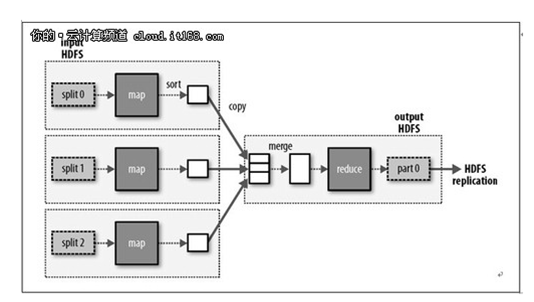
Map-Reduce工作原理

1 client run job
2 get new job ID
3 copy job resources
4 submit job
5 initialize job
6 retrieve input splits
7 heartbeat (return task)
8 retrieve job resource
9 lunch
10 run
JobClient的runJob()方法是用于新建JobClient实例和调用其submitJob()方法。提交作业后,runJob()将每秒轮询作业的进度,如果发现与上一个记录不同,便把报告显示到控制台。作业完成后,如果成功,就显示作业计数器。否则,导致作业失败的错误会被记录到控制台。
1、向jobtracker请求一个新的作业ID(通过Jobtracker的getNewJobId())
2、检查作业的输出说明。比如,如果没有指定输出目录或者它已经存在,作业就不会被提交,并有错误返回给MapReduce程序。
3、计算作业的输出划分。如果划分无法计算,比如因为输入路径不存在,作业就不会被提交,并有错误返回给MapReduce程序。
4、将运行作业所需要的资源---包括作业的JAR文件、配置文件和计算所得的输入划分--复制到一个以作业ID号命名的目录中jobtracker的文件系统。作业JAR的副本较多(由mapred.submit.replication 属性控制,默认为10),如此一来,在tasktracker运行作业任务时,集群能为它们提供许多副本进行访问。(步骤3)
5、告诉jobtracker作业准备执行(通过调用JobTracker的submitJob()方法)(步骤4)
6、Jobtracker接受到对其submitJob()方法调用后,会把此调用放入一个内部的队列中,交由作业调度器进行调度,并对其进行初始化。初始化包括创建一个代表该正在运行的作业的对象,它封装任务和记录信息,以便跟踪任务的状态和进程(步骤5)
7、要创建运行任务列表,作业调度器首先从共享文件系统中获取JobClient已经计算好的输入划分信息(步骤6)然后为每个划分创建一个map任务。创建的reduce任务的数量由JobConf的mapred.reduce.tasks属性决定,它是用setNumReduceTasks()方法来设定的,然后调度器便创建这么多reduce任务来运行。任务在此时指定ID号。
8、TaskTraker 执行一个简单的循环,定期发送心跳(heartbeat)方法调用Jobtracker。心跳方法告诉jobtracker,tasktracker是否存活,同时也充当两者之间的消息通道。作业心跳方法调用的一部分,tasktracker会指明它是否已经准备运行新的任务,如果是,jobtracker会为他分配一个任务,并使用心跳方法的返回值与tasktracker进行通信(步骤7)
9、现在,tasktracker已经被分配了任务,下一步是运行任务。首先,它本地化作业的JAR文件,将它从共享文件系统复制到tasktracker所在的文件系统。同时,将应用程序所需要的全部文件从分布式缓存复制到本地磁盘。然后,为任务新建一个本地工作目录,并把JAR文件中的内容解压到这个文件夹下。第三步,新建一个TaskRunner实例来运行任务。
TaskRunner启动一个新的Java虚拟机(步骤9)来运行每个任务(步骤10),使得用户第一的map和reduce函数的任何缺陷都不会影响tasktracker(比如导致它崩溃或者挂起)。但在不同的任务之间重用JVM还是可能的。
子进程通过 umbilical 接口与父进程进行通信。它每隔几秒便告知父进程它的进度,直到任务完成。
Definition
JobClient
用户端通过JobClient类将应用已经配置参数打包成jar文件存储到hdfs
并把路径提交到Jobtracker,然后由JobTracker创建每一个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行
JobTracker
是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行。
TaskTracker
是运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。
Notice
JobTracker 对应于 NameNode
TaskTracker 对应于 DataNode
DataNode 和NameNode 是针对数据存放来而言的
JobTracker和TaskTracker是对于MapReduce执行而言的
TaskTracker都需要运行在HDFS的DataNode上
工作分工
JobTracker
与客户端的通信:接收客户端的命令,如提交job,kill job。
接收TaskTracker心跳,为TT分配Task任务队列,更新task状态,监测TT的状态。
内部处理操作:
对job进行初始化,分解成多个map,reduce task任务。
对许多job进行排列,按照某种调度算法排列。
更新task的状态。
更新job的状态。
TaskTracker
作为工作节点来负责执行JobTracker节点分配的Map/Reduce任务
