LevelDB 是基于 LSM 树优化而来的存储系统
LSM 树会将索引分为内存和磁盘两部分,将内存中的 C0 树和磁盘上的 C1 树归并来存储,并在内存达到阈值时启动树合并。
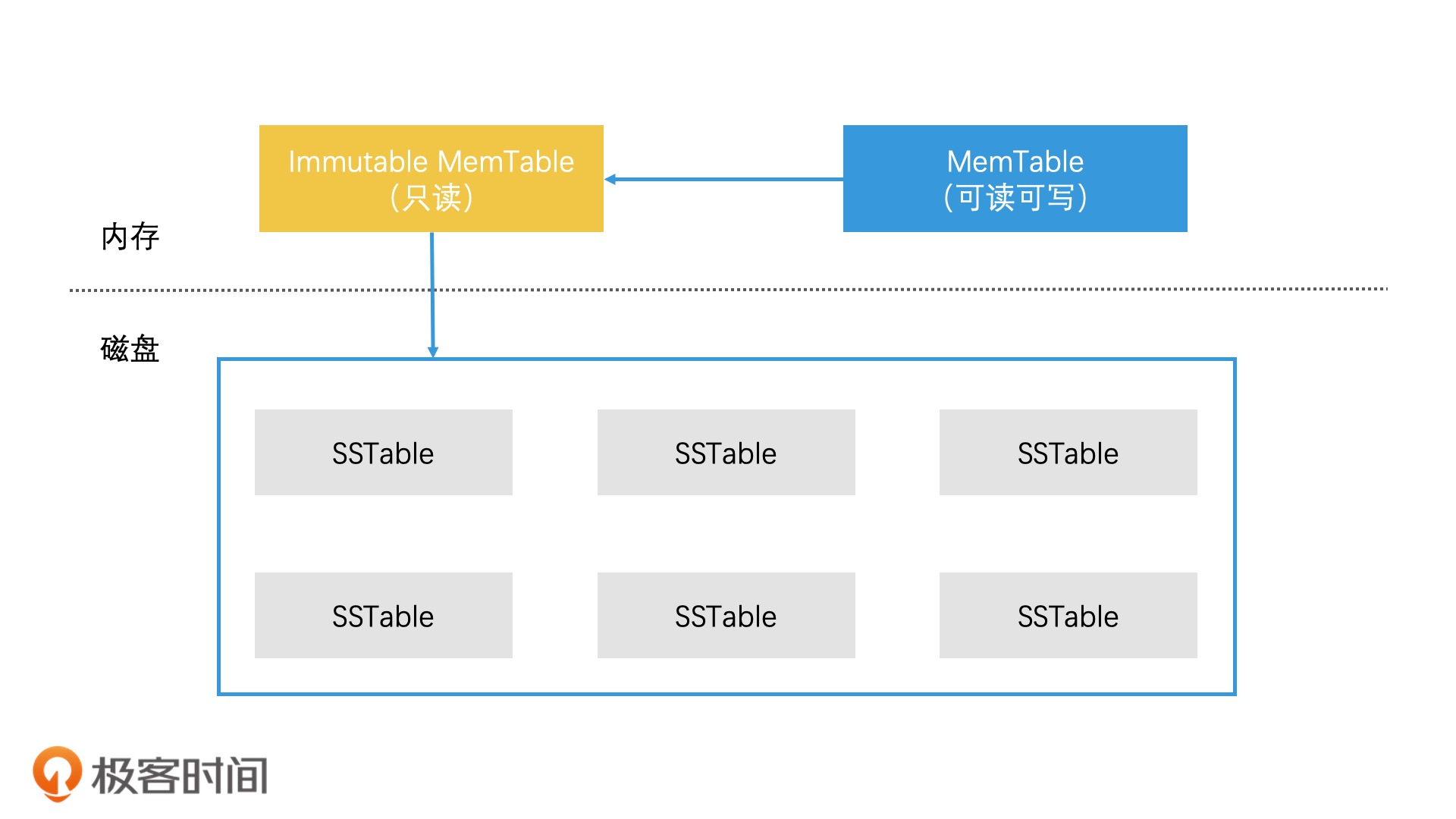
- 为了防止一边被写入修改,一边被写入磁盘,所以设计读写分离,它将内存中的数据分为两块,一块叫作 MemTable,它是可读可写的。另一块叫作 Immutable MemTable,它是只读的。这两块数据的数据结构完全一样,都是跳表。当 MemTable 的存储数据达到上限时,我们直接将它切换为只读的 Immutable MemTable,然后重新生成一个新的 MemTable,来支持新数据的写入和查询。这时,将内存索引存储到磁盘的问题,就变成了将 Immutable MemTable 写入磁盘的问题。而且,由于 Immutable MemTable 是只读的,因此,它不需要加锁就可以高效地写入磁盘中
- 为了减小合并开销,LevelDB 采用了延迟合并的设计来优化。具体来说就是,先将 Immutable MemTable 顺序快速写入磁盘,直接变成一个个 SSTable(Sorted String Table)文件,之后再对这些 SSTable 文件进行合并。这样就避免了 C0 树和 C1 树昂贵的合并代价。
因为磁盘中原有的 C1 树被多个较小的 SSTable 文件代替了。那现在我们要解决的问题就变成了,如何快速提高磁盘中多个 SSTable 文件的检索效率
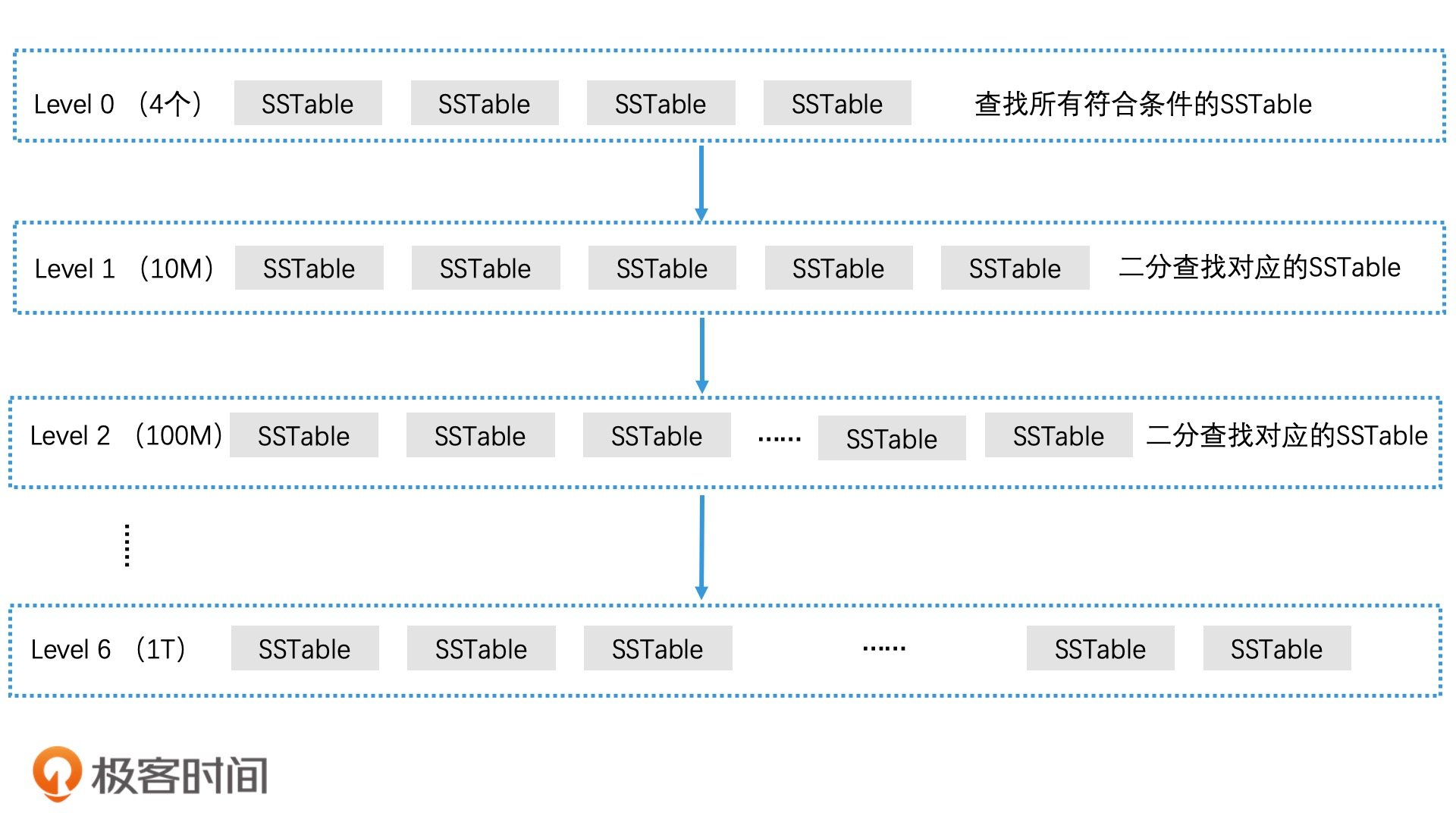
