1.List item
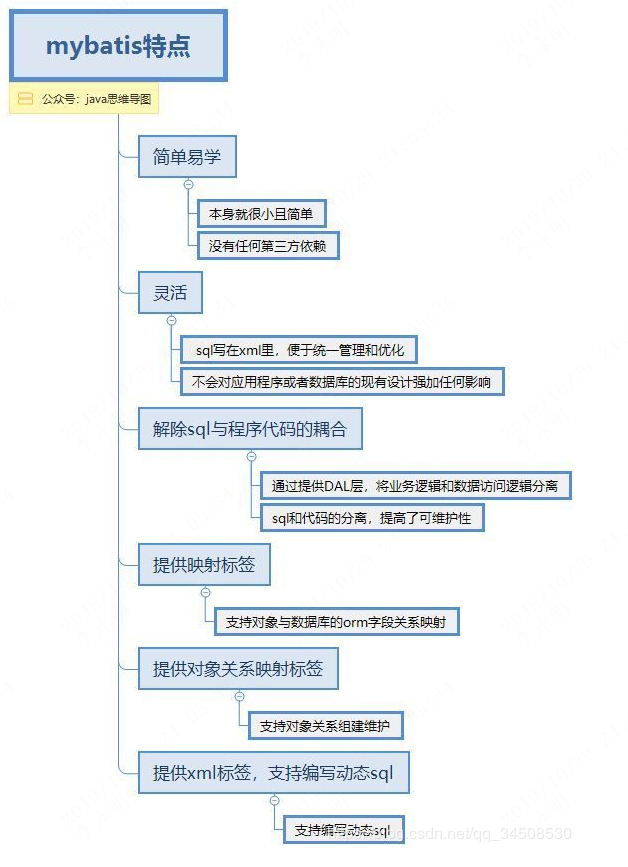

区别一
如果Mybatis Plus是扳手,那Mybatis Generator就是生产扳手的工厂。
通俗来讲——
MyBatis:一种操作数据库的框架,提供一种Mapper类,支持让你用java代码进行增删改查的数据库操作,省去了每次都要手写sql语句的麻烦。但是!有一个前提,你得先在xml中写好sql语句,是不是很麻烦?于是有下面的↓
Mybatis Generator:自动为Mybatis生成简单的增删改查sql语句的工具,省去一大票时间,两者配合使用,开发速度快到飞起。至于标题说的↓
Mybatis Plus:国人团队苞米豆在Mybatis的基础上开发的框架,在Mybatis基础上扩展了许多功能,荣获了2018最受欢迎国产开源软件第5名,当然也有配套的↓
Mybatis Plus Generator:同样为苞米豆开发,比Mybatis Generator更加强大,支持功能更多,自动生成Entity、Mapper、Service、Controller等
总结:
数据库框架:Mybatis Plus > Mybatis
代码生成器:Mybatis Plus Generator > Mybatis Generator
区别二
Mybatis-Plus是一个Mybatis的增强工具,它在Mybatis的基础上做了增强,却不做改变。我们在使用Mybatis-Plus之后既可以使用Mybatis-Plus的特有功能,又能够正常使用Mybatis的原生功能。Mybatis-Plus(以下简称MP)是为简化开发、提高开发效率而生,但它也提供了一些很有意思的插件,比如SQL性能监控、乐观锁、执行分析等。
Mybatis虽然已经给我们提供了很大的方便,但它还是有不足之处,实际上没有什么东西是完美的,MP的存在就是为了稍稍弥补Mybatis的不足。在我们使用Mybatis时会发现,每当要写一个业务逻辑的时候都要在DAO层写一个方法,再对应一个SQL,即使是简单的条件查询、即使仅仅改变了一个条件都要在DAO层新增一个方法,针对这个问题,MP就提供了一个很好的解决方案,之后我会进行介绍。另外,MP的代码生成器也是一个很有意思的东西,它可以让我们避免许多重复性的工作,下面我将介绍如何在你的项目中集成MP。
一、 集成步骤↓:(首先,你要有个spring项目)
集成依赖,pom中加入依赖即可,不多说:
Java代码 收藏代码

说明:笔者使用的版本为:mybatis-plus.version=2.1-gamma,上边的代码中有两个依赖,第一个是mybatis-plus核心依赖,第二个是使用代码生成器时需要的模板引擎依赖,若果你不打算使用代码生成器,此处可不引入。