与JobTracker节点进行频繁的交互(心跳)获取作业的任务并负责在本地执行
与其它的TaskTracker节点交互来协同完成同一个作业
对该节点上的任务、作业、JVM实例以及内存进行管理

TaskTracker节点内部的服务组件不仅用来为TaskTracker节点、客户端提供服务,而且还负责向TaskTracker节点请求服务,这一类组件主要包括HttpServer、TaskReportServer、JobClient三大组件。
1.HttpServer
TaskTracker节点在其内部使用Jetty Web容器来开启http服务,这个http服务一是用来为客户端提供Task日志查询服务,二是用来提供数据传输服务,即在执行Reduce任务时是通过TaskTracker节点提供的该http服务来获取属于自己的map输出数据。这里需要详细介绍的是与该服务相关的配置参数,集群管理者可以通过TaskTracker节点的配置文件来配置该服务地址和端口号,对应的配置项为:mapred.task.tracker.http.address。同时,为了能够灵活的控制该该服务的吞吐量,管理者还可以设置该http服务的内部工作线程数量,对应的配置为:tasktracker.http.threads。
2.Task Reporter
TaskTracker节点在接收到JobTracker节点发送过来的Map/Reduce任务之后,会把它们交给JVM实例来执行,而自己则需要收集这些任务的执行进度信息,这就使得Task在JVM实例中执行的时候需要不断地向TaskTracker节点报告当前的执行情况。虽然TaskTracker节点和JVM实例在同一台机器上,但是它们之间的进程通信却是通过网络I/O来完成的(此处并不讨论这种通信方式的性能),也就是TaskTracker节点在其内部开启一个端口来专门为任务实例提供进度报告服务。该服务地址可以通过配置项mapred.task.tracker.report.address来设置,而服务内部的工作线程的数量取2倍于该TaskTracker节点上的Map/Reduce Slot数量中的大者。该服务接口如下:
java] view plaincopyprint?
interface TaskUmbilicalProtocol extends VersionedProtocol {
public static final long versionID = 16L;
从TaskTracker节点上获取一个属于该JVM实例的任务
JvmTask getTask(JVMId jvmId) throws IOException;
向TaskTracker节点报告当前任务实例执行的进度及状态信息
boolean statusUpdate(TaskAttemptID taskId, TaskStatus taskStatus)
throws IOException, InterruptedException;
向TaskTracker节点报告当前任务实例发生异常的原因
void reportDiagnosticInfo(TaskAttemptID taskid, String trace) throws IOException;
void reportNextRecordRange(TaskAttemptID taskid, SortedRanges.Range range)
throws IOException;
boolean ping(TaskAttemptID taskid) throws IOException;
向TaskTracker节点发送一个心跳包,以此来告知TaskTracker节点自己还在正常执行
void done(TaskAttemptID taskid) throws IOException;
向TaskTracker节点发送任务提交预约请求
void commitPending(TaskAttemptID taskId, TaskStatus taskStatus)
throws IOException, InterruptedException;
向TaskTracker节点询问自己是否能够提交任务
boolean canCommit(TaskAttemptID taskid) throws IOException;
向TaskTracker节点报告获取一个Map输出失败
void shuffleError(TaskAttemptID taskId, String message) throws IOException;
向TaskTracker节点报告执行一个任务实例是发送文件系统的错误
void fsError(TaskAttemptID taskId, String message) throws IOException;
向TaskTracker节点报告一个任务实例执行失败
void fatalError(TaskAttemptID taskId, String message) throws IOException;
从TaskTracker节点获取所属作业刚刚完成的Map任务
MapTaskCompletionEventsUpdate getMapCompletionEvents(JobID jobId,
int fromIndex,
int maxLocs,
TaskAttemptID id)
throws IOException;
}
