
其中的fsimage 称为时点备份,又叫磁盘镜像快照,这个是NameNode的一个
持久化的方式之一:缺点,在内存数据序列化的时候比较慢
具体的过程:因为我们所知道的NameNode一般是存储在内存中的,并没有和磁盘进行交互,这和redis这类的非关系型数据库差不多,但是内存中的数据总是没有持久化的,那么怎么去持久化呢?就比如我们的NameNode结点数据的持久化过程:先将内存中的数据序列化为二进制字节流,之后将其通过IO的形式存入到计算机的文件系统中,就完成了持久化的过程,具体的如果NameNode需要数据的过程的时候,需要将外存中的字节码文件,反序列化,之后加载到内存中,就可以供NameNode使用了
注意点:时点快照:只会按规定的间隔一段时间之后再去持久化到外存中,如13点,15点,17点。。。。而不是每一秒都在进行持久化,因为这样的话又会频繁的和外存也就是磁盘进行交互,这样数据的获取的时间就会很长了

持久化的方式之二:缺点,在数据存入外存的过程不慢,但是当存外存恢复到内存的时候比较慢
edits记录对metadata的操作日志。。。>Redis
即日志编辑方式:1)数据存入外村会将客户端对服务器中的任何的一条指令都写入到操作日志log这个文件当中 2)数据从外存加载到内存中:直接再执行一遍log中的指令即可。
此方式也是时隔一段规定的时间才回去持久化,而不是实时的
********Hadoop集群中NameNode的信息一般的是将这两个结合起来持久化的
下面是具体的持久化 的过程:
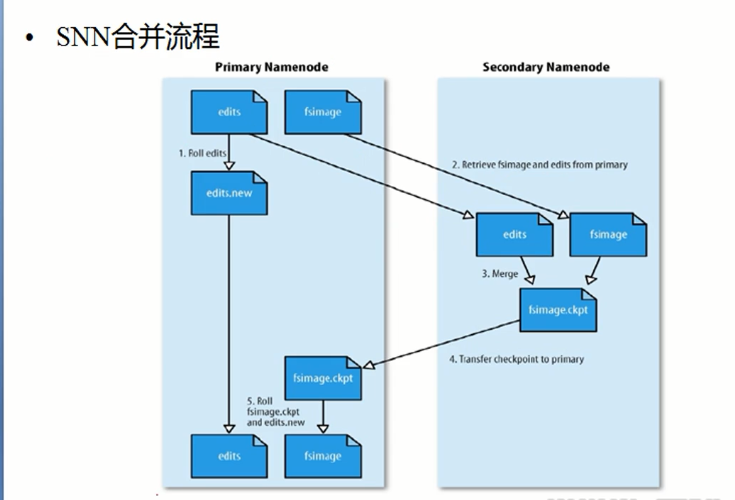
但是怎么去将这两种方式结合起来使用呢?首先先要理解fsimage文件和edits文件的产生的时候,对于fsimage文件是产生于搭建hadoop集群系统的时候,此时产生的文件是空的。edits的产生时机:集群启动的时候,会产生一个edits log文件,此时的文件也是空的,之后启动完毕之后,log文件会和fsimage文件进行合并,之后log一直会增大,因为集群启动之后,客户端会不断的通过NameNode实时的向集群发送指令,这都会记录到log文件中,这个时候 所带来的问题:log文件一直会增大,所以此时更不能通过edits进行恢复数据了,时间会很长,所以hadoop会通过SecondNameNode有时对edits和fsimage文件进行合并
SecondaryNameNode概念:并不是nameNode的备份,而仅仅是为了合并fsimage文件和log文件出现的这个

具体的合并过程
刚刚集群搭建完毕之后:生成了一个空的fsimage,之后启动了系统之后,就会产生一个fsimage文件,之后客户端对NameNode进行发送指令记录在edits中,所以edits会变大,但是通过第二主节点的检查,当edits达到一定的大小之后,便不会让他继续的去记录指令了,NameNode就会将所在结点(也就是主结点)edits传输至第二主节点进行合并处理,同时主结点的edits会清空,为了以后再次接受指令记录的时候仍然从0的大小开始增长。合并之后会发送给NameNode,将原有的主结点中的fsimage进行替代,之后主结点中的那个edits会从新的开始记录客户端发送的指令,之后整个此过程重复即可。但是这个是hadoop1.0时候的持久化的NameNode数据处理机制。在2.x版本之后,这个SecondaryNameNode就消失了
DataNode学习理解
