前言:
我们常见的有数据结构有三种结构:1、数组结构 2、链表结构 3、哈希表结构。
1. 数组结构
public static void main(String[] args) {
// 数组:采用一段连续的存储单元来存储数据。
// 特点:指定下标0(1) 删除插入0(N) 查询快 插入慢
Integer[] integers = new Integer[10];
integers[0] = 0;
integers[1] = 1;
integers[2] = 2;
System.out.println(integers[4]);
}
数组结构: 存储区间连续、内存占用严重、空间复杂度大
优点:随机读取和修改效率高,原因是数组是连续的(随机访问性强,查找速度快)
缺点:插入和删除数据效率低,因插入数据,这个位置后面的数据在内存中都要往后移动,且大小固定不易动态扩展。
2. 链表结构
public class Node {
private Node next;
private Object data;
public Node(Object data) {
this.data = data;
}
// 链表:一种物理存储单元上非连续,非顺序的存储结构
// 特点:插入,删除时间复杂度0(1) 查找遍历时间复杂度0(N) 插入快 查找慢
public static void main(String[] args) {
Node node = new Node("张三");
node.next = new Node("李四");
System.out.println(node.data);
System.out.println(node.next.data);
}
}
链表结构:存储区间离散、占用内存宽松、空间复杂度小
优点:插入删除速度快,内存利用率高,没有固定大小,扩展灵活
缺点:不能随机查找,每次都是从第一个开始遍历(查询效率低)
3. HashMap的底层实现原理
HashMap的默认初始容量:16 必须是2的幂次方
HashMap的默认加载因子:0.75
当我们创建一个HashMap时,默认为其指定了容量大小。大小为16。可以理解成16个 “桶”。每个桶存的就是 K-V 的数据。
在put(key,value)元素时,会根据key的值得到他的hashCode值【hashCode是一个int类型 -2147483648——2147483647 】。在得到hashCode值后,怎么确定把这个元素放到哪个桶呢?
HashMap采用了一种算法, index = (n - 1) & hash n:表示初始容量 hash:该元素key的hashCode值 index:表示得出的该元素要存放到哪个桶的位置。
为什么初始容量必须是 2的幂次方呢?
下面我们以值为“book”的Key来演示整个过程:
1.计算book的hashcode(ps: "book".hashCode() ),结果为十进制的3029737,二进制的101110001110101110 1001。
2.假定HashMap长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111。
3.把以上两个结果做与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9。
可以说,Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。
总之一句话,反正初始容量必须是2的幂次方,人家这个算法才能生效。
那么,既然是2^n ,为啥一定要是16呢?为什么不能是4、8或者32呢?
关于这个默认容量的选择,JDK并没有给出官方解释。
这应该就是个经验值(Experience Value),既然一定要设置一个默认的2^n 作为初始值,那么就需要在效率和内存使用上做一个权衡。这个值既不能太小,也不能太大。
太小了就有可能频繁发生扩容,影响效率。太大了又浪费空间,不划算。
所以,16就作为一个经验值被采用了。
初始容量是不是不能自动变呢?
初始容量是会自动变的,如果16个 “桶” 都占满了,一直在这16个桶里面操作,难免会影响一定的效率。
初始容量会在桶被占用了 初始容量*默认加载因子=12 个桶数时进行扩容,扩容一倍的大小。
Hashmap的扩容需要满足两个条件:当前数据存储的数量(即size())大小必须大于等于阈值;当前加入的数据是否发生了hash冲突。 //============来源于网上的说法,不确定。=============//
因为上面这两个条件,所以存在下面这些情况
(1)、就是hashmap在存值的时候(默认大小为16,负载因子0.75,阈值12),可能达到最后存满16个值的时候,再存入第17个值才会发生扩容现象,因为前16个值,每个值在底层数组中分别占据一个位置,并没有发生hash碰撞。
(2)、当然也有可能存储更多值(超多16个值,最多可以存26个值)都还没有扩容。原理:前11个值全部hash碰撞,存到数组的同一个位置(这时元素个数小于阈值12,不会扩容),后面所有存入的15个值全部分散到数组剩下的15个位置(这时元素个数大于等于阈值,但是每次存入的元素并没有发生hash碰撞,所以不会扩容),前面11+15=26,所以在存入第27个值的时候才同时满足上面两个条件,这时候才会发生扩容现象。
在确认了存在哪个位置之后,我们就可以把该元素存放到相应的桶里面。如果存在某2个或多个元素的key经过算法后,他们要存放到桶的位置相同怎么处理呢?
当出现这种情况,我们称为Hash碰撞。
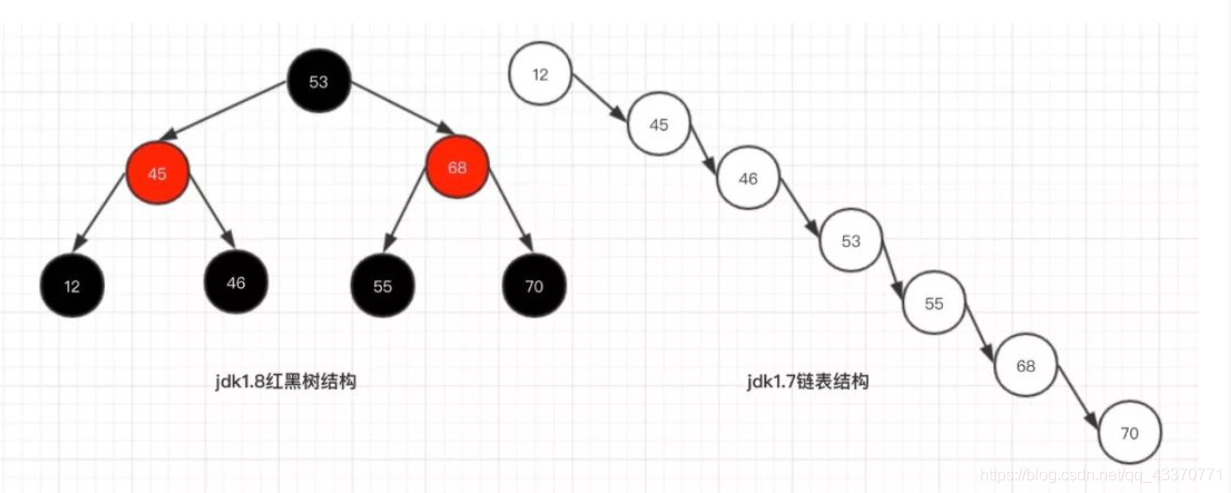
在JDK1.8之前 ========链表来解决的=========
在JDK1.8之后 ========链表个数达到默认值8时将其改为红黑树=========