interface TaskUmbilicalProtocol extends VersionedProtocol { public static final long versionID = 16L; /** * 从TaskTracker节点上获取一个属于该JVM实例的任务 JvmTask getTask(JVMId jvmId) throws IOException; /** * 向TaskTracker节点报告当前任务实例执行的进度及状态信息 */ boolean statusUpdate(TaskAttemptID taskId, TaskStatus taskStatus) throws IOException, InterruptedException; /** * 向TaskTracker节点报告当前任务实例发生异常的原因 */ void reportDiagnosticInfo(TaskAttemptID taskid, String trace) throws IOException; /** * */ void reportNextRecordRange(TaskAttemptID taskid, SortedRanges.Range range) throws IOException; /** */ boolean ping(TaskAttemptID taskid) throws IOException; /** * 向TaskTracker节点发送一个心跳包,以此来告知TaskTracker节点自己还在正常执行 */ void done(TaskAttemptID taskid) throws IOException; /** * 向TaskTracker节点发送任务提交预约请求 */ void commitPending(TaskAttemptID taskId, TaskStatus taskStatus) throws IOException, InterruptedException; /** * 向TaskTracker节点询问自己是否能够提交任务 */ boolean canCommit(TaskAttemptID taskid) throws IOException; /** * 向TaskTracker节点报告获取一个Map输出失败 */ void shuffleError(TaskAttemptID taskId, String message) throws IOException; /** * 向TaskTracker节点报告执行一个任务实例是发送文件系统的错误 */ void fsError(TaskAttemptID taskId, String message) throws IOException; /** * 向TaskTracker节点报告一个任务实例执行失败 */ void fatalError(TaskAttemptID taskId, String message) throws IOException; /** * 从TaskTracker节点获取所属作业刚刚完成的Map任务 */ MapTaskCompletionEventsUpdate getMapCompletionEvents(JobID jobId, int fromIndex, int maxLocs, TaskAttemptID id) throws IOException; } 3.JobClient
TaskTracker节点与JobTracker节点进行通信的客户端组件,该组件负责为TaskTracker节点提供与系统有关的查询服务,该客户端的API为:
[java] view plaincopyprint?
interface InterTrackerProtocol extends VersionedProtocol {
public static final long versionID = 25L;
public final static int TRACKERS_OK = 0;
public final static int UNKNOWN_TASKTRACKER = 1;
向JobTracker节点发送心跳跑同时报告自己当前的状态及任务实例执行的进度信息等,并且顺便获取分配的新任务实例
HeartbeatResponse heartbeat(TaskTrackerStatus status,
boolean restarted,
boolean initialContact,
boolean acceptNewTasks,
short responseId)
throws IOException;
获取集群依赖的文件系统的类型
public String getFilesystemName() throws IOException;
向JobTracker节点报告TaskTracker节点出错的原因
public void reportTaskTrackerError(String taskTracker,
String errorClass,
String errorMessage) throws IOException;
从JobTracker节点获取某一作业最近的任务完成事件
TaskCompletionEvent[] getTaskCompletionEvents(JobID jobid, int fromEventId