注意:mybatis-plus的核心jar包中已集成了mybatis和mybatis-spring,所以为避免冲突,请勿再次引用这两个jar包。
二、 在spring中配置MP:

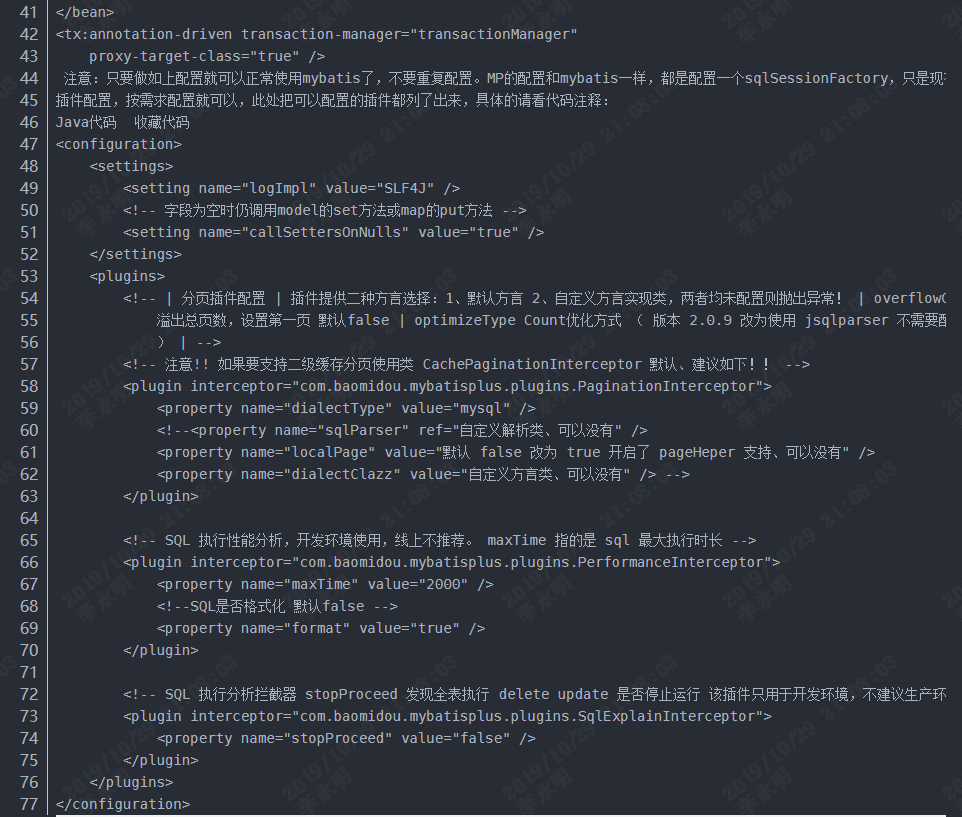
注意:执行分析拦截器和性能分析推荐只在开发时调试程序使用,为保证程序性能和稳定性,建议在生产环境中注释掉这两个插件。
数据源:(此处使用druid)
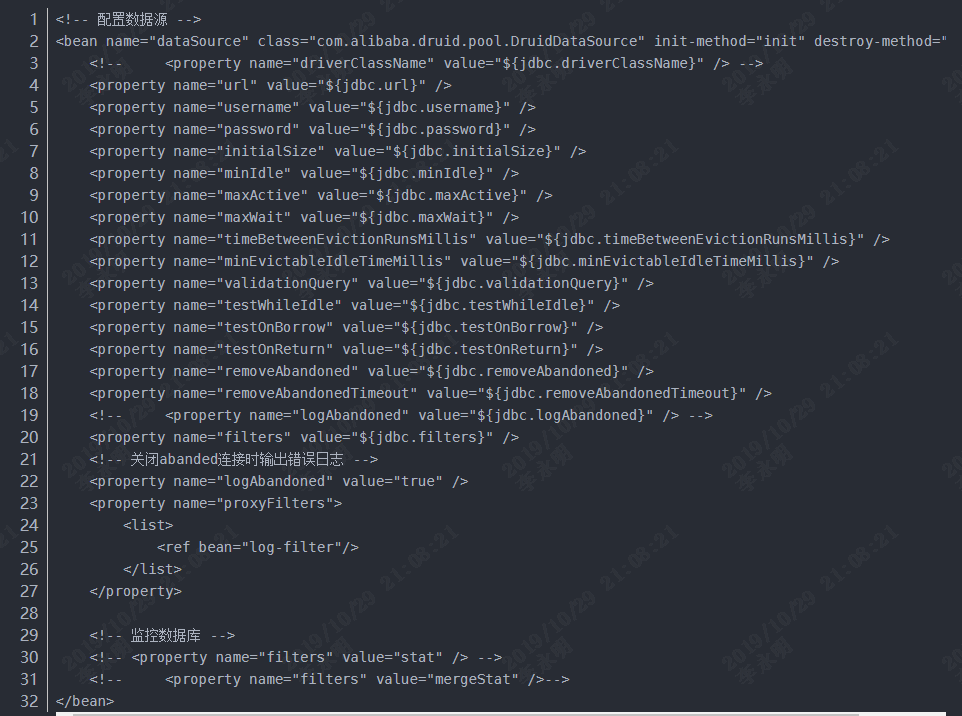
到此,MP已经集成进我们的项目中了,下面将介绍它是如何简化我们的开发的。
**
三、 简单的CURD操作↓:
**
假设我们有一张user表,且已经建立好了一个与此表对应的实体类User,我们来介绍对user的简单增删改查操作。
建立DAO层接口。我们在使用普通的mybatis时会建立一个DAO层接口,并对应一个xml用来写SQL。在这里我们同样要建立一个DAO层接口,但是若无必要,我们甚至不需要建立xml,就可以进行资源的CURD操作了,我们只需要让我们建立的DAO继承MP提供的BaseMapper<?>即可:
public interface UserMapper extends BaseMapper { }
然后在我们需要做数据CURD时,像下边这样就好了:
Java代码 收藏代码
// 初始化 影响行数
int result = 0;
// 初始化 User 对象
User user = new User();
// 插入 User (插入成功会自动回写主键到实体类)
user.setName(“Tom”);
result = userMapper.insert(user);
// 更新 User
user.setAge(18);
result = userMapper.updateById(user);//user要设置id哦,具体的在下边我会详细介绍
// 查询 User
User exampleUser = userMapper.selectById(user.getId());
// 查询姓名为‘张三’的所有用户记录
List userList = userMapper.selectList(
new EntityWrapper().eq(“name”, “张三”)
);
// 删除 User
result = userMapper.deleteById(user.getId());
方便吧?如果只使用mybatis可是要写4个SQL和4个方法喔,当然了,仅仅上边这几个方法还远远满足不了我们的需求,请往下看:
**
多条件分页查询:
**
Java代码 收藏代码
