https://www.shuxuele.com/algebra/logarithms.html
https://juejin.im/entry/593f56528d6d810058a355f4
在最简单的层面,对数解答以下问题:
多少个既定的数相乘会等于另一个数?
例子:多少个 2 相乘会等于 8?
答案:2 × 2 × 2 = 8,所以需要把 3 个 2 相乘来得到 8
所以对数是 3
怎样写
我们这样写"3个2相乘的积为8":
log2(8) = 3
所以这两个是相同的:
 |
相乘的数叫 "底",而对数的符号是 "log",所以我们可以说:
- "8的以2为底的对数是 3"
- 或 "8的log(以2为底)是 3"
- 或 "8以2为底的log是 3"
请留意,这牵涉到三个数:
- 底:相乘的数(在以上的例子的 "2")
- 多少个底相乘(3个,这就是 对数)
- 相乘起来的积(在以上的例子的 "8")
更多例子
例子: log5(625) 是多少?
问题是 "需要多少个 5 相乘,来得到 625?"
5 × 5 × 5 × 5 = 625,所以需要4 个 5
答案:log5(625) = 4
例子:log2(64) 是多少?
问题是 "需要多少个 2 相乘,来得到 64?"
2 × 2 × 2 × 2 × 2 × 2 = 64,所以需要 6 个 2
答案:log2(64) = 6
指数
指数与对数是有关联的。我们来看看。。。。。。
 |
指数的意思是用多少个数和自己相乘。 在这例子里:23 = 2 × 2 × 2 = 8 (3 个 2 乘在一起的积是 8) |
所以对数解答这样的问题:
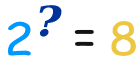
这样去解答:
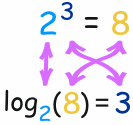
对数告诉我们指数是多少!
在这例子, "底" 是 2, "指数" 是 3:

故此,对数解答这问题:
需要什么指数
(把一个数变成另一个数)?
一般的情形是:
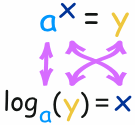
例子:log10(100) 是多少?
102 = 100
指数需要等于 2,方可把 10变成 100,所以:
log10(100) = 2
例子:log3(81) 是多少?
34 = 81
指数需要等于 4,方可把 3 变成 81,所以:
log3(81) = 4
常用对数:底为 10
有时候写对数时,底是不写的:
log(100)
通常这代表底是 10。
这叫 "常用对数"。工程师时常用常用对数。
在计算器上是 "log" 键。
意思是需要多少个 10 相乘来得到一个数。
例子:log(1000) = log10(1000) = 3
自然对数: 底为 "e"
另一个时常用的底是 e(欧拉数),大约的值是 2.71828。

