今天,有个哥们碰到一个问题,他有一个从库,只要是启动MySQL,CPU使用率就非常高,其中sys占比也比较高,具体可见下图。
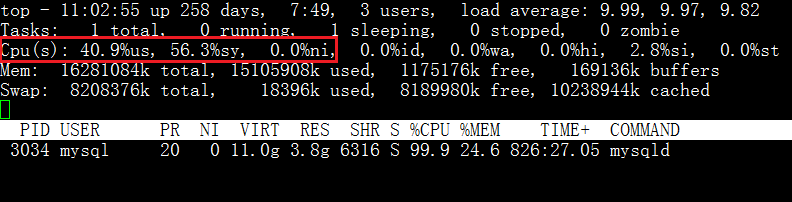
注意:他的生产环境是物理机,单个CPU,4个Core。
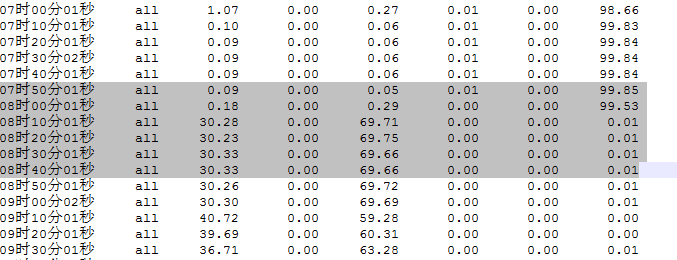
于是,他抓取了CPU的历史信息,发现CPU飙高大概是从2017年1月1日8点10分开始的。
但是这个从库的负载并不高,通过他反馈的“show processlist”和“show engine innodb statusG”的结果可以看出来
show processlist
mysql> show processlist; +-----+-------------+-----------+------+---------+-------+-----------------------------------------------------------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +-----+-------------+-----------+------+---------+-------+-----------------------------------------------------------------------------+------------------+ | 1 | system user | | NULL | Connect | 57892 | Waiting for master to send event | NULL | | 2 | system user | | NULL | Connect | 23 | Slave has read all relay log; waiting for the slave I/O thread to update it | NULL | | 108 | root | localhost | NULL | Query | 0 | NULL | show processlist | +-----+-------------+-----------+------+---------+-------+-----------------------------------------------------------------------------+------------------+ 3 rows in set (0.00 sec)
show engine innodb status
在这里,只截取了“row operations”这一部分
... -------------- ROW OPERATIONS -------------- 0 queries inside InnoDB, 0 queries in queue 1 read views open inside InnoDB Main thread process no. 3034, id 140218088003328, state: waiting for server activity Number of rows inserted 7500, updated 237481, deleted 884, read 31371340 0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s ---------------------------- ...
再次回到CPU sys态较高的事实上,一般sys较高就意味着系统在频繁调用内核代码。如果是这样的话,通过perf top就能定位系统什么操作执行得比较多。
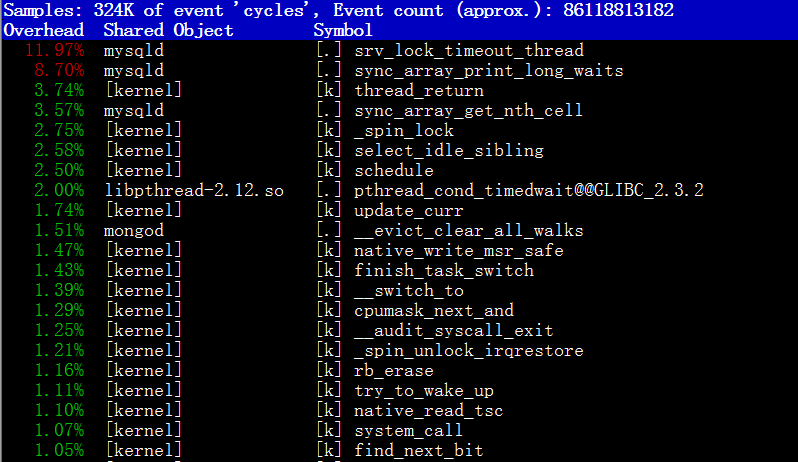
结果却显示,无任何异常操作,尤其是内核部分的,排在第一位的还是MySQL的后台进程。
一切看来是如此的诡异,MySQL本身几乎没有负载,但是CPU sys使用率较高,而且,只要关闭MySQL,CPU负载又会降下来。
最后,还是从/var/log/messages中找到些许蛛丝马迹。

联想到前几天的闰秒新闻,怀疑这个是闰秒造成的。
事实上,2012年发生的闰秒调整事件(2012年6月30日23:59:59)在全球造成了较大的影响,很多网站的服务器的CPU使用率飙升,导致网站被拖垮。
后来确认为Linux内核版本存在缺陷,在进行闰秒调整时可能会引起系统时钟服务ntpd进程死锁,并造成Linux系统重启。包括SUSE、RedHat等所有Linux kernel版本在2.6.29以下且开通了NTP服务的Linux系统都存在本次风险。如同步的时钟源对象为内部时钟源,理论上不会有此影响;如同步的时钟源对象为官方时钟源,则会存在上述风险。
该缺陷在2012年修复后,在2015年同样的闰秒调整事件中就没有造成极大的影响。
之前发生的闰秒调整导致MySQL服务器CPU sys飙高的问题,
具体可参考:
https://blog.mozilla.org/it/2012/06/30/mysql-and-the-leap-second-high-cpu-and-the-fix/
解决方法:
1. 重启服务器
2. 重新设置时间
/etc/init.d/ntpd stop; date -s now
很明显,第2种方法更实用。
重新设置时间后,CPU sys负载马上下降了。
那么,如何避免此类问题的发生呢?
简单方法:
在发生闰秒前停掉ntpd服务,发生后再开启ntpd
其它较优雅的方法,可参考:
https://www.percona.com/blog/2016/12/27/prepare-for-the-new-leap-second/
https://developers.redhat.com/blog/2015/06/01/five-different-ways-handle-leap-seconds-ntp/
PS:闰秒不是23:59:60秒么?为什么该问题发生的时间是8点。
因为23:59:60是格林威治时间,我们是东八区,所有要增加8个小时。