// 分页查询 10 条姓名为‘张三’、性别为男,且年龄在18至50之间的用户记录

/**等价于SELECT *
*FROM sys_user
*WHERE (name=‘张三’ AND sex=0 AND age BETWEEN ‘18’ AND ‘50’)
*LIMIT 0,10
*/
下边这个,多条件构造器。其实对于条件过于复杂的查询,笔者还是建议使用原生mybatis的方式实现,易于维护且逻辑清晰,如果所有的数据操作都强行使用MP,就失去了MP简化开发的意义了。所以在使用时请按实际情况取舍,在这里还是先介绍一下。

条件构造一(上边方法的entityWrapper参数):

条件构造二(同上):
int buyCount = selectCount(Condition.create()
.setSqlSelect(“sum(quantity)”)
.isNull(“order_id”)
.eq(“user_id”, 1)
.eq(“type”, 1)
.in(“status”, new Integer[]{0, 1})
.eq(“product_id”, 1)
.between(“created_time”, startDate, currentDate)
.eq(“weal”, 1));
自定义条件使用entityWrapper:
List selectMyPage(RowBounds rowBounds, @Param(“ew”) Wrapper wrapper);
SELECT * FROM user ${ew.sqlSegment} *注意:此处不用担心SQL注入,MP已对ew做了字符串转义处理。 其实在使用MP做数据CURD时,还有另外一个方法,AR(ActiveRecord ),很简单,让我们的实体类继承MP提供Model<?>就好了,这和我们常用的方法可能会有些不同,下边简单说一下吧:*
//实体类
@TableName(“sys_user”) // 注解指定表名
public class User extends Model {
… // fields
… // getter and setter
/** 指定主键 */
@Override
protected Serializable pkVal() { //一定要指定主键哦
return this.id;
}
}
下边就是CURD操作了:
// 初始化 成功标识
boolean result = false;
// 初始化 User
User user = new User();
// 保存 User
user.setName(“Tom”);
result = user.insert();
// 更新 User
user.setAge(18);
result = user.updateById();