这叫 "自然对数"。数学家时常用自然对数。
在计算器上是 "ln" 键。
意思是需要多少个 "e" 相乘来得到一个数。
例子:ln(7.389) = loge(7.389) ≈ 2
因为 2.718282 ≈ 7.389
可是,有时会引起混淆。。。。。。!
数学家用 "log" (而不是 "ln")来代表自然对数。这便会引起混淆:
| 例子 | 工程师演绎 | 数学家演绎 | |
|---|---|---|---|
| log(50) | log10(50) | loge(50) | 混淆 |
| ln(50) | loge(50) | loge(50) | 没混淆 |
| log10(50) | log10(50) | log10(50) | 没混淆 |
所以当你看见 "log" 时,必须找出底是多少!
对数可以是小数
以上的例子里的对数全是整数(像2或3),但对数可以是小数,像 2.5 或 6.081等等
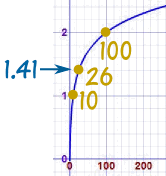
例子:log10(26)是多少?
|
把 26 打进计算器,按 log键 答案是: 1.41497。。。。。。 |
这对数的意思是 101.41497。。。。。。 = 26
(10 的指数为 1.41497。。。。。。 等于 26)
|
在图上像这样: 很漂亮的图,对不? |
 |
去对数可以是小数了解更多。
负对数
| − | 负?对数是基于乘法。 那么,乘的相反是什么?除! |
负对数的意思是需要除以一个数多少次。
可以只除一次:
例子:log8(0.125)是多少?
1 ÷ 8 = 0.125,
所以 log8(0.125) = −1
也可以除很多次:
例子:log5(0.008)是多少?
1 ÷ 5 ÷ 5 ÷ 5 = 5−3,
所以 log5(0.008) = −3
这是合情合理的
乘和除是属于同一个简单的规律。
我们来看看一些以10为底的对数:
| 数 | 多少个 10 | 对数(以10为底) | ||
|---|---|---|---|---|
 |
。。。等等。。。 | |||
| 1000 | 1 × 10 × 10 × 10 | log10(1000) | = 3 | |
| 100 | 1 × 10 × 10 | log10(100) | = 2 | |
| 10 | 1 × 10 | log10(10) | = 1 | |
| 1 | 1 | log10(1) | = 0 | |
| 0.1 | 1 ÷ 10 | log10(0.1) | = −1 | |
| 0.01 | 1 ÷ 10 ÷ 10 | log10(0.01) | = −2 | |
| 0.001 | 1 ÷ 10 ÷ 10 ÷ 10 | log10(0.001) | = −3 | |
| 。。。等等。。。 | ||||
留心看这列表,注意到正、零和负对数全都是属于同一个(相当简单的)规律。
英语 "Logarithm"
对数的英语 "Logarithm" 为苏格兰数学家约翰·奈皮尔(公元1550-1617)所创,源自希腊字 logos,意思是"比例或字";而 arithmos 的意思是 "数"。。。。。。合成一个字就是 "比例数"!
预先知道算法的复杂度是一回事,了解其后的原理是另一件事情。
不管你是计算机科班出身还是想有效解决最优化问题,如果想要用自己的知识解决实际问题,你都必须理解时间复杂度。
先从简单直观的 O(1) 和 O(n) 复杂度说起。O(1) 表示一次操作即可直接取得目标元素(比如字典或哈希表),O(n) 意味着先要检查 n 个元素来搜索目标,但是 O(log n) 是什么意思呢?
你第一次听说 O(log n) 时间复杂度可能是在学二分搜索算法的时候。二分搜索一定有某种行为使其时间复杂度为 log n。我们来看看是二分搜索是如何实现的。
因为在最好情况下二分搜索的时间复杂度是 O(1),最坏情况(平均情况)下 O(log n),我们直接来看最坏情况下的例子。已知有 16 个元素的有序数组。
举个最坏情况的例子,比如我们要找的是数字 13。

十六个元素的有序数组
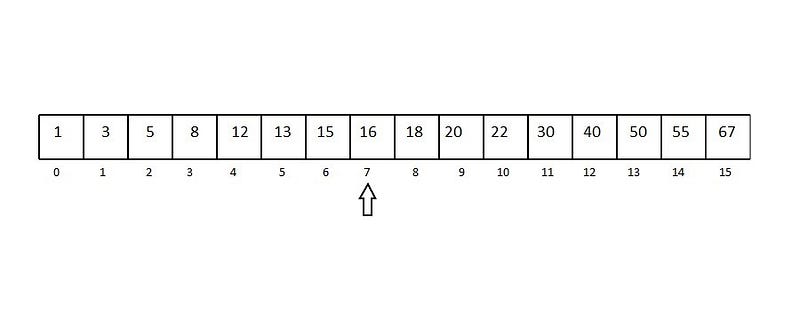
选中间的元素作为中心点(长度的一半)
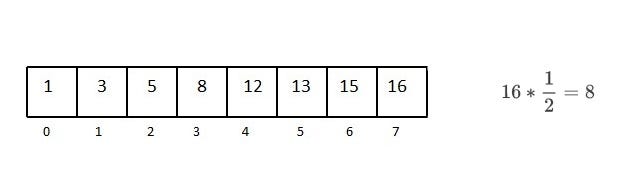
13 小于中心点,所以不用考虑数组的后一半
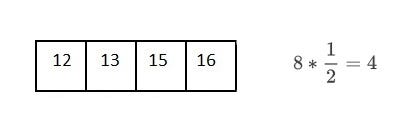
重复这个过程,每次都寻找子数组的中间元素
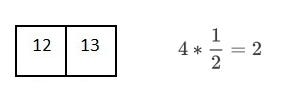

