可以访问 这里 查看更多关于 消息中间件 的原创文章。
上一篇 介绍了移山(数据迁移平台)实时数据同步的整体架构;
本文主要介绍移山(数据迁移平台)实时数据同步是如何保证消息的顺序性。可以访问 这里 查看更多关于大数据平台建设的原创文章。
一. 什么是消息的顺序性?
消息生产端将消息发送给同一个MQ服务器的同一个分区,并且按顺序发送;
消费消费端按照消息发送的顺序进行消费。
二. 为什么要保证消息的顺序性?
在某些业务功能场景下需要保证消息的发送和接收顺序是一致的,否则会影响数据的使用。
需要保证消息有序的场景
移山的实时数据同步使用
canal组件订阅MySQL数据库的日志,并将其投递至 kafka 中(想了解移山实时同步服务架构设计的可以点 这里);
kafka 消费端再根据具体的数据使用场景去处理数据(存入 HBase、MySQL 或直接做实时分析);
由于binlog 本身是有序的,因此写入到mq之后也需要保障顺序。
-
假如现在移山创建了一个实时同步任务,然后订阅了一个业务数据库的订单表;
-
上游业务,向订单表里插入了一个订单,然后对该订单又做了一个更新操作,则 binlog 里会自动写入插入操作和更新操作的数据,这些数据会被 canal server 投递至 kafka broker 里面;
-
如果 kafka 消费端先消费到了更新日志,后消费到插入日志,则在往目标表里做操作时就会因为数据缺失导致发生异常。
三. 移山实时同步服务是怎么保证消息的顺序性
实时同步服务消息处理整体流程如下:
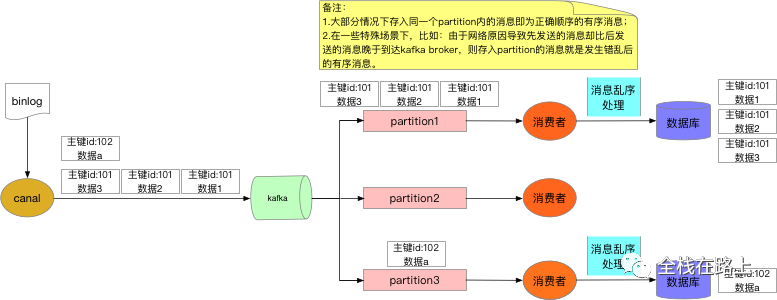
我们主要通过以下两个方面去保障保证消息的顺序性。
1. 将需要保证顺序的消息发送到同一个partition
1.1 kafka的同一个partition内的消息是有序的
-
kafka 的同一个 partition 用一个write ahead log组织, 是一个有序的队列,所以可以保证FIFO的顺序;
-
因此生产者按照一定的顺序发送消息,broker 就会按照这个顺序把消息写入 partition,消费者也会按照相同的顺序去读取消息;
-
kafka 的每一个 partition 不会同时被两个消费者实例消费,由此可以保证消息消费的顺序性。
1.2 控制同一key分发到同一partition
要保证同一个订单的多次修改到达 kafka 里的顺序不能乱,可以在Producer 往 kafka 插入数据时,控制同一个key (可以采用订单主键key-hash算法来实现)发送到同一 partition,这样就能保证同一笔订单都会落到同一个 partition 内。
1.3 canal 需要做的配置
canal 目前支持的mq有kafka/rocketmq,本质上都是基于本地文件的方式来支持了分区级的顺序消息的能力。我们只需在配置 instance 的时候开启如下配置即可:
1> canal.properties
# leader节点会等待所有同步中的副本确认之后再确认这条记录是否发送完成
canal.mq.acks = all
备注:
-
这样只要至少有一个同步副本存在,记录就不会丢失。
2> instance.properties
1 # 散列模式的分区数 2 canal.mq.partitionsNum=2 3 # 散列规则定义 库名.表名: 唯一主键,多个表之间用逗号分隔 4 canal.mq.partitionHash=test.lyf_canal_test:id
备注:
-
同一条数据的增删改操作 产生的 binlog 数据都会写到同一个分区内;
-
查看指定topic的指定分区的消息,可以使用如下命令:
bin/kafka-console-consumer.sh --bootstrap-server serverlist --topic topicname --from-beginning --partition 0
2. 通过日志时间戳和日志偏移量进行乱序处理
将同一个订单数据通过指定key的方式发送到同一个 partition 可以解决大部分情况下的数据乱序问题。
2.1 特殊场景
对于一个有着先后顺序的消息A、B,正常情况下应该是A先发送完成后再发送B。但是在异常情况下:
-
A发送失败了,B发送成功,而A由于重试机制在B发送完成之后重试发送成功了;
-
这时对于本身顺序为AB的消息顺序变成了BA。
移山的实时同步服务会在将订阅到的数据存入HBase之前再加一层乱序处理 。
2.2 binlog里的两个重要信息
使用 mysqlbinlog 查看 binlog:
/usr/bin/mysqlbinlog --base64-output=decode-rows -v /var/lib/mysql/mysql-bin.000001
执行时间和偏移量:

备注:
-
每条数据都会有执行时间和偏移量这两个重要信息,下边的校验逻辑核心正是借助了这两个值;
-
执行的sql 语句在 binlog 中是以base64编码格式存储的,如果想查看sql 语句,需要加上:
--base64-output=decode-rows -v参数来解码; -
偏移量:
-
Position 就代表 binlog 写到这个偏移量的地方,也就是写了这么多字节,即当前 binlog 文件的大小;
-
也就是说后写入数据的 Position 肯定比先写入数据的 Position 大,因此可以根据 Position 大小来判断消息的顺序。
-
3.消息乱序处理演示
3.1 在订阅表里插入一条数据,然后再做两次更新操作:
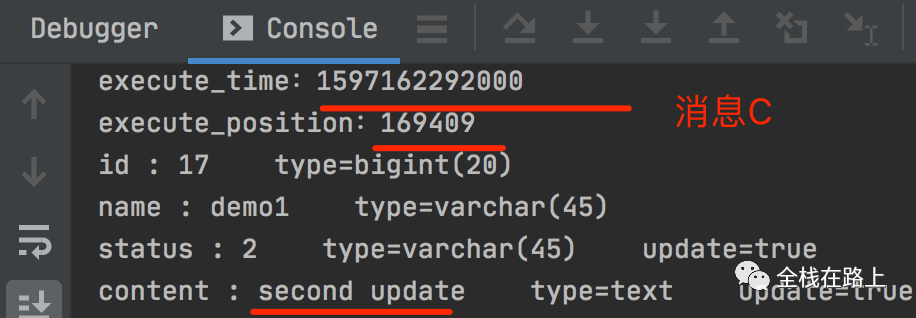
MariaDB [test]> insert into lyf_canal_test (name,status,content) values('demo1',1,'demo1 test'); Query OK, 1 row affected (0.00 sec) MariaDB [test]> update lyf_canal_test set name = 'demo update' where id = 13; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 MariaDB [test]> update lyf_canal_test set name = 'demo update2',content='second update',status=2 where id = 13; Query OK, 1 row affected (0.00 sec)
3.2 产生三条需要保证顺序的消息
把插入,第一次更新,第二次更新这三次操作产生的 binlog 被 canal server 推送至 kafka 中的消息分别称为:消息A,消息B,消息C。
-
消息A:

-
消息B:

-
消息C:
3.3 网络原因造成消息乱序
假设由于不可知的网络原因:
-
kafka broker收到的三条消息分别为:消息A,消息C,消息B;
-
则 kafka 消费端消费到的这三条消息先后顺序就是:消息A,消息C,消息B
-
这样就造成了消息的乱序,因此订阅到的数据在存入目标表前必须得加乱序校验处理。
3.4 消息乱序处理逻辑
我们利用HBase的特性,将数据主键做为目标表的 rowkey。当 kafka 消费端消费到数据时,乱序处理主要流程(摘自禧云数芯大数据平台技术白皮书)如下:

demo的三条消息处理流程如下:
1> 判断消息A 的主键id做为rowkey在hbase的目标表中不存在,则将消息A的数据直接插入HBase: 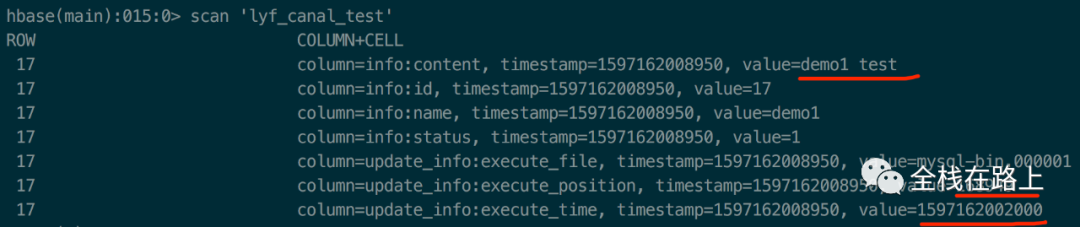
2> 消息C 的主键id做为rowkey,已经在目标表中存在,则这时需要拿消息C 的执行时间和表中存储的执行时间去判断:
-
如果消息C 中的执行时间小于表中存储的执行时间,则证明消息C 是重复消息或乱序的消息,直接丢弃;
-
消息C 中的执行时间大于表中存储的执行时间,则直接更新表数据(本demo即符合该种场景):

-
消息C 中的执行时间等于表中存储的执行时间,则这时需要拿消息C 的偏移量和表中存储的偏移量去判断:
-
消息C 中的偏移量小于表中存储的偏移量,则证明消息C 是重复消息,直接丢弃;
-
消息C 中的偏移量大于等于表中存储的偏移量,则直接更新表数据。
-
3> 消息B 的主键id做为rowkey,已经在目标表中存在,则这时需要拿消息B 的执行时间和表中存储的执行时间去判断:
-
由于消息B中的执行时间小于表中存储的执行时间(即消息C 的执行时间),因此消息B 直接丢弃。
3.5 主要代码
kafka 消费端将消费到的消息进行格式化处理和组装,并借助 HBase-client API 来完成对 HBase 表的操作。
1> 使用Put组装单行数据
/** * 包名: org.apache.hadoop.hbase.client.Put * hbaseData 为从binlog订阅到的数据,通过循环,为目标HBase表 * 添加rowkey、列簇、列数据。 * 作用:用来对单个行执行加入操作。 */ Put put = new Put(Bytes.toBytes(hbaseData.get("id"))); // hbaseData 为从binlog订阅到的数据,通过循环,为目标HBase表添加列簇和列 put.addColumn(Bytes.toBytes("info"), Bytes.toBytes(mapKey), Bytes.toBytes(hbaseData.get(mapKey)));
2> 使用 checkAndMutate,更新HBase表的数据
只有服务端对应rowkey的列数据与预期的值符合期望条件(大于、小于、等于)时,才会将put操作提交至服务端。
// 如果 update_info(列族) execute_time(列) 不存在值就插入数据,如果存在则返回false boolean res1 = table.checkAndMutate(Bytes.toBytes(hbaseData.get("id")), Bytes.toBytes("update_info")) .qualifier(Bytes.toBytes("execute_time")).ifNotExists().thenPut(put); // 如果存在,则去比较执行时间 if (!res1) { // 如果本次传递的执行时间大于HBase中的执行时间,则插入put boolean res2 =table.checkAndPut(Bytes.toBytes(hbaseData.get("id")), Bytes.toBytes("update_info"), Bytes.toBytes("execute_time"), CompareFilter.CompareOp.GREATER, Bytes.toBytes(hbaseData.get("execute_time")),put); // 执行时间相等时,则去比较偏移量,本次传递的值大于HBase中的值则插入put if (!res2) { boolean res3 = table.checkAndPut(Bytes.toBytes(hbaseData.get("id")), Bytes.toBytes("update_info"), Bytes.toBytes("execute_position"), CompareFilter.CompareOp.GREATER, Bytes.toBytes(hbaseData.get("execute_position")),put); } }
四.总结
-
目前移山的实时同步服务,kafka 消费端是使用一个线程去消费数据;
-
如果将来有版本升级需求,将消费端改为多个线程去消费数据时,要考虑到多线程消费时有序的消息会被打乱这种情况的解决办法。
更多文章
欢迎访问更多关于消息中间件的原创文章:
- RabbitMQ系列之消息确认机制
- RabbitMQ系列之RPC实现
- RabbitMQ系列之怎么确保消息不丢失
- RabbitMQ系列之基本概念和基本用法
- RabbitMQ系列之部署模式
- RabbitMQ系列之单机模式安装
关注微信公众号
欢迎大家关注我的微信公众号阅读更多关于 消息队列 的原创文章: