使用工具jTessBoxEditor-0.7(这个是在java平台下开发的,所以 它只支持java平台 ,在使用前应该先配置好java环境) tesseract
程序集(因为该程序集是在.net 2.0平台下 开发的,所以 只能支持到2.0 在使用时请注意(也可以自己去网上找别人用更高的版本编译好的)) tesseract-ocr-setup-3.01-1 使用开发语言.net 辅助工具 Visual Studio 至少能支持.net 2.0即可
首先,我们要找到自己需要做验证识别的验证码图片(因为只有图片才需要做些操作识别!!!!)或是别的需要识别的图片, 因为在要它能识别之前 我们需要做一个用于识别时用的资料库(后面叫训练集),所以 我们要收集大量的图片(尺寸大小 尽量一致,有共同的特征才方便处理) 然后找出,图片 中除了要用的内容之外 的一些共同特征 因为后面我们要把它干掉!
准备好图片之后 , 我们 打开vs 来对这些图片做初步去噪处理(除我们需要的内容外的东西都认为是噪点),我以  这种类型的验证码为例,先创建一个应用 窗体或都可以,因为这里只是对图片做一个初步的处理,我们先使用
这种类型的验证码为例,先创建一个应用 窗体或都可以,因为这里只是对图片做一个初步的处理,我们先使用
得到这个数组后,我们再使用循环遍历来处理,我们得到ma之后 再对它来做处理 首先我们如果放大的话可以看到这个图片 边上的都是白色的,而中间组成文字的是黑色, 这是我们需要的, 而其它的杂色 就有好几种 为了偷下懒呢,我就先只去这三种主要的好了,这里之所以标出了RGB值 是因为我们要用这些值来比较 颜色 再做替换的,这个我是用一个小工具来做的
另外我们一般是对一个新的图来作操作而 不是改原图 所以 我们做以下操作 因为上面三个去不尽所以 我又多找了几个,并把边上的也干成白色了 代码如下,这里是写的一个单独的方法
1 private static Bitmap cor(Bitmap ma) 2 { 3 Bitmap bi = new Bitmap(ma.Width,ma.Height); 4 for (int i = 0; i < ma.Width; i++) 5 { 6 for (int j = 0; j < ma.Height; j++) 7 { 8 if (i==0||j==0||i==ma.Width-1||j==ma.Height-1) 9 { 10 bi.SetPixel(i,j,Color.White); 11 continue; 12 } 13 Color cl = ma.GetPixel(i,j); 14 if (cl.Equals(Color.FromArgb(204, 204, 51)) || 15 cl.Equals(Color.FromArgb(153, 204, 51)) || 16 cl.Equals(Color.FromArgb(204, 255, 102)) || 17 cl.Equals(Color.FromArgb(204, 204, 204))|| 18 cl.Equals(Color.FromArgb(204, 255, 51))|| 19 cl.Equals(Color.FromArgb(102, 102, 51))) 20 { 21 bi.SetPixel(i, j, Color.White); 22 } 23 else 24 { 25 bi.SetPixel(i,j,cl); 26 } 27 } 28 29 } 30 return bi; 31 }
String [] files = Directory.GetFiles(@"E:imgyb","*.gif"); for (int i = 0; i < files.Length; i++) { Bitmap bi = Image.FromFile(files[i]) as Bitmap; cor(bi).Save(@"E:imgOK" + i + ".tiff", ImageFormat.Tiff); } MessageBox.Show("OK"); //通过这个去掉用图片处理的方法
之后我们把新的图片保存在一个文件夹里,处理完好我们第一步的工作 就做好了
那么我们开始第二步, (先确保已经搞定了java的运行环境)打开jTessBoxEditor-0.7这个工具jTessBoxEditor.jar这个文件! 然后选择我画起来那里
 然后出现这个界面打开刚刚生成的图的文件夹,把图片全选打开,然后再保存到一个文件夹里去, (可以是同一个),然后就会生成一个包含了所有图片的tiff文件
然后出现这个界面打开刚刚生成的图的文件夹,把图片全选打开,然后再保存到一个文件夹里去, (可以是同一个),然后就会生成一个包含了所有图片的tiff文件
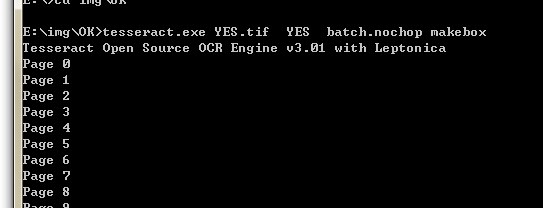
我这里是做了100个样品图来做 训练集的,然后我们再打这个文件导入到该软件中做校验(都要检验完哦!!!,如果没校验后面会出错的.出现找不到tr文件 的错 的时候你就回来看看),当我们做到这里的时候 就完成一半了接下来需要先安装好tesseract-ocr-setup-3.01-1然后 打开命令行也就是cmd
OpenFileDialog fi = new OpenFileDialog(); if (fi.ShowDialog()==DialogResult.OK) { Bitmap bi = cor((Bitmap) Image.FromFile(fi.FileName)); TesseractProcessor p = new TesseractProcessor(); p.SetPageSegMode(ePageSegMode.PSM_SINGLE_LINE); p.Init(@"E:imgOK","n",(int)eOcrEngineMode.OEM_DEFAULT); String s= p.Recognize(bi); MessageBox.Show(s); }
上面是做识别块的代码Tesseractpocessor这是前面说要用到的那个程序集的在使用使要先导入,..
欢迎 大家能共同 探讨 交流 QQ 315695792