模拟过程即KMP算法,每次失配,S串的索引i不动,P串的索引j定位到某个数。T(n)=O(n+m),时间效率明显提高
而这“定位到某个数”,这个数就是接下来引入的next值。(实际上也就是P往后移多少位,换一种说法罢了:从上图中也可以看出,失配时固定i不变,令S[i]与P[某个数]对齐,实际上是P右移几位的另一种表达,只有为什么这么表达,当然是因为程序好写。)
开——始——划——重——点!(图对逻辑关系比较好理解,但i和j的关系对后面求next的算法好理解!)
比如,Pj处失配,绿色的是Pj,则我们可以确定P1…Pj-1是与Si…Si+j-2相对应的位置一一相等的