在上一篇文章中,已经解决了如何获取html table结构的问题。在本篇文章中,我们着力于table结构的解析。
Html table的结构我们大家都很熟悉,那么在另一端如何构造一个结构,让Excel可以很好的接受和处理呢?
直观的看,一个完整Excel的内容是由位于各个单元格(Cell)中的内容组合而成的。而每个单元格(Cell)都有相应X、Y坐标来标示其位置。也就是说,一个Excel文件实质上就是许多Cell构成的集合,每个Cell用坐标属性确定位置,用内容属性存储内容。
基于此,我设计了最基本的Cell结构:
◆ X坐标
◆ Y坐标
◆ 合并列情况
◆ 合并行情况
◆ 内容
构成Excel的最基本的结构已经确定,下一步摆在我们面前的就是将html table转化为Excel Cell集合。
Html table中的每个td节点对应一个Excel单元格,其内容不必说,行、列的合并情况也自可由td的rowspan、colspan属性得出,转化的关键点就在于由table的tr td结构定位Excel单元格位置,即X、Y坐标。
Y坐标容易确定,即td所在tr的行数。至于一td的X坐标,其要受到两方面因素的影响:与该td同处一tr,但位于其之前(反映在表格视觉上即其左侧td)td的占位情况和该td所在tr的之前tr中某些td的跨行情况。
基于此种考虑,定位td的X坐标需经过两个过程的推导:用于处理左侧td占位影响的横向推导(Horizontal Deduction)和处理之前行跨行td影响的纵向推导(Vertical Deduction)。
以下图所示table为例,展示两次推导过程。
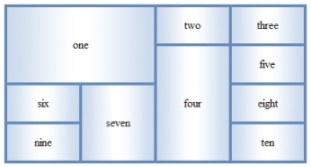
横向推导(Horizontal Deduction)
一次横向推导(Horizontal Deduction)限定在一tr范围内。整个过程基于递归的原理,递归模型如下:

核心代码为:
2 {
3 HtmlNode hnPreviousSibling = phnTd.PreviousSibling;
4 while (hnPreviousSibling != null && hnPreviousSibling.Name != phnTd.Name)
5 {
6 hnPreviousSibling = hnPreviousSibling.PreviousSibling;
7 }
8
9 if (hnPreviousSibling != null)
10 {
11 int nColSpan = hnPreviousSibling.GetAttributeValue("colspan", 1);
12 return HorizontalDeduction(hnPreviousSibling) + nColSpan;
13 }
14
15 return 0;
16 }
经过横向推导,各td的X、Y坐标如下图所示:
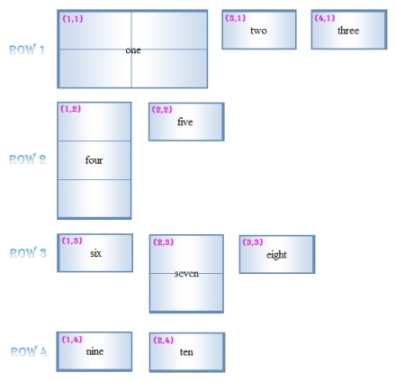
纵向推导(Vertical Deduction)
一次纵向推导的过程可以描述为(当前推导td用A表示):
找到A之前的行tr中与A具有相同X坐标的td节点B
if (B.rowspan>(A.Y-B.Y))
{
X+=B.colspan,即A的X坐标向后推B.colspan的位置
同时,与A同处一tr但在其后边的td节点均应向后推B.colspan个位移
}
对td节点A反复执行这样的一个过程,直到确定A无需再次移动。
纵向推导核心代码为:
2
3 do
4 {
5 int nComparedItemIndex = -1;
6 for (int j = i - 1; j >= 0; j--)
7 {
8 if (plstCells[j]._nStartX == oCurrentCell._nStartX)
9 {
10 nComparedItemIndex = j;
11 break;
12 }
13 }
14
15 if (nComparedItemIndex >= 0)
16 {
17 if (plstCells[nComparedItemIndex]._nRowSpan > (oCurrentCell._nStartY - plstCells[nComparedItemIndex]._nStartY))
18 {
19 oCurrentCell._nStartX += plstCells[nComparedItemIndex]._nColSpan;
20
21 bActedPush = true;
22
23 for (int k = i + 1; k < plstCells.Count; k++)
24 {
25 if (plstCells[k]._nStartY == oCurrentCell._nStartY)
26 {
27 plstCells[k]._nStartX += plstCells[nComparedItemIndex]._nColSpan;
28 }
29 }
30 }
31 else
32 {
33 bActedPush = false;
34 }
35 }
36 else
37 {
38 bActedPush = false;
39 }
40 }
41 while (bActedPush);
以示例table中的four td为例,其经过纵向推导过程后的坐标位置情况如下图:
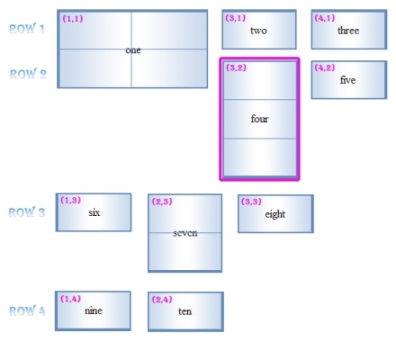
关于示例代码的几点说明:
1、 在示例代码中,我通过一个Config文件对生成的Excel的文件名、其内报表的内容和位置做了一些控制。基本内容如下:
<BaseInfo>
<FileName>Sample Excel File</FileName> <!--生成Excel的文件名-->
<SheetCount>1</SheetCount> <!--Excel中sheet的数量-->
</BaseInfo>
<Tables>
<ExcelTable>
<TableName>示例表一</TableName> <!--报表名称-->
<WhichSheet>1</WhichSheet> <!--所在sheet的序号-->
<StartX>2</StartX> <!--左上角X坐标-->
<StartY>2</StartY> <!--左上角Y坐标-->
<Source>Sample_Page_1.aspx</Source> <!--table所在页面-->
</ExcelTable>
</Tables>
</ExcelDocument>
2、 在解析html的过程中,我使用了HtmlAgilityPack解析工具。感兴趣的朋友可以研究一下。地址是这里:http://htmlagilitypack.codeplex.com/。
3、 HtmlAgilityPack解析html的过程中,其将html标签之间的空隙也会看成是一个节点,为内容为空字符串的文本节点,这点大家应注意。
4、 该示例代码基本上是一个完整的功能,并且和系统中其他模块耦合度很小。有类似需求的朋友可以拿来直接用。
附示例代码:ExcelGenerator.rar