int maxEvents) throws IOException;
获取集群的系统目录
public String getSystemDir();
从JobTracker节点获取其提供该服务的版本号
public String getBuildVersion() throws IOException;
}
interface InterTrackerProtocol extends VersionedProtocol { public static final long versionID = 25L; public final static int TRACKERS_OK = 0; public final static int UNKNOWN_TASKTRACKER = 1; /** * 向JobTracker节点发送心跳跑同时报告自己当前的状态及任务实例执行的进度信息等,并且顺便获取分配的新任务实例 */ HeartbeatResponse heartbeat(TaskTrackerStatus status, boolean restarted, boolean initialContact, boolean acceptNewTasks, short responseId) throws IOException; /** * 获取集群依赖的文件系统的类型 */ public String getFilesystemName() throws IOException; /** * 向JobTracker节点报告TaskTracker节点出错的原因 */ public void reportTaskTrackerError(String taskTracker, String errorClass, String errorMessage) throws IOException; /** * 从JobTracker节点获取某一作业最近的任务完成事件 */ TaskCompletionEvent[] getTaskCompletionEvents(JobID jobid, int fromEventId , int maxEvents) throws IOException; /** * 获取集群的系统目录 */ public String getSystemDir(); /** * 从JobTracker节点获取其提供该服务的版本号 */ public String getBuildVersion() throws IOException; }
管理组件
1.JVM Manager
TaskTracker节点对任务实例执行的核心就是将其交由一个的合适的JVM进程来负责执行,这里要强调的是JVM实例和TaskTracker节点是在同一台机器上的两个不同的进程,因此运行在每一个TaskTracker节点上的JVM实例是有限制的,同时又两类JVM实例,一类用来运行Map任务,另一类则用来运行Reduce任务。这两类JVM实例的最大数量可分别由配置文件中的mapred.tasktracker.map.tasks.maximum、mapred.tasktracker.reduce.task.maximum项来设置。TaskTracker节点利用JvmManager来管理该节点上所有的JVM实例,一方面它要保证运行在该TaskTracker节点上的各类JVM实例数量不能超过对应的上限值;另一方面还要负责分配合适的任务实例到空闲的JVM上执行,这是因为频繁地关闭/开始JVM线程是很耗时间的,而且一个JVM实例只能运行同一个作业的Map/Reduce任务。
2.Memory Manager
Hadoop集群的成本低主要是因为它部署在普通的低端PC上,以至于集群中的每一个节点的物理资源是有限的,特别是内存资源。任何作业的任务在TaskTracker节点上执行时都或多或少地需要一定的内部,但不同类型的作业需要的内存量是不一样的。很明显,仅仅通过开启一个JVM实例时设置该进程可使用的内存的上限值是不准确的、不够优化的,所以TaskTracker节点通过TaskMemoryManager来统计该节点当前内存的使用情况,并将其报告给JobTracker节点,JobTracker节点就可以根据该TaskTracker节点内存的剩余为其分配合适的任务了。
3.Task/Job Manager
TaskTracker节点通过Task、Job两个级别来共同的管理正在其上运行的任务,本来在Task级别管理任务是足以的,但为什么还要在Job级别再设置一层管理呢?这是因为,在前面刚介绍给,TaskTracker节点对JVM实例的调度级别是Job一级的,而JVM实例执行的单位是Task级别。
工作组件
1.MapEvent Fetcher
MapEvent Fetcher组件是TaskTracker节点内部的一个后台工作线程,用来向JobTracker节点请求某一个作业的任务完成事件,这个作业是正在TaskTracker节点上执行的。这个组件存在的意义在于Reduce任务在执行的时候需要Map任务的输出数据,因此Reduce任务在执行reduce操作之前需要shuffle所有的map输出到本地。
2.Map/Reduce Launcher
Map/Reduce Launcher组件也是TaskTracker节点内部的两个后台工作线程,它们分别负责调度合适的Map/Reduce任务到对应空闲/新的JVM实例上执行。当然,在将Task交给JVM实例运行之前还负责该任务对应的作业即自身的本地化。
