哈哈,终于找到一个可以一键获取所有公众号里面的文章了,虽然比较笨,但是先凑活着,毕竟还破解不了登录。
参考链接:https://mp.weixin.qq.com/s/dlks2QoU8oiPPEc9et8Rbg
第一步:先注册一个公众号
注册之后登录到主页,找到这个素材管理
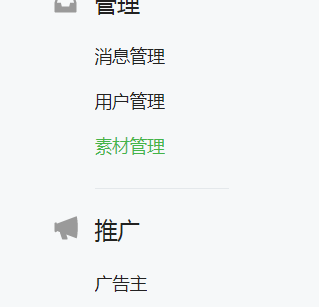
然后你会看到下面这个页面
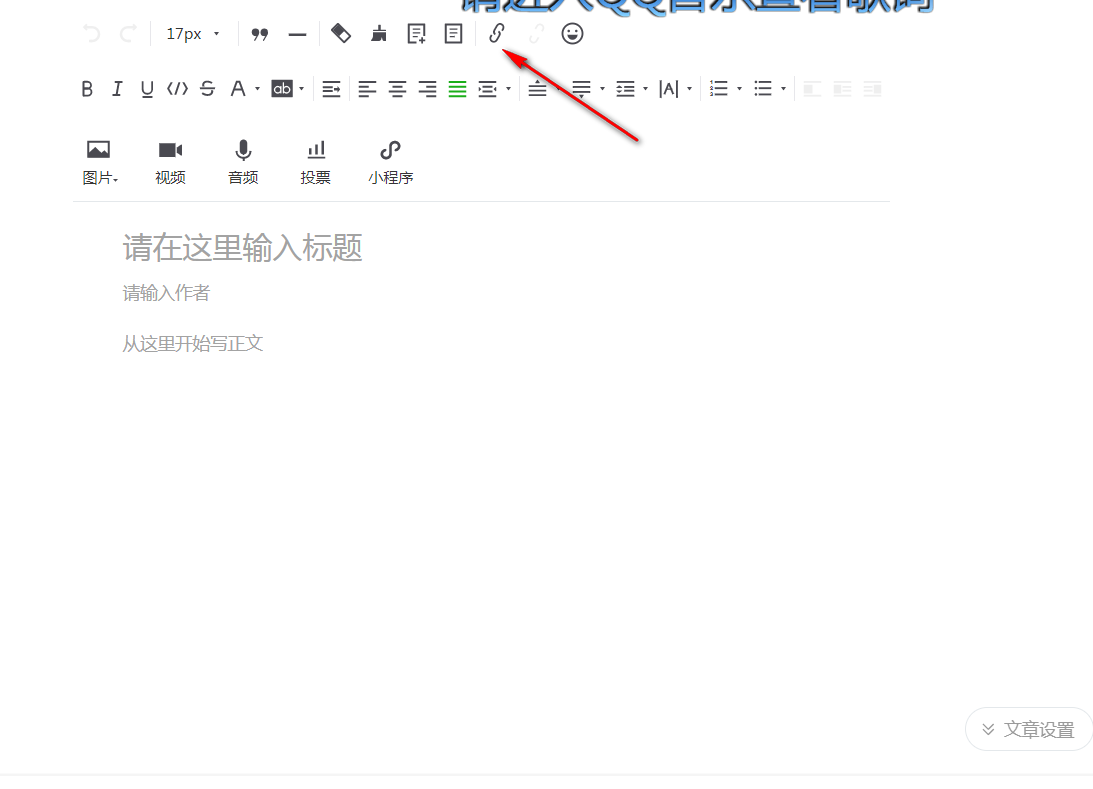
点击这个红色箭头指向的这个链接
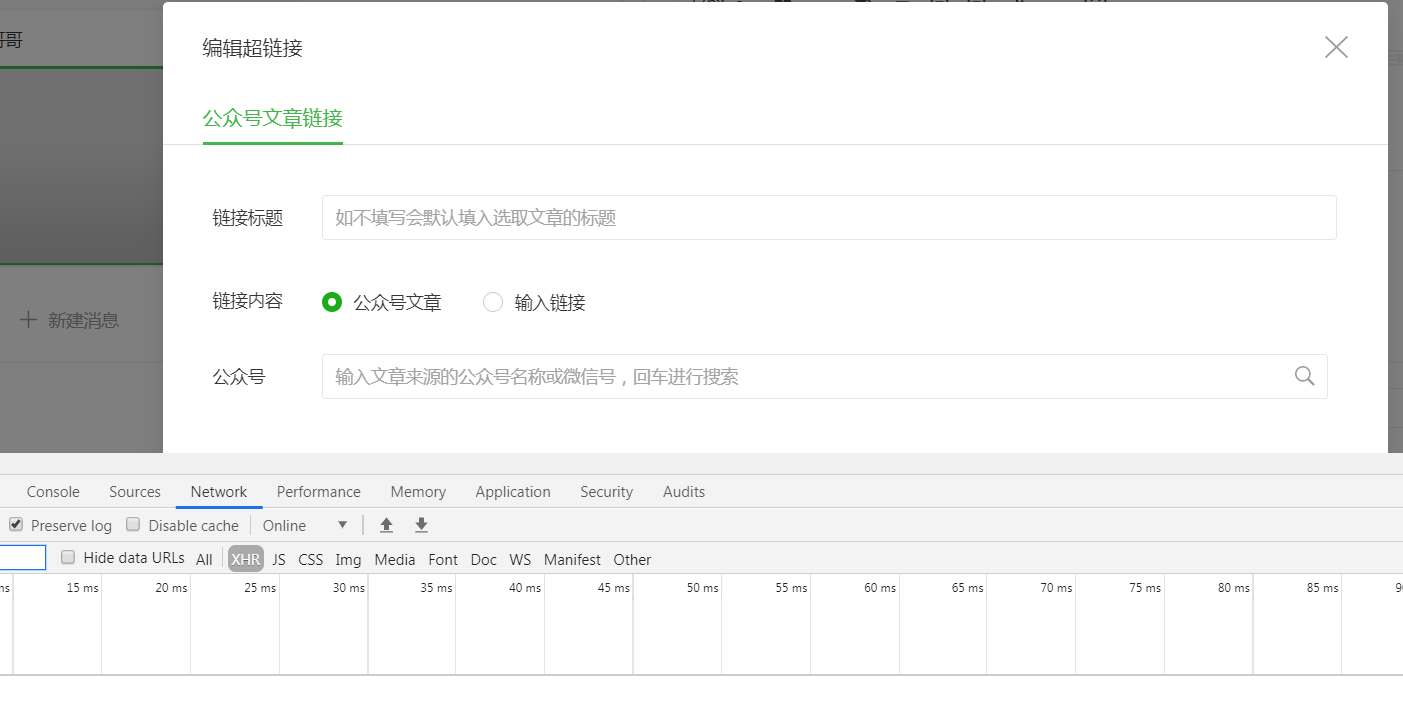
记得打开调试工具
然后搜索你想爬取的公众号
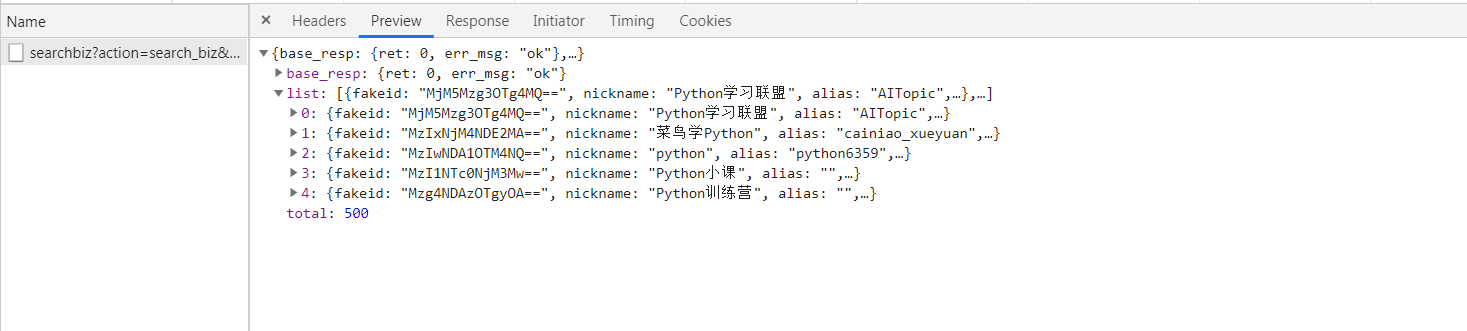
这个请求会返回我们搜索到的公众号,我们要的公众号也在这个列表里面,假如在第一个

我们需要这个fake-id来标记这个公众号
接下选中,然后点一下
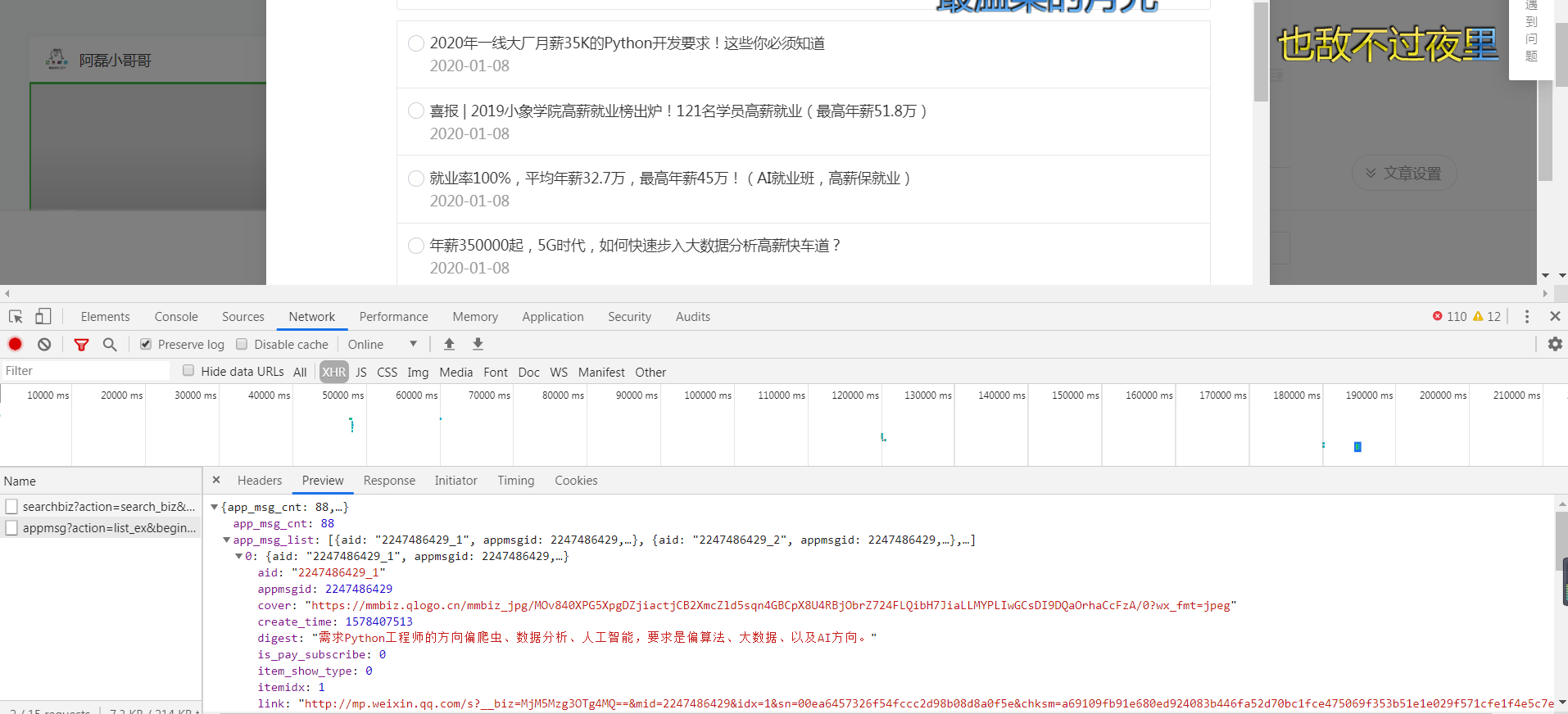
然后文章列表就出来了
整个过程就需要token,公众号名字,还有cookie了
最后直接上代码了
# -*- coding: utf-8 -*- import pymysql as pymysql from fake_useragent import UserAgent import requests import json from retrying import retry @retry(stop_max_attempt_number=5) def get_author_list(): """ 获取搜索到的公众号列表 :return: """ global s url = "https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1".format( name, token) try: response = s.get(url, headers=headers, cookies=cookie) text = json.loads(response.text) # print('一共查询出来{}个公众号'.format(text['total'])) return text except Exception as e: print(e) reset_parmas() @retry(stop_max_attempt_number=5) def get_first_author_params(text): """ 获取单个公众号的参数 :param text: 前面搜索获取的公众号列表 :return:fake_id公众号id, text请求公众号详情的相应内容 """ fake_id = text['list'][0] # 一般第一个就是咱们需要的,所以取第一个 # print(text['list'][0]) url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(fake_id['fakeid'], token) response = s.get(url, headers=headers, cookies=cookie) try: text1 = json.loads(response.text) return text1, fake_id except Exception as e: print(e) reset_parmas() @retry(stop_max_attempt_number=5) def get_title_url(text, fake_id): """ 得到公众号的标题和链接 :param text: :param fake_id: :return: """ print(text) num = int(text['app_msg_cnt']) if num % 5 > 0: num = num // 5 + 1 for i in range(num): # token begin:参数传入 url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin={}&count=5&fakeid={}&type=9&query=&token={}&lang=zh_CN&f=json&ajax=1'.format(str(i * 5),fake_id['fakeid'], token,) try: response = s.get(url, headers=headers, cookies=cookie) text = json.loads(response.text) print(text) artile_list = text['app_msg_list'] for artile in artile_list: print('标题:{}'.format(artile['title'])) print('标题链接:{}'.format(artile['link'])) save_mysql(name, artile['title'], artile['link']) except Exception as e: print(e) reset_parmas() def save_mysql(name, title, url): """ 保存数据到数据库 :param name: 作者名字 :param title:文章标题 :param url: 文章链接 :return: """ try: sql = """INSERT INTO title_url(author_name, title, url) values ('{}', '{}', '{}')""".format(name, title, url) conn.ping(reconnect=False) cur.execute(sql) conn.commit() except Exception as e: print(e) def reset_parmas(): """ 失效后重新输入参数 :return: """ global name, token, s, cookie, headers name = input("请输入你要查看的公众号名字: ") token = input("请输入你当前登录自己公众号的token: ") cookies = input("请输入当前页面的cookie: ") s = requests.session() cookie = {'cookie': cookies} headers = { "User-Agent": UserAgent().random, "Host": "mp.weixin.qq.com", } def run(): reset_parmas() text = get_author_list() text1, fake_id = get_first_author_params(text) get_title_url(text1, fake_id) run()
需要说明一下,数据库自己连 我都不上代码了
还有就是好像接口更新的频繁,所以你只需要看懂我的代码的逻辑就可以了
OK