每次和中间元素比较都会使搜索范围减半。
所以为了从 16 个元素中找到目标元素,我们需要把数组平均分割 4 次,也就是说,

简化后的公式
类似的,如果有 n 个元素,

归纳一下

分子和分母代入指数

等式两边同时乘以 2^k

最终结果
现在来看看「对数」的定义:
为使某数(底数)等于一给定数而必须取的乘幂的幂指数。
也就是说可以写成这种形式

对数形式
所以 log n 的确是有意义的,不是吗?没有其他什么可以表示这种行为。
就这样吧,我希望我讲得这些你都搞懂了。在从事计算机科学相关的工作时,了解这类知识总是有用的(而且很有趣)。说不定就因为你知道算法的原理,你成了小组里能找出问题的最优解的人呢,谁知道呢。祝好运!
问题:
最近有好几学生问我,无论是计算机算法概论、还是数据结构书中,
关于算法的时间复杂度很多都用包含O(logN)这样的描述,但是却没有明确说logN的底数究竟是多少。
解答:
算法中log级别的时间复杂度都是由于使用了分治思想,这个底数直接由分治的复杂度决定。
如果采用二分法,那么就会以2为底数,三分法就会以3为底数,其他亦然。
不过无论底数是什么,log级别的渐进意义是一样的。
也就是说该算法的时间复杂度的增长与处理数据多少的增长的关系是一样的。
我们先考虑O(logx(n))和O(logy(n)),x!=y,我们是在考虑n趋于无穷的情况。
求当n趋于无穷大时logx(n)/logy(n)的极限可以发现,极限等于lny/lnx,也就是一个常数,
也就是说,在n趋于无穷大的时候,这两个东西仅差一个常数。
所以从研究算法的角度log的底数不重要。
最后,结合上面,我也说一下关于大O的定义(算法导论28页的定义),
注意把这个定义和高等数学中的极限部分做比较,
显然可以发现,这里的定义正是体现了一个极限的思想,
假设我们将n0取一个非常大的数字,
显然,当n大于n0的时候,我们可以发现任意底数的一个对数函数其实都相差一个常数倍而已。
所以书上说写的O(logn)已经可以表达所有底数的对数了,就像O(n^2)一样。
没有非常严格的证明,不过我觉得这样说比较好理解,如果有兴趣证明,完全可以参照高数上对极限趋于无穷的证明。
由于平时接触算法比较少,今天看资料看到了o(1),都不知道是什么意思,百度之后才知道是什么意思。
描述算法复杂度时,常用o(1), o(n), o(logn), o(nlogn)表示对应算法的时间复杂度,是算法的时空复杂度的表示。不仅仅用于表示时间复杂度,也用于表示空间复杂度。
O后面的括号中有一个函数,指明某个算法的耗时/耗空间与数据增长量之间的关系。其中的n代表输入数据的量。
比如时间复杂度为O(n),就代表数据量增大几倍,耗时也增大几倍。比如常见的遍历算法。
再比如时间复杂度O(n^2),就代表数据量增大n倍时,耗时增大n的平方倍,这是比线性更高的时间复杂度。比如冒泡排序,就是典型的O(n^2)的算法,对n个数排序,需要扫描n×n次。
再比如O(logn),当数据增大n倍时,耗时增大logn倍(这里的log是以2为底的,比如,当数据增大256倍时,耗时只增大8倍,是比线性还要低的时间复杂度)。二分查找就是O(logn)的算法,每找一次排除一半的可能,256个数据中查找只要找8次就可以找到目标。
O(nlogn)同理,就是n乘以logn,当数据增大256倍时,耗时增大256*8=2048倍。这个复杂度高于线性低于平方。归并排序就是O(nlogn)的时间复杂度。
O(1)就是最低的时空复杂度了,也就是耗时/耗空间与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变。 哈希算法就是典型的O(1)时间复杂度,无论数据规模多大,都可以在一次计算后找到目标(不考虑冲突的话)
本篇文章整理自:https://www.cnblogs.com/my_life/articles/11510146.html