// 查询 User
User exampleUser = t1.selectById();
// 查询姓名为‘张三’的所有用户记录
List userList1 = user.selectList(
new EntityWrapper().eq(“name”, “张三”)
);
// 删除 User
result = t2.deleteById();
// 分页查询 10 条姓名为‘张三’、性别为男,且年龄在18至50之间的用户记录
List userList = user.selectPage(
new Page(1, 10),
new EntityWrapper().eq(“name”, “张三”)
.eq(“sex”, 0)
.between(“age”, “18”, “50”)
).getRecords();
就是这样了,可能你会说MP封装的有些过分了,这样做会分散数据逻辑到不同的层面中,难以管理,使代码难以理解。其实确实是这样,这就需要你在使用的时候注意一下了,在简化开发的同时也要保证你的代码层次清晰,做一个战略上的设计或者做一个取舍与平衡。
**
其实上边介绍的功能也不是MP的全部啦,下边介绍一下MP最有意思的模块——代码生成器。
**
步骤↓:
如上边所说,使用代码生成器一定要引入velocity-engine-core(模板引擎)这个依赖。
准备工作:
选择主键策略,就是在上边最开始时候我介绍MP配置时其中的这项配置,如果你不记得了,请上翻!MP提供了如下几个主键策略: 值 描述
IdType.AUTO 数据库ID自增
IdType.INPUT 用户输入ID
IdType.ID_WORKER 全局唯一ID,内容为空自动填充(默认配置)
IdType.UUID 全局唯一ID,内容为空自动填充
MP默认使用的是ID_WORKER,这是MP在Sequence的基础上进行部分优化,用于产生全局唯一ID。
表及字段命名策略选择,同上,还是在那个配置中。下边这段复制至MP官方文档:
在MP中,我们建议数据库表名采用下划线命名方式,而表字段名采用驼峰命名方式。
这么做的原因是为了避免在对应实体类时产生的性能损耗,这样字段不用做映射就能直接和实体类对应。当然如果项目里不用考虑这点性能损耗,那么你采用下滑线也是没问题的,只需要在生成代码时配置dbColumnUnderline属性就可以。
建表(命名规则依照刚才你所配置的,这会影响生成的代码的类名、字段名是否正确)。
执行下边的main方法,生成代码:
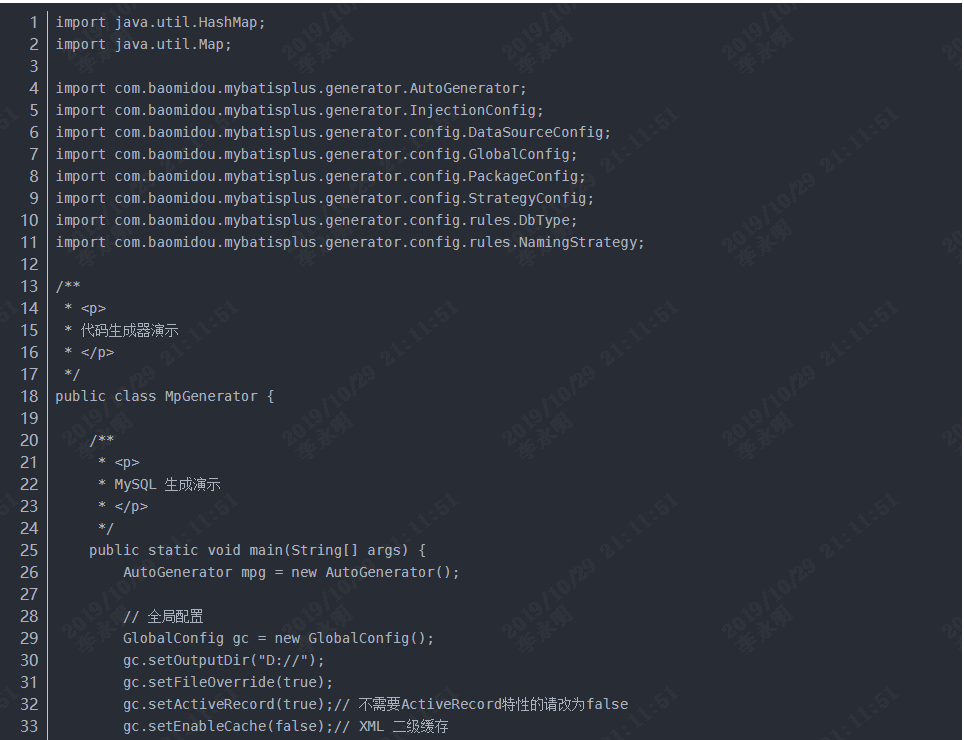


说明:中间的内容请自行修改,注释很清晰。
成功生成代码,将生成的代码拷贝到你的项目中就可以了,这个东西节省了我们大量的时间和精力!