- 分层思想:由于SSTable 文件是由 Immutable MemTable 将数据顺序导入生成的。尽管 SSTable 中的数据是有序的,但是每个 SSTable 覆盖的数据范围都是没有规律的,所以 SSTable 之间的数据很可能有重叠,对于 SSTable 文件,我们需要将它整理一下,将 SSTable 文件中存的数据进行重新划分,让每个 SSTable 的覆盖范围不重叠。这样我们就能将 SSTable 按照覆盖范围来排序了。并且,由于每个 SSTable 覆盖范围不重叠,当我们需要查找数据的时候,我们只需要通过二分查找的方式,找到对应的一个 SSTable 文件,就可以在这个 SSTable 中完成查询了,对于少量索引数据和大规模索引数据的合并,我们可以采用滚动合并法来避免大量数据的无效复制。因此,LevelDB 也采用了这个方法,将 SSTable 进行分层管理,然后逐层滚动合并。从 Immutable MemTable 转成的 SSTable 会被放在 Level 0 层。
对内存中索引的高效检索,我们可以用很多检索技术,如红黑树、跳表等,这些数据结构会比 B+ 树更高效。因此,LevelDB 对于 LSM 树的第一个改进,就是使用跳表代替 B+ 树来实现内存中的 C0 树。
查找:首先,我们会在 Level 0 层中进行查找。由于 Level 0 层的 SSTable 没有做过多路归并处理,它们的覆盖范围是有重合的。因此,我们需要检查 Level 0 层中所有符合条件的 SSTable,在其中查找对应的元素。如果 Level 0 没有查到,那么就下沉一层继续查找。而从 Level 1 开始,每一层的 SSTable 都做过了处理,这能保证覆盖范围不重合的。因此,对于同一层中的 SSTable,我们可以使用二分查找算法快速定位唯一的一个 SSTable 文件。如果查到了,就返回对应的 SSTable 文件;如果没有查到,就继续沉入下一层,直到查到了或查询结束。
