前言
本文所写的,偏重于架构师的内容,所以阅读的小伙伴,要有综合的一些能力,否则,你可能会被其中的计算给弄晕,不过既然,阅读我的文章嘛,都是从基础开始写起,所以还是很好读的。
本文要讨论的话题是,当我搭建一个kafka集群的时候,我们需要考虑的问题。
不能张口就来,我需要什么什么配置的机器之类的,那是耍流氓,我们要考虑的有理有据才可以对吧。
方案背景
假设我们要搭建一个每天要承载10亿数据的kafka集群。一天24小时,晚上12点到凌晨8点几乎没多少数据,使用二八法则估计,也就是80%的数据(8亿)会在16个小时涌入,而且8亿的80%的数据(6.4亿)会在这16个小时的20%时间(3小时)涌入。QPS计算公式=640000000÷(3_60_60)=6万,也就是说高峰期的时候,咱们的kafka集群要扛住眉每妙6万的并发。
磁盘空间计算,每天10亿数据,每条50kb,也就是46T的数据,保存2副本,462=92T,保留最近三天的数据,故需要923=276T
QPS角度
部署kafka,Hadoop,mysql,大数据核心分布式系统,一般建议大家直接采用物理机,不建议用一些低配置的虚拟机,QPS这个东西,不能说你只要6万QPS,你的集群就刚好支撑6万QPS就可以了,加入说你只要支撑6WQPS,2台物理机绝对够了,单台物理机部署kafka支撑个几万QPS是没问题的,但是,尽量让高峰QPS控制在集群能承载的总QPS的39% 左右,也就是总QPS为20万~30万才是安全的,所以大体上来说,需要5到7台物理机,每台要求在每妙几万条数据就可以了。
磁盘角度
磁盘数量,我们现在需要5台物理机,需要存贮276T的数据,所以大概需要每台存贮60T的数据,公司配置一般是11块盘,这样的话,一个盘7T就搞定了。
SAS盘还是SSD盘
我们都知道ssd盘比sas盘要块,但是他快的是随机读写能力,那kafka呢?kafka是顺序写入的,所以这个时候,ssd盘的作用就不是很大,所以,我们是可以采用sas盘的,也就是机械硬盘的,当然了,能用ssd盘更好。
内存角度
前提预知条件,kafka写入数据是先写到缓存中,也就是os cache中,然后再写入磁盘中。
kafka自身的jvm是用不了过多的对内存的,因为kafaka设计就是规避掉用jvm对象来保存数据,避免频繁fullgc导致的问题,所以一般kafka自身的jvm堆内存,分配个10G左右就够了,剩下的内存全部都留给os cache。
那么服务器需要多少内存呢?我们估算一下,大概有100个topic,所以要保证有100个topic的leader partition的数据在os cache,按照一个topic有5个分区,总共有500个partition,每个partition的大小是1个G,按照两个副本,也就是1千G,如果都要驻留在内存中的话,需要1000G的内存,现在有5台服务器,每个平均分一下,就是200G,当然了,并不是所有的数据都需要留在内存,所以按照25% 的计算就行了,也就是我们需要50G的内存,然后再留给jvm为10G,比较接近的,我们可以选择64G的内存服务器就可以了,当然了,内存肯定是越大也好,比如我们选择128G的。
