转自:https://www.seoxiehui.cn/article-45186-1.html
需求:
为满足用户标签的统计需求,小灰利用Mysql设计了如下的表结构,每一个维度的标签都对应着Mysql表的一列:要想统计所有90后的程序员该怎么做呢




两个月之前——





为满足用户标签的统计需求,小灰利用Mysql设计了如下的表结构,每一个维度的标签都对应着Mysql表的一列:

要想统计所有90后的程序员该怎么做呢?
用一条求交集的SQL语句即可:
Select count(distinct Name) as 用户数 from table whare age = '90后' and Occupation = '程序员' ;
要想统计所有使用苹果手机或者00后的用户总合该怎么做?
用一条求并集的SQL语句即可:
Select count(distinct Name) as 用户数 from table whare Phone = '苹果' or age = '00后' ;

两个月之后——




———————————————





1. 给定长度是10的bitmap,每一个bit位分别对应着从0到9的10个整型数。此时bitmap的所有位都是0。

2. 把整型数4存入bitmap,对应存储的位置就是下标为4的位置,将此bit置为1。

3. 把整型数2存入bitmap,对应存储的位置就是下标为2的位置,将此bit置为1。

4. 把整型数1存入bitmap,对应存储的位置就是下标为1的位置,将此bit置为1。

5. 把整型数3存入bitmap,对应存储的位置就是下标为3的位置,将此bit置为1。

要问此时bitmap里存储了哪些元素?显然是4,3,2,1,一目了然。
Bitmap不仅方便查询,还可以去除掉重复的整型数。






1. 建立用户名和用户ID的映射:

2. 让每一个标签存储包含此标签的所有用户ID,每一个标签都是一个独立的Bitmap。

3. 这样,实现用户的去重和查询统计,就变得一目了然:





1. 如何查找使用苹果手机的程序员用户?

2. 如何查找所有男性或者00后的用户?









一周之后......




我们以上一期的用户数据为例,用户基本信息如下。按照年龄标签,可以划分成90后、00后两个Bitmap:

用更加形象的表示,90后用户的Bitmap如下:

这时候可以直接求得非90后的用户吗?直接进行非运算?

显然,非90后用户实际上只有1个,而不是图中得到的8个结果,所以不能直接进行非运算。


同样是刚才的例子,我们给定90后用户的Bitmap,再给定一个全量用户的Bitmap。最终要求出的是存在于全量用户,但又不存在于90后用户的部分。

如何求出呢?我们可以使用异或操作,即相同位为0,不同位为1。


















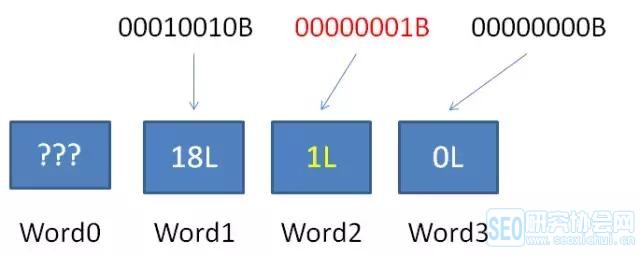















25769803776L = 11000000000000000000000000000000000B
8589947086L = 1000000000000000000011000011001110B






1.解析Word0,得知当前RLW横跨的空Word数量为0,后面有连续3个普通Word。
2.计算出当前RLW后方连续普通Word的最大ID是 64 X (0 + 3) -1 = 191。
3. 由于 191 < 400003,所以新ID必然在下一个RLW(Word4)之后。
4.解析Word4,得知当前RLW横跨的空Word数量为6247,后面有连续1个普通Word。
5.计算出当前RLW(Word4)后方连续普通Word的最大ID是191 + (6247 + 1)X64 = 400063。
6.由于400003 < 400063,因此新ID 400003的正确位置就在当前RLW(Word4)的后方普通Word,也就是Word5当中。
最终插入结果如下:





官方说明如下:
* Though you can set the bits in any order (e.g., set(100), set(10), set(1),* you will typically get better performance if you set the bits in increasing order (e.g., set(1), set(10), set(100)).* * Setting a bit that is larger than any of the current set bit* is a constant time operation. Setting a bit that is smaller than an * already set bit can require time proportional to the compressed* size of the bitmap, as the bitmap may need to be rewritten.

几点说明:
1. 该项目最初的技术选型并非Mysql,而是内存数据库hana。本文为了便于理解,把最初的存储方案写成了Mysq数据库。
1.文中介绍的Bitmap优化方法在一定程度上做了简化,源码中的逻辑要复杂得多。比如对于插入数据400003的定位,和实际步骤是有出入的。
2.如果同学们有兴趣,可以亲自去阅读源码,甚至是尝试实现自己的Bitmap算法。虽然要花不少时间,但这确实是一种很好的学习方法。
EWAHCompressedBitmap对应的maven依赖如下:
<dependency> <groupId>com.googlecode.javaewah</groupId> <artifactId>JavaEWAH</artifactId> <version>1.1.0</version> </dependency>