3.TaskCleanup
TaskTracker节点每一次向JobTracker节点发送心跳包之后,除了带回一些需要JVM实例执行的任务之外,还带回来了一些操作命令,如KillJob、KillTask等,这一类任务并不需要JVM实例来执行,因此,TaskTracker节点在其内部开启了一个后台线程来专门的处理这些由于某些原因需要kill掉在正在其上执行的Job和Task。Job或Task的kill操作主要包括关闭对应的JVM实例,清理它们在TaskTracker节点上占用的临时Disk/Mem存储空间。对于在TaskTracker节点上执行的Job/Task所占用的临时磁盘存储空间的清理,也是由一个后台线程来全权负责处理的,这样做一是因为文件或目录的删除操作可能比较消耗时间,二是这些文件或目录已经没有任何用处了而不需要急着清除。
Map-Reduce工作模式

map数的计算
计算分片大小的公式是:
goalSize = totalSize / mapred.map.tasks
minSize = max {mapred.min.split.size, minSplitSize}
splitSize = max (minSize, min(goalSize, dfs.block.size))
totalSize是一个JOB的所有map总的输入大小,即Map input bytes。参数mapred.map.tasks的默认值是2,我们可以更改这个参数的值。计算好了goalSize之后还要确定上限和下限。
下限是max {mapred.min.split.size, minSplitSize} 。参数mapred.min.split.size的默认值为1个字节,minSplitSize随着File Format的不同而不同。
上限是 dfs.block.size,它的默认值是64兆。
举几个例子,例如Map input bytes是100兆,mapred.map.tasks默认值为2,那么分片大小就是50兆;如果我们把mapred.map.tasks改成1,那分片大小就变成了64兆。
计算好了分片大小之后接下来计算map数。Map数的计算是以文件为单位的,针对每一个文件做一个循环:
1. 文件大小/splitsize>1.1,创建一个split,这个split的大小=splitsize,文件剩余大小=文件大小-splitsize
2. 文件剩余大小/splitsize<1.1,剩余的部分作为一个split
举几个例子:
1. input只有一个文件,大小为100M,splitsize=blocksize,则map数为2,第一个map处理的分片为64M,第二个为36M
2. input只有一个文件,大小为65M,splitsize=blocksize,则map数为1,处理的分片大小为65M (因为65/64<1.1)
3. input只有一个文件,大小为129M,splitsize=blocksize,则map数为2,第一个map处理的分片为64M,第二个为65M
4. input有两个文件,大小为100M和20M,splitsize=blocksize,则map数为3,第一个文件分为两个map,第一个map处理的分片为64M,第二个为36M,第二个文件分为一个map,处理的分片大小为20M
5. input有10个文件,每个大小10M,splitsize=blocksize,则map数为10,每个map处理的分片大小为10M
再看2个更特殊的例子:
1. 输入文件有2个,分别为40M和20M,dfs.block.size = 64M, mapred.map.tasks采用默认值2。 那么splitSize = 30M ,map数实际为3,第一个文件分为2个map,第一个map处理的分片大小为30M,第二个map为10M;第二个文件分为1个map,大小为20M
2. 输入文件有2个,分别为40M和20M,dfs.block.size = 64M, mapred.map.tasks手工设置为1。 那么splitSize = 60M ,map数实际为2,第一个文件分为1个map,处理的分片大小为40M;第二个文件分为1个map,大小为20M
通过这2个特殊的例子可以看到mapred.map.tasks并不是设置的越大,JOB执行的效率就越高。同时,Hadoop在处理小文件时效率也会变差。
根据分片与map数的计算方法可以得出结论,一个map处理的分片最大不超过dfs.block.size * 1.1 ,默认情况下是70.4兆。但是有2个特例:
1. Hive中合并小文件的map only JOB,此JOB只会有一个或很少的几个map。
2. 输入文件格式为压缩的Text File,因为压缩的文本格式不知道如何拆分,所以也只能用一个map。
Reducetask数量
参数mapred.reduce.tasks的值,hadoop-site.xml文件中和mapreduce job运行时不设置的话默认为1
在HIVE中运行sql的情况又不同,hive会估算reduce task的数量,估算方法如下:
通常是ceil(input文件大小/1024*1024*1024),每1GB大小的输入文件对应一个reduce task。
特殊的情况是当sql只查询count(*)时,reduce task数被设置成1。