下边我将介绍MP提供的很有意思的插件: 分页插件:插件的配置请看上边开篇时的MP配置部分。
public interface UserMapper{//可以继承或者不继承BaseMapper
/**
*
* 查询 : 根据state状态查询用户列表,分页显示
*
*
* @param page
* 翻页对象,可以作为 xml 参数直接使用,传递参数 Page 即自动分页
* @param state
* 状态
* @return
*/
List selectUserList(Pagination page, Integer state);
}
public Page selectUserPage(Page page, Integer state) {
page.setRecords(userMapper.selectUserList(page, state));
return page;
}
SELECT * FROM user WHERE state=#{state}
*乐观锁插件:当要更新一条记录的时候,希望这条记录没有被别人更新过。 其实原理很简单:
**
取出记录时,获取当前version
更新时,带上这个version
执行更新时, set version = yourVersion+1 where version = yourVersion
如果version不对,就更新失败
插件的配置请看上边开篇时的MP配置部分,使用该插件的表必须拥有能够作为version的字段,比如update_date:
Java代码 收藏代码
public class User {

}
说明:version仅支持int,Integer,long,Long,Date,Timestamp类型。
Java代码 收藏代码
int id = 100;
int version = 2;
User u = new User();
u.setId(id);
u.setVersion(version);
u.setXXX(xxx);
if(userService.updateById(u)){
System.out.println(“Update successfully”);
}else{
System.out.println(“Update failed due to modified by others”);
}
//等价于:update tbl_user set name=‘update’,version=3 where id=100 and version=2;
*执行分析插件,作用是分析处理 DELETE UPDATE 语句, 防止小白或者恶意 delete update 全表操作,不推荐生产环境使用。具体配置请看上边开篇时的MP配置部分。
性能分析插件,用于输出每条 SQL 语句及其执行时间,不推荐生产环境使用。具体配置请看上边开篇时的MP配置部分。
xml热加载插件,具体配置请看上边开篇时的MP配置部分。
**
以下是注解说明,摘自官方文档: 注解说明**
表名注解 @TableName
com.baomidou.mybatisplus.annotations.TableName
值 描述
value 表名( 默认空 )
resultMap xml 字段映射 resultMap ID
主键注解 @TableId
com.baomidou.mybatisplus.annotations.TableId
值 描述
value 字段值(驼峰命名方式,该值可无)
type 主键 ID 策略类型( 默认 INPUT ,全局开启的是 ID_WORKER )
暂不支持组合主键
字段注解 @TableField
com.baomidou.mybatisplus.annotations.TableField
值 描述
value 字段值(驼峰命名方式,该值可无)
el 详看注释说明
exist 是否为数据库表字段( 默认 true 存在,false 不存在 )
strategy 字段验证 ( 默认 非 null 判断,查看 com.baomidou.mybatisplus.enums.FieldStrategy )
fill 字段填充标记 ( FieldFill, 配合自动填充使用 )
字段填充策略 FieldFill
值 描述
DEFAULT 默认不处理
INSERT 插入填充字段
UPDATE 更新填充字段
INSERT_UPDATE 插入和更新填充字段
序列主键策略 注解 @KeySequence
com.baomidou.mybatisplus.annotations.KeySequence
值 描述
value 序列名
clazz id的类型
乐观锁标记注解 @Version
com.baomidou.mybatisplus.annotations.Version
排除非表字段、查看文档常见问题部分!
总结:MP的宗旨是简化开发,但是它在提供方便的同时却容易造成代码层次混乱,我们可能会把大量数据逻辑写到service层甚至contoller层中,使代码难以阅读。凡事过犹不及,在使用MP时一定要做分析,不要将所有数据操作都交给MP去实现。毕竟MP只是mybatis的增强工具,它并没有侵入mybatis的原生功能,在使用MP的增强功能的同时,原生mybatis的功能依然是可以正常使用的