K-Means是常用的聚类算法,与其他聚类算法相比,其时间复杂度低,聚类的效果也还不错,这里简单介绍一下k-means算法,下图是一个手写体数据集聚类的结果。

基本思想
k-means算法需要事先指定簇的个数k,算法开始随机选择k个记录点作为中心点,然后遍历整个数据集的各条记录,将每条记录归到离它最近的中心点所在的簇中,之后以各个簇的记录的均值中心点取代之前的中心点,然后不断迭代,直到收敛,算法描述如下:

上面说的收敛,可以看出两方面,一是每条记录所归属的簇不再变化,二是优化目标变化不大。算法的时间复杂度是O(K*N*T),k是中心点个数,N数据集的大小,T是迭代次数。
优化目标
k-means的损失函数是平方误差:

其中ωkωk表示第k个簇,u(ωk)u(ωk)表示第k个簇的中心点,RSSkRSSk是第k个簇的损失函数,RSSRSS表示整体的损失函数。优化目标就是选择恰当的记录归属方案,使得整体的损失函数最小。
中心点的选择
k-meams算法的能够保证收敛,但不能保证收敛于全局最优点,当初始中心点选取不好时,只能达到局部最优点,整个聚类的效果也会比较差。可以采用以下方法:k-means中心点
1、选择彼此距离尽可能远的那些点作为中心点;
2、先采用层次进行初步聚类输出k个簇,以簇的中心点的作为k-means的中心点的输入。
3、多次随机选择中心点训练k-means,选择效果最好的聚类结果
k值的选取
k-means的误差函数有一个很大缺陷,就是随着簇的个数增加,误差函数趋近于0,最极端的情况是每个记录各为一个单独的簇,此时数据记录的误差为0,但是这样聚类结果并不是我们想要的,可以引入结构风险对模型的复杂度进行惩罚:
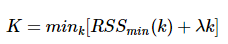
λλ是平衡训练误差与簇的个数的参数,但是现在的问题又变成了如何选取λλ了,有研究[参考文献1]指出,在数据集满足高斯分布时,λ=2mλ=2m,其中m是向量的维度。
另一种方法是按递增的顺序尝试不同的k值,同时画出其对应的误差值,通过寻求拐点来找到一个较好的k值,详情见下面的文本聚类的例子。
k-means文本聚类
我爬取了36KR的部分文章,共1456篇,分词后使用sklearn进行k-means聚类。分词后数据记录如下:

使用TF-IDF进行特征词的选取,下图是中心点的个数从3到80对应的误差值的曲线:

从上图中在k=10处出现一个较明显的拐点,因此选择k=10作为中心点的个数,下面是10个簇的数据集的个数。
{0: 152, 1: 239, 2: 142, 3: 61, 4: 119, 5: 44, 6: 71, 7: 394, 8: 141, 9: 93}
簇标签生成
聚类完成后,我们需要一些标签来描述簇,聚类完后,相当于每个类都用一个类标,这时候可以用TFIDF、互信息、卡方等方法来选取特征词作为标签。关于卡方和互信息特征提取可以看我之前的文章文本特征选择,下面是10个类的tfidf标签结果。
Cluster 0: 商家 商品 物流 品牌 支付 导购 网站 购物 平台 订单
Cluster 1: 投资 融资 美元 公司 资本 市场 获得 国内 中国 去年
Cluster 2: 手机 智能 硬件 设备 电视 运动 数据 功能 健康 使用
Cluster 3: 数据 平台 市场 学生 app 移动 信息 公司 医生 教育
Cluster 4: 企业 招聘 人才 平台 公司 it 移动 网站 安全 信息
Cluster 5: 社交 好友 交友 宠物 功能 活动 朋友 基于 分享 游戏
Cluster 6: 记账 理财 贷款 银行 金融 p2p 投资 互联网 基金 公司
Cluster 7: 任务 协作 企业 销售 沟通 工作 项目 管理 工具 成员
Cluster 8: 旅行 旅游 酒店 预订 信息 城市 投资 开放 app 需求
Cluster 9: 视频 内容 游戏 音乐 图片 照片 广告 阅读 分享 功能
实现代码
1 #!--encoding=utf-8 2 3 from __future__ import print_function 4 from sklearn.feature_extraction.text import TfidfVectorizer 5 from sklearn.feature_extraction.text import HashingVectorizer 6 import matplotlib.pyplot as plt 7 from sklearn.cluster import KMeans, MiniBatchKMeans 8 9 10 def loadDataset(): 11 '''导入文本数据集''' 12 f = open('36krout.txt','r') 13 dataset = [] 14 lastPage = None 15 for line in f.readlines(): 16 if '< title >' in line and '< / title >' in line: 17 if lastPage: 18 dataset.append(lastPage) 19 lastPage = line 20 else: 21 lastPage += line 22 if lastPage: 23 dataset.append(lastPage) 24 f.close() 25 return dataset 26 27 def transform(dataset,n_features=1000): 28 vectorizer = TfidfVectorizer(max_df=0.5, max_features=n_features, min_df=2,use_idf=True) 29 X = vectorizer.fit_transform(dataset) 30 return X,vectorizer 31 32 def train(X,vectorizer,true_k=10,minibatch = False,showLable = False): 33 #使用采样数据还是原始数据训练k-means, 34 if minibatch: 35 km = MiniBatchKMeans(n_clusters=true_k, init='k-means++', n_init=1, 36 init_size=1000, batch_size=1000, verbose=False) 37 else: 38 km = KMeans(n_clusters=true_k, init='k-means++', max_iter=300, n_init=1, 39 verbose=False) 40 km.fit(X) 41 if showLable: 42 print("Top terms per cluster:") 43 order_centroids = km.cluster_centers_.argsort()[:, ::-1] 44 terms = vectorizer.get_feature_names() 45 print (vectorizer.get_stop_words()) 46 for i in range(true_k): 47 print("Cluster %d:" % i, end='') 48 for ind in order_centroids[i, :10]: 49 print(' %s' % terms[ind], end='') 50 print() 51 result = list(km.predict(X)) 52 print ('Cluster distribution:') 53 print (dict([(i, result.count(i)) for i in result])) 54 return -km.score(X) 55 56 def test(): 57 '''测试选择最优参数''' 58 dataset = loadDataset() 59 print("%d documents" % len(dataset)) 60 X,vectorizer = transform(dataset,n_features=500) 61 true_ks = [] 62 scores = [] 63 for i in xrange(3,80,1): 64 score = train(X,vectorizer,true_k=i)/len(dataset) 65 print (i,score) 66 true_ks.append(i) 67 scores.append(score) 68 plt.figure(figsize=(8,4)) 69 plt.plot(true_ks,scores,label="error",color="red",linewidth=1) 70 plt.xlabel("n_features") 71 plt.ylabel("error") 72 plt.legend() 73 plt.show() 74 75 def out(): 76 '''在最优参数下输出聚类结果''' 77 dataset = loadDataset() 78 X,vectorizer = transform(dataset,n_features=500) 79 score = train(X,vectorizer,true_k=10,showLable=True)/len(dataset) 80 print (score) 81 #test() 82 out()
参考链接:http://www.cnblogs.com/fengfenggirl/p/k-means.html