LevelDB 使用索引与数据分离的设计思想,将 SSTable 分为数据存储区和数据索引区两大部分,读取 SSTable 文件时,不需要将整个 SSTable 文件全部读入内存,只需要先将数据索引区中的相关数据读入内存就可以了。这样就能大幅减少磁盘 IO 次数。结合BloomFilter快速确定这个 SSTable 是否包含查询的元素,在进行精确查找时,我们将数据索引区中的 Index Block 读出,Index Block 中的每条记录都记录了每个 Data Block 的最小分隔 key、起始位置,还有 block 的大小。由于所有的记录都是根据 Key 排好序的,因此,我们可以使用二分查找算法,在 Index Block 中找到我们想查询的 Key。那最后一步,就是将这个 Key 对应的 Data block 从 SSTable 文件中读出来,这样我们就完成了数据的查找和读取

每次对 SSTable 进行二分查找时,我们都需要将 Index Block 和相应的 Data Block 分别从磁盘读入内存,这样就会造成两次磁盘 I/O 操作,针对这两次读磁盘操作,LevelDB 分别设计了 table cache 和 block cache 两个缓存。其中,block cache 是配置可选的,它是将最近使用的 Data Block 加载在内存中。而 table cache 则是将最近使用的 SSTable 的 Index Block 加载在内存中。这两个缓存都使用 LRU 机制进行替换管理,当我们想读取一个 SSTable 的 Index Block 时,首先要去 table cache 中查找。如果查到了,就可以避免一次磁盘操作,从而提高检索效率。同理,如果接下来要读取对应的 Data Block 数据,那么我们也先去 block cache 中查找。如果未命中,我们才会去真正读磁盘