cpu角度
cup的规划,主要是看你的线程有多少个线程。
所以到这里,我们来插播一个关于kafka的网络传输过程。
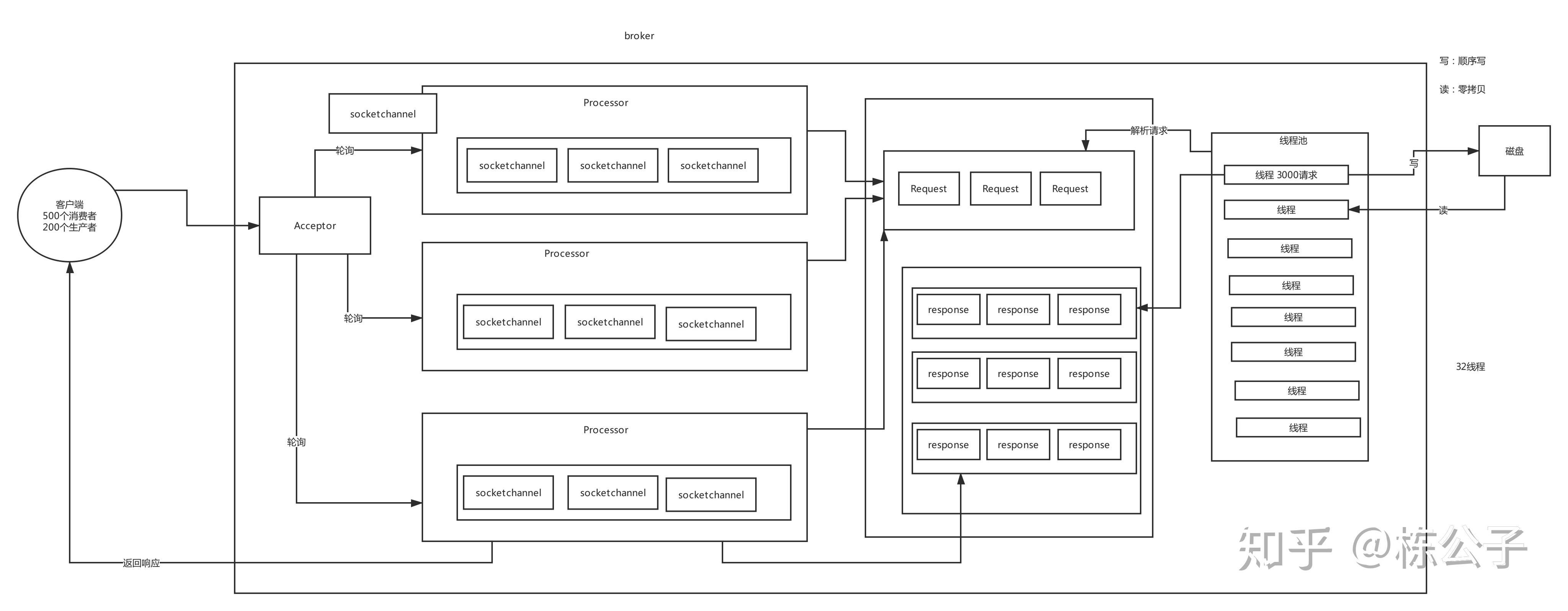
这个图片字体看起来比较小,但是你可以把它下载下来看,主要说一下他的过程,这个过程是kafka及其核心的过程。
首先客户端有500个消费者,200个生产者,那么他首先会将这些请求发送给Acceptor,然后acceptor,这些请求叫socketchannel,然后这些socketchannel就会被发送给processor,默认情况下,有三个proccessor,然后这些proccessor就会将请求发送给request队列,这个时候后面默认有8个线程池来请求这些request队列里面的内容,这些线程池就会用零拷贝的方式直接写入到磁盘中,当然了,零拷贝本身也实现写入os cache,然后,线程池处理完毕,就会发送给reponse队列,告诉客户端写入成功了,当然了,这个成功,我们再写代码的时候会有三种配置,后面我会写通过代码的方式配置的文章的时候会提到这个参数配置的。
那么我们在搭建kafka集群的时候,会关注这样两个参数,分别为
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
num.network,threads=3这个参数就是processor,
num.io.threads=8,这个就是线程池。
我们在搭建集群的时候,建议将它扩大,比如num.network.threads这个可以搞成6个或者9个,num.io.threads=8这个我们可以将它搞成24个,或者32个,这样子,线程一下就可以增大很多倍。
有了这个知识之后,我们就可以来具体的说cpu了。
我们来算一算这个线程数,首先会有9*32=288,在加上定期定期清理7天前数据的线程,加起来有几百个了,这样子,根据经验4个Cpu core,一般来说支持个10几个线程的话,在高峰期是完全打满了,所以我们选择8个cpu core,这样子就比较宽裕支持个几十个线程繁忙的工作,所以,我们采用16核的,当然了,采用32 cpu core更好了。
网卡角度
现在的网基本上就是千兆ka,还有万兆网卡,kafka集群之间,broker和broker之间是会做数据同步的,因为leader要同步数据到follwer上面去,所以不同服务器之间的传输比较频繁,根据之前测算的qps计算,每妙有6万,按照每天请求处理1000个请求,每个请求50kb,大概是488M,当然了,我们还有副本,所以要有两倍,于是大概是就是976M/s的网路带宽。于是如果在高峰期的话,采用千兆网络,就会有压力的。
于是经过上面的分析,我们大概得出结论。
配置总结
5台物理机
硬盘:11 (sas) * 7T,7200转
内存:64G/128G,jvm分配10G,剩余的给os cache
cpu:16核/32核
网络:千兆网路/万兆网络